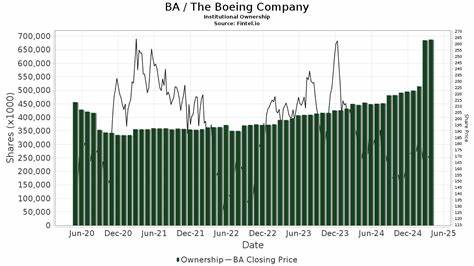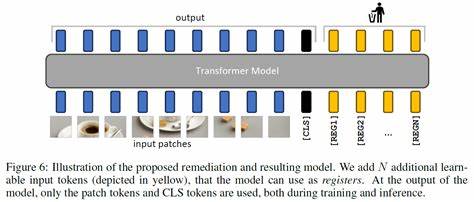
Vision Transformers (ViTs) haben in den letzten Jahren die Landschaft des maschinellen Sehens revolutioniert. Diese Architektur, ursprünglich aus dem Natural Language Processing (NLP) stammend, hat sich als äußerst leistungsfähig erwiesen, wenn es darum geht, visuelle Daten zu analysieren und komplexe Bildrepräsentationen zu lernen. Trotz ihrer beeindruckenden Fähigkeiten leiden ViTs jedoch unter einem bislang wenig beachteten Problem, das sich in Form von Artefakten in den erzeugten Feature-Maps manifestiert. Diese Herausforderung wurde durch eine aktuelle Studie unter dem Titel „Vision Transformers Need Registers“ umfassend untersucht und adressiert. Die Autoren der Studie – Timothée Darcet, Maxime Oquab, Julien Mairal und Piotr Bojanowski – zeigen, dass in Vision Transformer Netzwerken während der Inferenz sogenannte hochnormige Tokens vor allem in Bereichen mit wenig informativer Hintergrundstruktur auftreten.
Diese Tokens sind nicht bloß zufällige Ausreißer, sondern dienen dem internen Netzwerk dazu, Berechnungen durchzuführen, wirken jedoch gleichzeitig als Artefakte, die das eigentliche Verständnis des Bildes verzerren können. Sie erschweren somit den Einsatz von ViTs in nachfolgenden Bildverarbeitungsaufgaben, insbesondere wenn genaue und konsistente Feature- und Aufmerksamkeitskarten benötigt werden. Um das Problem zu beheben, schlägt das Forscherteam eine elegante und pragmatische Lösung vor: die Einführung zusätzlicher Tokens in die Eingabesequenz des Vision Transformers, die explizit diese interne Registerfunktion übernehmen. Diese sogenannten „Register-Tokens“ fungieren als Puffer oder Speicher, die die Reservierung von Rechenschritten und das Handling dieser hochnormigen Tokens übernehmen. Dieser Ansatz führt zu einer Verbesserung der Stabilität der internen Repräsentationen und beseitigt die zuvor beobachteten Störeffekte.
Die positive Wirkung dieses Konzepts wurde sowohl bei überwachten als auch bei selbstüberwachten ViT-Modellen empirisch nachgewiesen. Insbesondere Selbstüberwachungsmodelle profitieren von der Einführung der Register-Tokens stark. In den Tests erzielte die Methode nicht nur eine vollständigere Entfernung der schädlichen Artefakte, sondern auch einen neuen Stand der Technik bei dichten visuellen Vorhersageaufgaben. Dies umfasst anspruchsvolle Szenarien wie semantische Segmentierung, Objekterkennung und Bildgenerierung, in denen präzise und robuste Feature-Darstellungen unerlässlich sind. Die Verbesserung der Qualität der Feature- und Aufmerksamkeitskarten hat weitreichende Auswirkungen.
Sie ermöglicht es beispielsweise, dass größere Modelle effektiver genutzt werden können, wodurch fortschrittliche Objekterkennungsmethoden erstmals mit diesem erweiterten Architekturansatz realisierbar werden. Besonders im Bereich der Objektdiskoverierung – der automatischen Erkennung und Abgrenzung von Objekten in Bildern ohne manuelle Annotation – eröffnen die Register-Tokens ganz neue Chancen und fördern die Skalierung der Modelle auf komplexere Aufgabenstellungen. Ein weiterer bemerkenswerter Vorteil des Register-Konzepts liegt in der Glättung der Feature- und Aufmerksamkeitskarten. Dies führt zu einer verbesserten Interpretierbarkeit der Modelle, was für Anwendungen, die auf Transparenz und Erklärbarkeit angewiesen sind, von großer Bedeutung ist. Gerade bei sensiblen Anwendungen in der Medizin, der autonomen Mobilität oder in sicherheitskritischen Bereichen gewinnen die verbesserten Modellinterpretationen kontinuierlich an Bedeutung.
Die Erkenntnisse aus der Studie „Vision Transformers Need Registers“ erweitern das Verständnis für die internen Dynamiken von ViTs und verknüpfen Architekturdesign mit einer präziseren Repräsentation visueller Daten. Die Einführung zusätzlicher Tokens, die spezifisch zur Aufnahme und Handhabung überschussiger Informationsanteile verwendet werden, stellt eine konzeptionelle Neuerung dar, die das Potenzial hat, das Leistungsniveau von ViTs nachhaltig zu heben. Darüber hinaus sprechen die Forscher eine wichtige allgemeine Empfehlung für die weitere Entwicklung von Vision Transformers aus. Während frühere Arbeiten vor allem auf die Verbesserung der Trainingsstrategien, die Optimierung von Attention-Mechanismen und die Erweiterung der Modelltiefe fokussiert waren, zeigt sich hier, dass auch minimal-invasive strukturelle Modifikationen elementar zum Erfolg beitragen können. Das Register-Prinzip könnte künftig als eine Art Paradigma bei der Modellarchitektur dienen und analog zu Speicherregistern in klassischen Computerprozessoren verstanden werden, die speziell zur Steuerung und Organisation von Berechnungen eingesetzt werden.
Nicht zuletzt beeinflusst die vorgestellte Methode auch die Entwicklungsentscheidungen für Forschung und Industrie gleichermaßen. Von Start-ups, die an Echtzeit-Visualisierung und Bildverarbeitung arbeiten, bis hin zu großen Technologieunternehmen, die selbstüberwachte Modelle in Produktsysteme integrieren, bietet die Lösung einen pragmatischen Ansatz zur Qualitätssteigerung ohne teure Rechen- oder Datenressourcen. Die Integration von Register-Tokens fordert Entwickler aber auch heraus, da sie das bestehende Design und die Trainingspipeline von ViTs modifiziert. Ferner ist die optimale Anzahl und Positionierung der Register-Tokens bislang ein Bereich, der weiterer Forschung bedarf, um die ideale Balance zwischen Modellkomplexität und Leistungssteigerung zu finden. Dennoch scheint die Richtung klar: Mit gezielten Anpassungen, die die internen Berechnungen der Transformer besser erfassen und organisieren, lassen sich wichtige Verbesserungen erzielen.
Insgesamt markiert die Einführung der Register für Vision Transformers einen bedeutsamen Schritt in der Evolution maschineller Sehverfahren. Mit dieser Innovation wird nicht nur das Problem nachweisbarer Artefakte adressiert, sondern auch der Weg für neue Anwendungsfelder und effizientere Verarbeitungstechniken geebnet. Visuelle Modelle werden dadurch robuster, interpretierbarer und vielseitiger einsetzbar. Für die Zukunft der Bildverarbeitung und der künstlichen Intelligenz öffnet sich damit ein neues Kapitel, das sowohl Wissenschaftler als auch Praktiker gleichermaßen inspiriert.