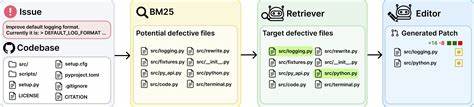
In der schnelllebigen Welt der Softwareentwicklung gewinnt die Automatisierung durch Künstliche Intelligenz (KI) zunehmend an Bedeutung. Besonders große Sprachmodelle, sogenannte Large Language Models (LLMs), zeigen vielversprechende Fähigkeiten bei der Unterstützung von Entwicklerinnen und Entwicklern. Doch um die tatsächliche Leistungsfähigkeit und praktische Anwendbarkeit dieser Modelle zu beurteilen, benötigt es realitätsnahe, umfangreiche und vielfältige Testdaten. Genau hier setzt SWE-rebench an – ein hochskalierbares Benchmarking-Datenset mit über 21.000 offenen Software-Engineering-Aufgaben aus echten Projekten.
SWE-rebench ist eine Weiterentwicklung und Erweiterung des Vorgängerdatasets SWE-bench, das bereits wichtige Impulse für die KI-basierte Programmierunterstützung lieferte. Nun ermöglicht die verfeinerte und automatisierte Pipeline von SWE-rebench die kontinuierliche Extraktion und Validierung von interaktiven Software-Engineering-Aufgaben aus Tausenden von Python-Repositorien auf GitHub. Solche Aufgaben sind nicht nur thematisch vielfältig, sie besitzen zudem eine echte Verbindung zu praktischen Problemlösungen, da sie aus Issue-Pull-Request-Paaren stammen und durch automatisches Setup und Testlauf auf Korrektheit geprüft wurden. Eine der zentralen Stärken von SWE-rebench ist die umfassende Automatisierung des Aufgabensammelprozesses. Während frühere Datensets oft manuelle oder halbautomatische Extraktionsmethoden verwendeten, erlaubt das von den Forschenden entwickelte System die fortlaufende, zuverlässige und großflächige Sammlung neuer Aufgaben aus aktuell betriebenen und maintainten Open-Source-Projekten.
Dabei werden alle Schritte – vom Einrichten der Entwicklungskonfiguration bis hin zum Ausführen der Tests – unter Aufsicht intelligenter Validierungskomponenten unterstützt. Dadurch wird sichergestellt, dass jede Aufgabe voll funktionsfähig und anschlussfähig an realitätsgetreue Software-Workflows ist. Darüber hinaus hebt SWE-rebench den Anspruch an die Qualität der Daten durch eine ausgeklügelte Annotation hervor. Automatisch generierte Qualitätsscores bewerten nicht nur den Schwierigkeitsgrad der Aufgaben, sondern auch die Klarheit des Problemstatements und die Gültigkeit der zugehörigen Test-Patches. Diese Metadaten helfen Forschenden und Entwickelnden, gezielt anspruchsvolle oder einfache Aufgaben auszuwählen oder nur jene Beispiele zu nutzen, die den eigenen Vorstellungen von Zuverlässigkeit und Verständlichkeit entsprechen.
Ein weiterer wichtiger Vorteil dieser Benchmark ist die Bereitstellung vollständiger Umgebungsinstallationsanweisungen, die von KI-Modellen erzeugt und automatisiert geprüft wurden. Während viele Datensets lediglich den Quellcode und die Tests bereitstellen, funktioniert SWE-rebench einen Schritt weiter: Jeder Task enthält eine reproduzierbare Umgebungskonfiguration, inklusive Paketabhängigkeiten und Installationstipps, die direkt im Testframework genutzt werden können. So lässt sich ein gesamter Workflow vom Setup bis zum erfolgreichen Testlauf auf die Effizienz und Korrektheit von KI-gestützten Lösungsansätzen überprüfen. Für Praktiker und Forschungsgemeinschaften eröffnet SWE-rebench vielfältige Anwendungsperspektiven. Entwickelnde großer LLM-Modelle bekommen damit eine aussagekräftige Grundlage, um die Fortschritte ihrer Systeme anhand realer Programmierprobleme objektiv zu messen.
Dies trägt dazu bei, Modelle gezielt auf praxisrelevante Probleme zu trainieren, mögliche Schwachstellen zu entdecken und neue Fähigkeiten zu testen – etwa im Bereich automatisierter Bugfixes, Refactorings, Dokumentationsanalysen oder Umgebungswartung. Darüber hinaus bietet das Datenset Potenzial für Benchmarking-Wettbewerbe und den Aufbau von Leaderboards, die den Fortschritt im Bereich Software-Engineering-KI transparent machen. Die kontinuierliche Erweiterung der Aufgabe erlaubt zudem eine aktuelle Anpassung an moderne Softwareentwicklungstrends und Veränderung der Code-Ökosysteme. Ein weiterer Punkt, der SWE-rebench von anderen Distanzierungsansätzen abhebt, ist die Rücksichtnahme auf Lizenzbedingungen. Da die Aufgaben aus offenen Repositorien stammen, sind die jeweiligen Lizenzen der Quellcodes dokumentiert, was eine ethisch korrekte Nutzung und Wiederveröffentlichung der Daten ermöglicht.
Dies erleichtert die Einhaltung rechtlicher Rahmenbedingungen in Forschungs- und Industrieprojekten. Auf der technischen Seite lassen sich SWE-rebench-Aufgaben mittels Python-Datasets direkt über das populäre Hugging Face Ökosystem laden und verarbeiten. Die Daten liegen in effizienten Parquet-Formaten vor, die schnellen Zugriff und einfache Integration erlauben. Dadurch können verschiedenste KI-Workflows von Trainingspipelines, über Evaluationsskripte bis hin zu interaktiven Agenten mit minimalem Aufwand auf der Grundlage der SWE-rebench-Aufgaben aufgebaut werden. Zusammengefasst ist SWE-rebench eines der umfangreichsten und methodisch hochwertigsten Datensets für die Entwicklung und Evaluierung von Software-Engineering-Lösungen mit KI.
Durch die hochautomatisierte Aufgabensammlung aus realen Open-Source-Projekten, die sorgfältige Validierung und Annotation sowie die Bereitstellung von reproduzierbaren Testumgebungen liefert es einen einzigartigen Werkzeugkasten für die Verbesserung von LLM-basierten Agenten in der Softwareentwicklung. Da Software Engineering immer stärker von der Unterstützung durch KI geprägt wird, ist SWE-rebench ein entscheidendes Hilfsmittel, um den nächsten Schritt in Richtung zuverlässiger und produktiver KI-gestützter Tools für Codeschreiber zu gehen. Die Kombination aus Menge, Vielfalt und Qualität der Aufgaben macht es Forschenden und Entwickelnden gleichermaßen leicht, innovative Techniken zu testen und den Weg zur praxistauglichen Automation im Software Engineering zu ebnen. SWE-rebench ist damit ein unverzichtbarer Baustein für die Zukunft intelligenter Softwareentwicklung und trägt dazu bei, das Potenzial großer Sprachmodelle gezielt und sicher nutzbar zu machen.