In den letzten Jahren haben Foundation Models, namentlich große Sprachmodelle (Large Language Models, LLMs), die Landschaft der künstlichen Intelligenz nachhaltig geprägt. Diese Modelle sind in der Lage, eine Vielzahl komplexer Textaufgaben zu bewältigen, von der automatischen Texterstellung über Übersetzungen bis hin zu komplexen logischen Schlussfolgerungen. Trotz ihrer universellen Einsetzbarkeit stoßen sie jedoch häufig auf die Notwendigkeit, sich speziell an individuelle Anwendungsfälle anzupassen. Traditionell geschieht dies durch aufwändiges Fine-Tuning, das sowohl zeitintensiv als auch ressourcenhungrig ist. Hier setzt ein bahnbrechender Ansatz namens Text-to-LoRA (T2L) an, der die Anpassung von Transformern auf eine neue Art und Weise ermöglicht: schnell, effizient und intuitiv per natürlicher Spracheingabe.
Die Herausforderung bei der Nutzung großer Sprachmodelle liegt darin, dass sie bei spezifischen Aufgaben oft nicht die optimale Performance erzielen, ohne dass sie speziell dafür trainiert werden. Herkömmliche Methoden wie das Fine-Tuning benötigen umfangreiche, sorgfältig kuratierte Datensätze und erhebliche Rechenressourcen, was gerade für kleinere Institutionen oder Einzelanwender eine große Hürde darstellt. Darüber hinaus erfordern solche Anpassungen oft ein tiefes technisches Verständnis und die Wahl geeigneter Hyperparameter, was die Zugänglichkeit zusätzlich erschwert. Text-to-LoRA bietet genau hier eine innovative Lösung. Es handelt sich um ein Hypernetzwerk, das in der Lage ist, Low-Rank Adaptation (LoRA)-Adaptermodelle unmittelbar zu generieren – und zwar allein basierend auf einer natürlichen, sprachlichen Beschreibung der Zielaufgabe.
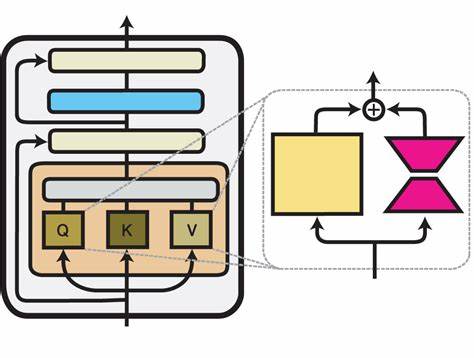
Anders als klassische Fine-Tuning-Verfahren, die viele Trainingszyklen beanspruchen, lässt sich mit T2L ein passender Adapter in nur einem einzigen kostengünstigen Vorwärtsdurchlauf konstruieren. Dies reduziert nicht nur den Rechenaufwand drastisch, sondern macht die Anpassung auch für eine breite Nutzerbasis leicht zugänglich. Die Funktionsweise von Text-to-LoRA beruht auf dem Training eines speziellen Hypernetzwerks auf einer Vielzahl vorgefertigter LoRA-Adapter, die unterschiedliche Aufgaben wie z.B. die Lösung von mathematischen Fragen (GSM8K) oder spezifische Textanalyseaufgaben abdecken.
Durch dieses Training lernt das Hypernetzwerk, basierend auf einer einfachen Textbeschreibung, neue Adapterinstanzen zu rekonstruieren, die in ihrer Performance den eigens trainierten, aufgabenbezogenen LoRA-Adaptern kaum nachstehen. Dabei ist T2L sogar in der Lage, mehrere hundert Adapter in komprimierter Form abzulegen und abzuspeichern, was die Speichernutzung optimiert. Besonders beeindruckend ist die Fähigkeit von T2L, auch völlig unbekannte Aufgaben, die während des Trainings nicht berücksichtigt wurden, im Zero-Shot-Modus zu adaptieren. Diese Fähigkeit zur GENERALISIERUNG ist ein entscheidender Vorteil für die Weiterentwicklung von Foundation Models. Nutzer müssen keine großen Datensätze mehr selbst zusammenstellen oder langwierige Trainingsprozesse durchlaufen.
Stattdessen genügt die Eingabe einer klar formulierten Aufgabenbeschreibung, und T2L liefert in Sekundenschnelle einen genau darauf zugeschnittenen Adapter. Dies demokratisiert die Spezialisierung von Grundlagenmodellen und senkt maßgeblich die technologischen Barrieren. Aus Sicht der praktischen Anwendung ergeben sich vielfältige Möglichkeiten. Unternehmen können mit minimalem Aufwand Sprachmodelle für spezifische interne oder kommerzielle Zwecke anpassen, ohne teure Trainingsinfrastrukturen vorhalten zu müssen. Forscher profitieren von der effizienten Erprobung neuer Anwendungsfelder, da sich Modelle schnell modifizieren und testen lassen.
Auch im Bildungsbereich oder bei der Entwicklung personalisierter KI-Assistenten kann Text-to-LoRA einen bedeutenden Mehrwert bieten, indem individuelle Anforderungen einfach verbalisiert und prompt umgesetzt werden. Die zunehmende Modularität und Adaptivität, die Text-to-LoRA ermöglicht, ist außerdem ein wichtiger Schritt hin zu nachhaltigeren KI-Systemen. Der drastisch reduzierte Rechenaufwand bedeutet auch eine deutliche Verringerung des Energieverbrauchs beim Training und der Anpassung von Modellen. Dadurch leistet diese Technologie einen Beitrag zur ökologischen Verträglichkeit von KI-Anwendungen, die bislang oft kritisiert wurden wegen ihres hohen Energiebedarfs. Ein weiterer interessanter Aspekt von Text-to-LoRA ist seine Rolle in der Weiterentwicklung von Hypernetzwerken selbst.
Hypernetzwerke, die andere Netzwerke generieren oder modifizieren, sind ein zukunftsträchtiges Feld innerhalb des maschinellen Lernens. T2L demonstriert eindrucksvoll, wie diese Konzepte praktisch eingesetzt werden können, um den oft starren Anpassungsprozess bei Deep Learning-Modellen zu flexibilisieren. Diese Innovationskraft könnte auch auf andere Bereiche der KI folgen, etwa bei der Bildverarbeitung, Robotik oder multimodalen Modellen. Nicht zuletzt steht mit dem öffentlichen Zugang zum Code von Text-to-LoRA einer breiten Community die Möglichkeit offen, die Technologie weiterzuentwickeln, zu überprüfen und kreativ einzusetzen. Open-Source-Initiativen haben sich immer wieder als Katalysatoren für Innovation bewährt, die auch der Verbreitung und Verbesserung von Forschungsergebnissen dienen.
Die Verfügbarkeit von T2L fördert somit auch die wissenschaftliche Kollaboration und den Austausch über bestmögliche Nutzungsstrategien. Rückblickend betrachtet bildet Text-to-LoRA ein Bindeglied zwischen der Komplexität großer Sprachmodelle und den Anforderungen der realen Anwendung. Wo bisher große technische Hürden die Anpassung an Spezialaufgaben erschwerten, öffnet sich nun eine Tür zur schnellen, einfachen und ressourcenschonenden Modellanpassung. Dies wird vermutlich einen breiten Einfluss auf die Zukunft der künstlichen Intelligenz haben, indem es die Transformationsprozesse vereinfacht und beschleunigt. Zusammengefasst ist Text-to-LoRA eine bahnbrechende Entwicklung, die zeigt, wie sich Transformer-Modelle auf eine Art und Weise spezialisieren lassen, die bisher als ineffizient oder uneinheitlich galt.
Die Möglichkeit, durch kurze natürliche Sprachbeschreibungen sofort maßgeschneiderte Adapter zu generieren, wird die Nutzung großer Sprachmodelle demokratisieren, den Zugang erleichtern und Ressourcen schonen. Diese Technologie hat das Potenzial, die Art und Weise, wie wir KI einsetzen und weiterentwickeln, grundlegend zu verändern. Es ist zu erwarten, dass Text-to-LoRA in den kommenden Jahren eine zentrale Rolle bei der Anpassung und Spezialisierung von Foundation Models in Forschung, Industrie und darüber hinaus einnehmen wird.