Transformer-Modelle haben die Welt der künstlichen Intelligenz revolutioniert und sind heute aus vielen Anwendungen nicht mehr wegzudenken. Insbesondere in der Sprachverarbeitung haben Standard-Transformer wie BERT und GPT beeindruckende Fortschritte ermöglicht. Doch neben den weit verbreiteten Standardvarianten entwickeln Forscher und Entwickler zunehmend ungewöhnliche Transformer-Modelle, die speziell darauf ausgelegt sind, bestimmte Schwächen zu überwinden oder neue Funktionen bereitzustellen. Ein Beispiel dafür sind nicht-autoregressive Transformer, die eine schnellere und effizientere Textgenerierung ermöglichen. Diese Modelle entfernen die strikte Abhängigkeit der Vorhersagen von vorherigen Token, was im Vergleich zu autoregressiven Ansätzen enorme Vorteile mit sich bringen kann.
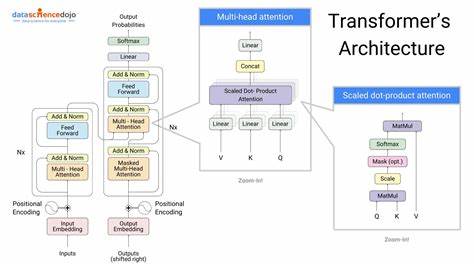
Die Implementierung solcher Modelle erfordert jedoch ein tiefes Verständnis der zugrunde liegenden Mechanismen und eine sorgfältige Anpassung der Architektur. Einer der wichtigsten Aspekte ungewöhnlicher Transformer-Modelle ist ihre Anpassungsfähigkeit. Während klassische Transformer häufig in Encoder-Decoder-Strukturen für Aufgaben wie maschinelle Übersetzung eingesetzt werden, zeigen neuere Varianten, wie etwa encoder-only-Modelle, dass allein der Encoder überraschend leistungsfähig sein kann, insbesondere bei Aufgaben der Textklassifikation oder Token-Tagging. Solche Modelle bieten Vorteile in der Trainingsgeschwindigkeit und Effizienz, da sie die Komplexität der Decoder-Struktur umgehen. Die Balance zwischen Architektur und Aufgabe ist hierbei entscheidend, um optimale Ergebnisse zu erzielen.
Die zugrundeliegenden Code-Implementierungen, die teilweise als Open Source verfügbar sind, ermöglichen es Entwicklern, diese ungewöhnlichen Modelle zu erkunden und anzupassen. Projekte, die besonderen Fokus auf nicht-autoregressive oder encoder-only Transformer legen, zeigen mitunter innovative Datenverarbeitungsstrategien und Trainingspipelines, die im Vergleich zu Standardmodellen neuartige Wege gehen. Dies fördert nicht nur die Weiterentwicklung der Modelle, sondern bietet auch praktische Vorteile im Bereich der Skalierbarkeit und Anpassbarkeit. Ein weiterer spannender Trend ist die Verwendung ungewöhnlicher Transformer-Modelle in Domains außerhalb der klassischen natürlichen Sprache. Beispielsweise finden sich Ansätze, die Transformers für Musikgenerierung, Bilderkennung oder sogar biologische Sequenzanalyse einsetzen.
Gerade hier zeigt sich, wie flexibel Transformer-Architekturen sind und wie durch Anpassung und kreative Neukombination verschiedene Problemstellungen adressiert werden können. Die Herausforderungen bei der Entwicklung ungewöhnlicher Transformer-Modelle sind jedoch nicht zu unterschätzen. Komplexe Trainingsdynamiken, das Fehlen etablierter Best Practices und oft fehlende Benchmarking-Daten erschweren die Evaluierung und Weiterentwicklung erheblich. Trotzdem treibt die offene KI-Community die Innovation voran, indem sie neue Modelle teilt, diskutiert und kontinuierlich optimiert. Nicht zuletzt bieten ungewöhnliche Transformer-Modelle Potenziale für eine breitere Nutzung durch Unternehmen und Entwickler.
Durch effizientere Architekturen und maßgeschneiderte Lösungen lassen sich Rechenkosten senken und neue Anwendungsfelder erschließen. Die Anpassungsfähigkeit der Transformer bleibt dabei der Schlüssel zu nachhaltigem Erfolg. Insgesamt lässt sich sagen, dass die Erforschung und Entwicklung ungewöhnlicher Transformer-Modelle ein vielversprechendes Feld darstellt, das sowohl technische Innovation als auch praktische Anwendung vereint. Während klassische Transformer-Modelle weiterhin eine wichtige Rolle spielen, werden speziell angepasste Varianten zunehmend an Bedeutung gewinnen und die KI-Landschaft nachhaltig prägen.