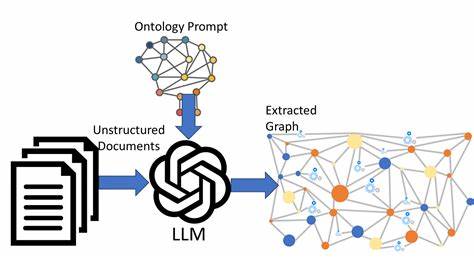
In der heutigen schnelllebigen Informationswelt gewinnt die Fähigkeit, Wissen effizient zu erfassen, zu strukturieren und zu visualisieren, immer mehr an Bedeutung. Besonders Unternehmen und Organisationen, die täglich eine Vielzahl von Dokumenten verwalten, stehen vor der Herausforderung, relevante Informationen nicht nur zu speichern, sondern auch in Echtzeit zu vernetzen und zugänglich zu machen. Hier kommt die Technologie der Wissensgraphen ins Spiel, die mit der Unterstützung von großen Sprachmodellen (LLM) neue Möglichkeiten erschließt. Wissensgraphen bieten eine strukturierte Darstellung von Informationen, indem sie Daten als vernetzte Entitäten und deren Beziehungen abbilden. Gerade bei der Verarbeitung umfangreicher Dokumentensammlungen können sie helfen, versteckte Zusammenhänge zu identifizieren, Wissen besser zu organisieren und den Zugang zu relevanten Inhalten deutlich zu erleichtern.
Die Integration von großen Sprachmodellen in den Prozess der Wissensgraph-Erstellung revolutioniert die Art und Weise, wie Dokumente analysiert und interpretiert werden. Sprachmodelle wie GPT-4 oder vergleichbare Modelle sind in der Lage, semantische Beziehungen zwischen Konzepten zu erkennen und natürlichsprachliche Inhalte zu verstehen, was manuell kaum realisierbar wäre. Durch den Einsatz dieser Modelle lassen sich aus unstrukturierten Texten strukturierte Beziehungen extrahieren und direkt in den Wissensgraph einspeisen, wodurch eine kontinuierliche und automatische Aktualisierung möglich wird. Eine der bedeutendsten Herausforderungen bei der Erstellung eines Wissensgraphen aus Dokumenten besteht darin, dynamisch mit den ständigen Änderungen und Erweiterungen der Quelldaten umzugehen. Traditionelle statische Systeme sind oft unflexibel und erfordern manuelle Eingriffe, um neue Informationen einzupflegen.
Hier setzt moderne Pipeline-Architektur an, die eine Echtzeit- oder nahezu Echtzeit-Verarbeitung erlaubt. Neue oder geänderte Dokumente werden automatisch erkannt, analysiert und in den Wissensgraphen eingebunden. So bleibt die Wissensbasis stets aktuell und zuverlässig. Ein Beispiel für eine solche Technologie ist CocoIndex, eine Plattform, die speziell für die Indizierung und Analyse von Dokumenten mit Unterstützung von LLMs entwickelt wurde. CocoIndex kombiniert verschiedene Komponenten, darunter Datenquellen, Sammelstellen für Daten (Collector), Transformationen mittels großer Sprachmodelle und die Speicherung beziehungsweise Visualisierung der Ergebnisse in Graph-Datenbanken wie Neo4j.
Diese nahtlose Integration macht es möglich, aus einer Dokumentensammlung wie technischer Dokumentationen, medizinischen Aufnahmen oder anderen textbasierten Quellen in wenigen Schritten einen umfassenden Wissensgraphen zu erstellen. Das grundlegende Datenmodell für den Wissensgraphen basiert auf Knoten und Kanten. Dabei stellen Knoten typischerweise Entitäten dar, etwa einzelne Dokumente oder identifizierte Konzepte (zum Beispiel Begriffe wie 'ETL', 'Datenverarbeitung' oder 'Patientenakte'). Kanten repräsentieren die Beziehungen zwischen diesen Entitäten, etwa "unterstützt", "erwähnt" oder "bezieht sich auf". In der Praxis bedeutet dies, dass Sätze aus Dokumenten wie "CocoIndex unterstützt inkrementelle Verarbeitung" automatisch als Beziehungsknotenpaar mit passenden Attributen im Wissensgraphen abgebildet werden.
Die Extraktion der Beziehungen erfolgt durch die Transformation des Dokumentinhalts mittels großer Sprachmodelle, die darauf trainiert sind, relevante Subjekt-Prädikat-Objekt-Strukturen zu erkennen. Dabei hilft eine klare Definition der Datenklassen, die die erwartete Struktur und Bedeutung der extrahierten Informationen festlegen. So wird sichergestellt, dass das Modell fokussiert auf tatsächliche Konzepte und deren Verknüpfungen eingeht und irrelevante Textteile wie Beispiele, Codeabschnitte oder Nebensätze überspringt. Nach der Extraktion fließen die Ergebnisse in sogenannte Collector ein, welche die gesammelten Entitäten, Beziehungen und Erwähnungen systematisch ordnen. Dies erleichtert nicht nur die spätere Verarbeitung, sondern auch das Mapping der Daten auf die Struktur der Graph-Datenbank.
Für die Speicherung und Visualisierung wird häufig Neo4j eingesetzt, eine etablierte Graph-Datenbank, die schnelle Abfragen komplexer Netzwerke erlaubt und mit intuitiven Benutzeroberflächen wie dem Neo4j Browser die Erkundung der Daten vereinfacht. Wichtig für den Erfolg eines Echtzeit-Wissensgraphen ist zudem die Fähigkeit, mit inkrementellen Aktualisierungen umzugehen. Wenn sich Dokumente ändern oder neue hinzukommen, sollen nicht der gesamte Graph neu aufgebaut werden, sondern nur die betroffenen Teile aktualisiert werden. Dies spart Ressourcen, erhöht die Reaktionsgeschwindigkeit und sorgt für eine stets aktuelle Wissensbasis. Die Kombination aus PostgreSQL für inkrementelle Verarbeitung und Neo4j als Graph-Datenbank bildet hier eine bewährte Architektur.
Neben der technischen Umsetzung spielt auch die Automatisierung eine entscheidende Rolle. Durch vordefinierte Pipelines, die mittels Skripten gestartet und verwaltet werden, lässt sich der Prozess der Datenaufnahme, Modellanwendung, Extraktion, Sammlung, Speicherung und Visualisierung komplett automatisieren. Nutzer können so mit minimalem Aufwand große Dokumentenmengen kontinuierlich in wertvolles Wissen umwandeln. Die Anwendungsmöglichkeiten sind vielfältig. In medizinischen Kontexten können automatisch Wissensgraphen aus Patientenakten oder medizinischen Studien generiert werden, um Zusammenhänge zwischen Symptomen, Diagnosen und Therapien zu erkennen.
In der Softwareentwicklung lassen sich Codebasen und zugehörige Dokumentationen analysieren, um Abhängigkeiten und Module verständlich darzustellen. Unternehmen profitieren durch eine verbesserte Produktrecherche, Wissensmanagement oder Empfehlungssysteme auf Basis semantischer Beziehungen. Darüber hinaus ermöglicht die Integration visueller Analysetools eine interaktive Exploration der Wissensgraphen. Dabei können Anwender durch Knoten und Kanten navigieren, komplexe Beziehungsnetzwerke untersuchen und so schneller fundierte Entscheidungen treffen. Insbesondere bei großen Datenmengen stellt dies einen erheblichen Mehrwert dar, da das Wissen nicht mehr isoliert, sondern im Kontext verstanden wird.








