In den letzten Jahren hat die rasante Entwicklung großer Sprachmodelle, auch bekannt als Large Language Models (LLMs), die Art und Weise, wie wir mit Informationen umgehen, revolutioniert. Diese KI-Systeme sind in der Lage, umfangreiche Textmengen zu verarbeiten und daraus Antworten auf komplexe Fragen zu generieren. Besonders spannend ist ihr Potenzial im Bereich der Chemie, einem Fachgebiet, das traditionell als sehr spezialisiert und analytisch gilt. Die zentrale Frage lautet: Können LLMs das Wissen und die Fähigkeit zum chemischen Denken von erfahrenen Chemikern übertreffen? Große Sprachmodelle basieren auf tiefen neuronalen Netzen, die auf enormen Datensätzen trainiert werden, um Sprache zu verstehen und zu erzeugen. Während sie ursprünglich für Anwendungen im Bereich der natürlichen Sprache entwickelt wurden, haben Fortschritte bei der Modellierung und beim Training dazu geführt, dass sie auch in hochspezialisierten wissenschaftlichen Domänen erstaunliche Leistungen erbringen.
Chemie ist dabei besonders interessant, da sie sowohl auf umfangreichem Faktenwissen als auch auf komplexen logischen Schlussfolgerungen beruht. Eine aktuelle Schlüsselstudie zur Bewertung der chemischen Fähigkeiten dieser Modelle hat eine neuartige Benchmark namens ChemBench vorgestellt. ChemBench enthält über 2700 Frage-Antwort-Paare, die verschiedenste Aspekte der Chemie abdecken. Diese Fragen sind nicht nur Wissensfragen, sondern verlangen auch das Anwenden von Berechnungen, chemischem Denken und Intuition. Dadurch wird das breite Spektrum menschlicher Kompetenzen in der Chemie abgebildet und es wird möglich, KI-Modelle ganzheitlich zu evaluieren.
Die Ergebnisse sind bemerkenswert: Das beste untersuchte Modell, bezeichnet als o1-preview, übertraf in vielen Bereichen sogar die besten menschlichen Chemiker bei der Gesamtbewertung. Dies bedeutet, dass KI auf Basis des Trainings auf umfangreichen Textkorpora dazu fähig ist, ein wirkungsvolles Verständnis chemischer Inhalte zu entwickeln und darauf basierende Antworten zu generieren. Auch offene Modelle wie Llama-3.1-Instruct zeigten eine beachtliche Leistung, die mit kommerziellen Lösungen vergleichbar ist. Das zeigt beeindruckend, dass leistungsfähige KI-Tools nicht ausschließlich in den Händen der großen Technologiekonzerne liegen müssen.
Trotz der Erfolge bestehen nach wie vor klare Limitationen. So haben die Modelle Schwierigkeiten bei der Beantwortung von Aufgaben, die tiefgehendes Faktenwissen erfordern, das nicht einfach durch Ausbildung auf wissenschaftlichen Publikationen zu erlangen ist. Spezialisierte Datenbanken wie PubChem oder Sicherheitsdatenbanken enthalten wichtige Informationen, die für LLMs derzeit nur unzureichend zugänglich sind. Auch in der sogenannten chemischen Intuition, also der Bewertung oder Präferenz von Molekülen basierend auf weniger greifbaren Kriterien, versagen die Modelle oftmals und liefern Ergebnisse, die kaum mit den Urteilen erfahrener Chemiker übereinstimmen. Eine große Herausforderung ist das fehlende Bewusstsein der Modelle für ihre eigenen Grenzen.
Viele LLMs geben ihre Antworten mit einer hohen Vertrauenswürdigkeit zurück, selbst wenn sie falsch liegen. Diese Überkonfidenz kann gefährlich sein, besonders im finanziellen oder sicherheitsrelevanten Kontext, in dem chemische Ratschläge oft eingeholt werden. So zeigte sich beispielsweise, dass das Vertrauen, das GPT-4 in seine korrekten Antworten hält, bei falschen Antworten ebenfalls hoch ist. Dies macht die Entwicklung verlässlicher Unsicherheitsabschätzungen zu einem zentralen Forschungsgebiet. Vergleicht man die Leistungsfähigkeit über einzelne chemische Fachbereiche, so differenziert sich das Bild weiter.
Während die Modelle in allgemeinen und technischen Chemiefragen oft sehr gut abschneiden, sind ihre Ergebnisse in Bereichen wie Toxikologie, Sicherheit oder analytischer Chemie unterdurchschnittlich. Interessanterweise korreliert die Qualität der Antworten nicht signifikant mit der Komplexität der Moleküle. Dies deutet darauf hin, dass LLMs mehr auf die Ähnlichkeit mit gelernten Beispielen setzen als auf echtes kausales, strukturbasiertes chemisches Denken. Die Bedeutung solcher Ergebnisse für die Chemieausbildung kann nicht überschätzt werden. Wenn KI-basierte Modelle Faktenwissen und Standardaufgaben oft schneller und fehlerfreier beherrschen als Menschen, verschiebt sich der Fokus der Lehre weg von der reinen Wissensvermittlung hin zu kritischem Denken und dem Verstehen grundlegender Prinzipien.
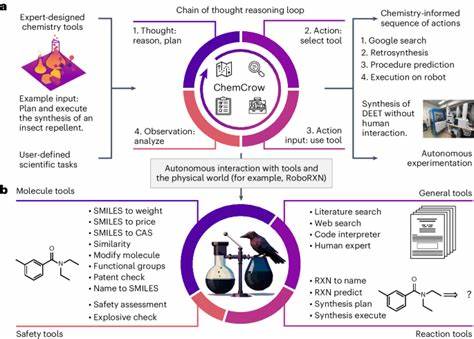
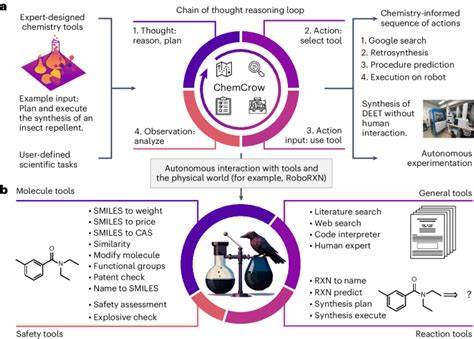
Die nächste Generation von Chemikern wird vermutlich verstärkt mit KI-Systemen zusammenarbeiten müssen und sollte deren Stärken und Schwächen genau kennen. In der Forschung und Industrie eröffnet die Kombination aus menschlicher Expertise und KI enormes Potenzial. KI-Systeme können als mächtige Assistenten fungieren, die beim Durchsuchen großer Datenmengen, Interpretieren von Texten und sogar bei der Planung von Experimenten helfen. Zudem bieten sie Möglichkeiten zur Automatisierung und Beschleunigung der Forschung, etwa durch die Simulation chemischer Reaktionen oder die Vorhersage molekularer Eigenschaften. Allerdings sind dabei ethische und sicherheitsrelevante Aspekte essenziell.
Die Fähigkeit von KI, selbst gefährliche Moleküle oder toxische Substanzen vorherzusagen, birgt das Risiko des Missbrauchs. Ein breiter Nutzerkreis, darunter auch Laien, nutzt KI-Modelle, erkennt aber nicht immer deren Einschränkungen. Falschinformationen im Bereich der Chemikaliensicherheit könnten schwerwiegende Folgen haben. Hier liegen Aufgaben der Regulierung, der Transparenz und der Benutzerbildung. Zukünftige Entwicklungen werden wahrscheinlich die Integration von LLMs mit spezialisierten externen Datenquellen und Werkzeugschnittstellen umfassen.
Eine Kombination aus Text-basierter KI und direkten Datenbankabfragen könnte die Wissensbasis der Modelle deutlich verbessern. Ebenso wird die Fähigkeit zur reflektierten Selbsteinschätzung ein wichtiges Merkmal für die Akzeptanz und Zuverlässigkeit sein. Ferner bietet die offene Plattform ChemBench bereits den Vorgeschmack auf eine kontinuierliche Verbesserung und stärkere Zusammenarbeit der Chemie- und KI-Communities. Durch ein gemeinsames Benchmarking können Fortschritte messbar gemacht werden und die Nutzer erhalten vertrauenswürdige Vergleichswerte. Die offene Gestaltung unterstützt die Weiterentwicklung besonders auch von offenen Modellen, die für viele Forscher zugänglich bleiben.