Die rasante Entwicklung im Bereich der Künstlichen Intelligenz basiert maßgeblich auf der Fähigkeit, komplexe neuronale Netzwerke zu trainieren. Traditionell gelten Backpropagation-Verfahren als Standard, um tiefen neuronalen Netzen das Lernen zu ermöglichen. Trotz ihrer Leistungsfähigkeit sind sie biologisch wenig plausibel und motivieren schon seit längerem die Suche nach alternativen Lernalgorithmen, die lokal und biologisch glaubwürdiger funktionieren. Eine solche Methode ist Predictive Coding (PC), die inspiriert ist von Hinweisen aus der Neurowissenschaft auf die Arbeitsweise des Gehirns. Predictive Coding versucht, die Differenz zwischen erwarteten und tatsächlichen Signalen zu minimieren, um effizientes Lernen zu ermöglichen.
Allerdings lässt sich diese Methodik bislang nur schwer auf sehr tiefe Netzwerke anwenden. Die größte Herausforderung bestand bisher darin, PC-Netzwerke auf mehr als wenige Dutzend Schichten zu skalieren, ohne dass dabei Trainingsinstabilitäten oder Leistungseinbußen auftraten. Hier setzt die innovative neue Methode µPC an, die es ermöglicht, Predictive Coding stabil auf Netzwerke mit mehr als 100 Schichten anzuwenden. µPC basiert auf einer speziellen Parametrisierung namens Depth-µP, die das Skalierungsverhalten von Gewichten und Aktivierungen in tiefen Netzen besser reguliert. Damit werden gleich mehrere Probleme gelöst, die bisherige PC-Ansätze bei der Skalierung großer, tiefer Netzwerke gekennzeichnet haben.
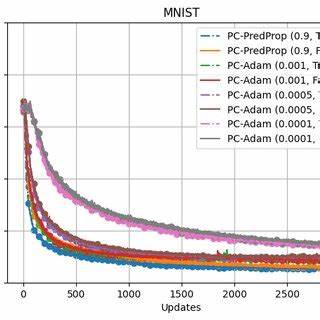
Die Forscher Francesco Innocenti, El Mehdi Achour und Christopher L. Buckley zeigen in ihrem jüngsten Beitrag, dass µPC erstmals ein robustes Training von tiefen Residualnetzwerken mit bis zu 128 Schichten erlaubt. Interessant ist, dass dieses Training auf vergleichsweise einfachen Klassifikationsaufgaben bereits sehr konkurrenzfähige Resultate erzielt, und zwar mit deutlich weniger aufwändigem Hyperparameter-Tuning als bei anderen Methoden. Die Stabilität und Trainingsleistung von µPC basiert vor allem darauf, dass die zugrunde liegende Depth-µP-Parametrisierung Gewichtsmatrizen und Lernraten so skaliert, dass weder Explosionen noch Verschwindungen von Signalen auftreten. Dies ist entscheidend für tiefe Netzwerke, bei denen kleine Ungleichgewichte sich über viele Schichten hinweg dramatisch verstärken können.
Neben der verbesserten Skalierbarkeit bringt µPC den Vorteil, dass sich die für das Training wichtigen Hyperparameter wie Lernraten sowohl für Gewichte als auch für Aktivitäten zwischen verschiedenen Netzwerkbreiten und -tiefen ohne Nachjustierungen übertragen lassen. Dies spart enorm Zeit und Rechenressourcen bei der Modellentwicklung und macht µPC besonders attraktiv für praktische Anwendungen. Die Relevanz von µPC geht über reine Feedforward-Residualnetzwerke hinaus. Die Forscher weisen darauf hin, dass das Prinzip auf andere Architekturen wie etwa convolutionale Neuromodelle oder moderne Transformer-Netzwerke übertragen werden kann. Gerade bei Letzteren, die in vielen aktuellen KI-Anwendungen dominieren, könnten biologisch inspirierte und lokal berechnete Lernverfahren neue, effiziente Trainingsparadigmen eröffnen.
Insgesamt stellt µPC einen Meilenstein dar, indem es demonstriert, dass biologisch plausibles Lernen im großen Maßstab keine unlösbare Herausforderung ist. Die enge Verzahnung von theoretischer Analyse und praktischer Implementierung sorgt für eine Methodik, die nicht nur wissenschaftlich überzeugend, sondern auch technisch umsetzbar ist. Die Bereitstellung des Codes in Form einer JAX-Bibliothek unterstreicht den offenen Ansatz der Entwickler und erleichtert es anderen Forschern und Entwicklern, µPC weiterzuverfolgen und in eigenen Projekten einzusetzen. Aus Sicht der KI-Forschung hat µPC das Potenzial, die Debatte um biologisch plausible Lernalgorithmen entscheidend voranzutreiben und parallel zur etablierten Backpropagation-Welt neue Wege zu eröffnen. Das Verständnis, wie das Gehirn komplexe Informationsverarbeitung mit lokalen Lernregeln realisiert, könnte so nicht nur künftige Algorithmen inspirieren, sondern auch dazu beitragen, energiesparendere und robustere künstliche Intelligenzsysteme zu entwickeln.
Damit positioniert sich µPC nicht nur als technische Innovation, sondern auch als Brücke zwischen neurowissenschaftlicher Forschung und angewandtem maschinellen Lernen. In der Praxis dürften von µPC vor allem Forschungsgebiete profitieren, in denen tiefes Lernen bislang an Rechen- oder Tuning-Komplexität scheiterte. Anwendungsfelder von der Bild- und Spracherkennung über Robotik bis hin zu medizinischer Diagnostik können davon profitieren, wenn auch lokal organisierte Lernalgorithmen konkurrenzfähige Performance bei geringerer Komplexität bieten. Zwar steht µPC noch am Anfang seiner Entwicklung und es sind weitere Untersuchungen zu Leistung, Skalierbarkeit und Anwendungsszenarien erforderlich, doch der Fortschritt ist vielversprechend. Die zunehmende Integration von biologischen Prinzipien in KI kann langfristig zu Systemen führen, die nicht nur leistungsfähiger, sondern auch besser erklärbar und anpassungsfähiger sind.
Zusammengefasst lässt sich sagen, dass µPC einen wichtigen Schritt darstellt, um Predictive Coding aus der Ecke der Theorieforschung hin zu vielseitig einsetzbaren, tiefen neuronalen Netzwerken zu bewegen. Mit der Überwindung der bisherigen Skalierungsbarrieren entsteht eine Plattform, die weiterhin Wachstum und Forschung im Bereich neuartiger Lernmethoden beflügeln wird. Die Fähigkeit, tiefere Netze zuverlässig und effizient mit lokal basierten Algorithmen zu trainieren, ist ein entscheidender Fortschritt auf dem Weg zu einer neuen Generation von KI-Systemen, die enger an biologischen Vorbildern orientiert sind und neue Maßstäbe in Verständlichkeit und Energieeffizienz setzen könnten.