Comma-Separated Values, kurz CSV, sind aus dem Alltag der Datenverarbeitung nicht mehr wegzudenken. Sie gelten als das universelle Format für den Austausch tabellarischer Daten und sind vor allem wegen ihrer Einfachheit und Menschlesbarkeit beliebt. Doch obwohl CSV-Dateien auf den ersten Blick unkompliziert erscheinen, verbergen sie viele spezifische Fallstricke, die Entwickler und Anbieter von Softwarelösungen vor größere Herausforderungen stellen. Gerade für Software-as-a-Service (SaaS)-Plattformen ist der Umgang mit CSV-Importen elementar, da dies oft die erste Hürde bei der Nutzerintegration darstellt. Eine fehlerhafte oder unzureichende Verarbeitung von CSV-Dateien kann nicht nur zu Frustration bei den Anwendern führen, sondern auch erheblichen Mehraufwand im Entwicklungsprozess verursachen.
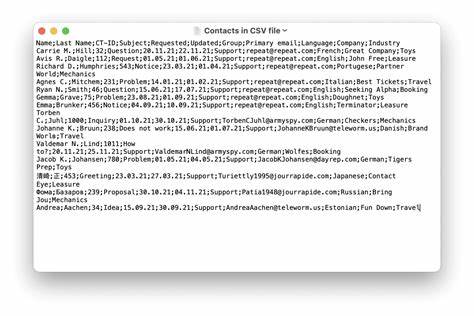
Die Bedeutung von CSV-Importen in SaaS-Lösungen lässt sich nur schwer überschätzen. Viele Nutzer laden beispielsweise Kontakte in Customer Relationship Management (CRM)-Systeme, Produktdaten in Onlineshops oder Personaldaten in HR-Software hoch. Beim Import dieser Daten ist es entscheidend, dass die Plattform CSV-Dateien zuverlässig und fehlerfrei verarbeiten kann. Der Grund hierfür liegt nicht zuletzt auch in der Tatsache, dass CSV-Dateien von Anwendern oft manuell bearbeitet werden – sei es in Office-Anwendungen oder reinen Texteditoren. Ihre einfache Struktur macht Veränderungen leicht verständlich und zugänglich, auch ohne tiefgehendes technisches Wissen.
Doch gerade diese Einfachheit ist oft trügerisch. Hinter dem scheinbar trivialen CSV-Format steckt eine Vielzahl unterschiedlicher Besonderheiten und potenzieller Stolpersteine. Das eigentliche RFC 4180-Protokoll, welches das CSV-Format definiert, ist in der Praxis häufig nicht ausreichend, da viele Programme und Anwender eigene Varianten und Abweichungen verwenden. Zum Beispiel können CSV-Dateien nicht nur durch Kommata, sondern auch durch Tabulatoren, Semikolons oder gar Pipes getrennt sein. Dieses Phänomen ist besonders in europäischen Märkten verbreitet, wo Excel oft standardmäßig Semikolons als Trennzeichen verwendet.
Fehlt die Möglichkeit, den Delimiter flexibel zu konfigurieren, schlägt der Import automatisch fehl. Neben der Wahl des richtigen Trennzeichens bereitet auch die korrekte Behandlung von Anführungszeichen und Escape-Zeichen Schwierigkeiten. CSV unterstützt das Einschließen von Datenfeldern in doppelte Anführungszeichen, was nötig ist, wenn beispielsweise Trennzeichen oder Zeilenumbrüche innerhalb eines Feldes vorkommen. Das RFC-Konzept sieht vor, Anführungszeichen innerhalb eines Felds durch zweimalige Anführungszeichen zu maskieren. In der Praxis jedoch verwenden einige Anwendungen stattdessen Backslashes oder andere Mechanismen.
Auch die unterschiedlichen Zeilenendungen, etwa CRLF unter Windows oder LF bei Unix-Systemen, führen zu Kompatibilitätsproblemen bei der Zeilenaufteilung. Ein weiterer oft übersehener Aspekt sind Encodings. Aufgrund der weltweiten Verbreitung von CSV-Dateien liegen verschiedene Zeichencodierungen vor. Während UTF-8 heute Standard ist, finden sich in manchen Ländern und vor allem in älteren Dateien noch ISO-8859-1 oder UTF-16. Excel nutzt häufig eigene Varianten, was die korrekte Erkennung und Umwandlung von Zeichen schwierig macht.
Ohne eine adäquate Behandlung dieser Probleme kommt es zu fehlerhaften Zeichen, unlesbaren Texten oder gar Datenverlust. Darüber hinaus steht die Performance bei der Verarbeitung großer CSV-Dateien im Fokus. Einfache Parser laden die gesamte Datei in den Arbeitsspeicher, was bei großen Datenmengen zu Abstürzen führen kann. Effektivere Lösungen setzen daher auf Streaming-Ansätze, bei denen die Datei zeilenweise verarbeitet wird. Allerdings steigt damit die Komplexität, da unter anderem die gleichzeitige Verarbeitung und Verwaltung von Datenstrom, Rückdruck-Handling (Backpressure) und Fehlerbehandlung koordiniert werden muss.
Ein ebenfalls kritischer Punkt ist die automatische Typenerkennung. CSV-Dateien enthalten meist keine Schema-Informationen, was dazu führt, dass Importbibliotheken beispielsweise Zahlen mit vorangestellten Nullen (etwa Postleitzahlen) als numerische Werte interpretieren und dabei wichtige Nullen abschneiden. Oder Datumsangaben werden falsch interpretiert, wenn unterschiedliche Formate gemischt verwendet werden. Solche Fehler führen zu massiven Problemen in der nachfolgenden Verarbeitung und Analyse. Aufgrund dieser komplexen Sachverhalte sind selbst vermeintlich einfache CSV-Parser weit entfernt davon, einfach zu implementieren.
Die Entwicklung eines eigenen Parsers zieht häufig unerwartet hohe Kosten nach sich, da unvorhergesehene Randfälle und regionale Besonderheiten aufgedeckt werden müssen. Ein berühmtes Beispiel im SaaS-Bereich zeigt, dass ein Gründer über 100.000 Dollar in die Behebung von CSV-Parsing-Problemen stecken musste – eine enorme Investition, die leicht hätte vermieden werden können. Die praktische Umsetzung von CSV-Importen in SaaS-Produkten offenbart darüber hinaus branchenspezifische Herausforderungen. Im CRM-Bereich erschweren komplexe Datenzuordnungen und internationale Sonderzeichen die korrekte Verarbeitung.
In E-Commerce-Systemen treten häufig mehrzeilige Produktbeschreibungen, eingebettete Anführungszeichen und uneinheitliche Formate auf. HR-Daten sind besonders problematisch, wenn unterschiedliche Datumsformate und codierungsspezifische Eigenheiten kombiniert werden. Um all dies möglichst fehlerfrei zu managen, sind robuste, flexible und vor allem anwenderfreundliche Importmechanismen unerlässlich. Der Schlüssel zu erfolgreichen CSV-Importen liegt in einer defensiven und wohlüberlegten Herangehensweise. Anbieter sollten ihren Nutzern die Möglichkeit geben, wichtige Parameter wie das Trennzeichen, Anführungszeichen oder Encoding individuell festzulegen und so maximale Flexibilität schaffen.
Klare Validierungsrückmeldungen und interaktive Vorschauen helfen, Fehler frühzeitig zu erkennen und zu beheben, was die Nutzerzufriedenheit deutlich steigert. Gleichzeitig empfiehlt es sich, bestehende gut gepflegte Importbibliotheken zu verwenden, die auf die jeweiligen Anwendungsfälle zugeschnitten sind. Die Integration sollte modular erfolgen, sodass unterschiedliche Layer für Schema-Mapping, Datenvalidierung und Transformation getrennt behandelt werden können. So lässt sich auch bei komplexen Konstellationen eine saubere und skalierbare Lösung aufbauen. Zusammenfassend lässt sich sagen, dass CSV-Dateien trotz ihrer allgegenwärtigen Nutzung und anfänglichen Einfachheit ein Format sind, das aufgrund seiner verborgenen Komplexitäten besondere Aufmerksamkeit verdient.
Entwickler und SaaS-Anbieter, die diese Herausforderungen antizipieren und mit einer durchdachten Strategie angehen, vermeiden nicht nur unnötige Kosten und Frustration, sondern sichern sich einen entscheidenden Wettbewerbsvorteil durch hervorragende Nutzererfahrungen beim Datenimport. Respekt vor dem CSV-Format zahlt sich somit in jeder Hinsicht aus und schafft die Basis für langfristigen Erfolg und Skalierbarkeit im digitalen Zeitalter.