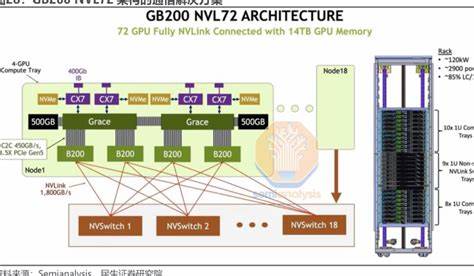
Die kontinuierliche Weiterentwicklung von KI-Hardware und Softwarearchitekturen ist entscheidend für den Fortschritt moderner künstlicher Intelligenz. Mit dem GB200 NVL72 präsentiert NVIDIA eine der fortschrittlichsten Plattformen für KI-Training und Inferenz, die speziell für hochkomplexe Modelle wie DeepSeek 671B entwickelt wurde. Der jüngste Erfolg in der Implementierung von DeepSeek mit Prefill-Decode-Disaggregation (PD) und großskaligem Expertenparallelismus (Large Scale Expert Parallelism, EP) auf dem GB200 NVL72 markiert einen bedeutenden Meilenstein in Leistung und Effizienz. Die erzielte 2,7-fache Steigerung der Dekodierdurchsatzrate im Vergleich zum H100 pro GPU hebt das System in seiner Klasse hervor und eröffnet neue Möglichkeiten für groß angelegte KI-Anwendungen. Die tiefgreifenden technischen Anpassungen und Optimierungen, die diesen Fortschritt ermöglichen, bieten wertvolle Einblicke für Entwickler und Forscher, die die nächste Generation von KI-Modellen realisieren möchten.
Der GB200 NVL72 ist eine speziell entwickelte AI-Plattform, die höhere Speicherbandbreite, eine gesteigerte Rechenleistung sowie eine verbesserte Kommunikationsinfrastruktur über NVLink statt herkömmlichem RDMA bietet. Diese Hardwareeigenschaften schaffen die Grundlage für die herausragende Performance von DeepSeek auf dieser Plattform. Die Unterstützung von größeren Batch-Größen durch einen erweiterten Speicher ermöglicht die Nutzung einer größeren Key-Value-Caching-Struktur, die für eine effiziente Verarbeitung großer Modelle essenziell ist. Durch die Eliminierung von Engpässen in der Kommunikation und Datenbewegung können Rechenoperationen flüssiger und schneller ablaufen, wodurch Inter-Token-Latenzen vergleichbar mit denen der H100 erzielt werden. Ein zentraler Bestandteil der Optimierung ist die Integration mehrerer Blackwell-spezifischer Softwarekomponenten.
Die Blackwell DeepGEMM-Bibliothek wurde für FP8-Präzision angepasst, um die Rechenleistung der GB200-Architektur vollständig auszunutzen. Durch neue API-Funktionen, die Quantisierung und Verpackung von Eingabeskalierungen unterstützen, sowie den Einsatz der UMMA-Technologie für Matrixmultiplikationen, konnte die Effizienz der Berechnungen signifikant gesteigert werden. Parallel dazu sorgt die Blackwell DeepEP-Kommunikationsbibliothek für einen optimierten Datenaustausch bei der Token-Verteilung in Mixture of Experts (MoE)-Architekturen. Die Anbindung ausschließlich über NVLink verbessert dabei die Latenzzeiten erheblich. Für die Präfill-Phase des DeepSeek-Modells wurde die FlashInfer Blackwell FMHA (Fused Multi-Head Attention) vollständig auf die Blackwell-Architektur portiert und optimiert, was zu deutlich schnelleren Berechnungen in dieser wichtigen Modellphase führt.
Zudem erlaubt der Blackwell CUTLASS MLA-Kernel (Multi-Head Latent Attention) durch eine Kombination aus UMMA und reduzierter L2-Lesezugriffe eine effiziente Verarbeitung des KV-Caches, indem der Durchsatz bei komplexen Aufmerksamkeitsschritten maximiert wird. Ein weiterer innovativer Bestandteil ist die Nutzung des Blackwell Mooncake Transfer-Engines, die besonders bei der Übertragung von Gewichtsinformationen im Key-Value-Cache zum Einsatz kommt. Hierbei werden Techniken verwendet, die auf DeepEP basieren, um auch bei hohen Datenmengen auf NVLink schnelle und zuverlässige Transfers zu gewährleisten. Dies ist für die erfolgreiche Umsetzung der Prefill-Decode-Disaggregation, bei welcher die Vorbefüllung und Dekodierung getrennt ablaufen, unerlässlich. Experimentelle Tests bestätigen die erzielte Leistungssteigerung eindrucksvoll.
Im realistischen Szenario wurden 14 GB200 NVL72 Nodes verwendet, davon zwölf für die Dekodierung und zwei für die Prefill-Phase. Das Setup imitierte typische Anwendungsfälle und nutzte vorhandene APIs, um eine Belastung der Dekodierknoten zu garantieren. Verglichen mit dem H100-System konnte eine durchschnittliche Verbesserung der Dekodiergeschwindigkeit von 2,5- bis 3,4-fach über verschiedene Token-Längen hinweg gemessen werden. Die Kombination aus verbessertem Speicher- und Rechenzugriff, größerer Speicherfähigkeit für Batches sowie der NVLink-basierten Kommunikation waren hierbei maßgebliche Faktoren. Zusätzlich wurde der Einfluss der Batch-Größe auf den Durchsatz analysiert.
Die Analyse zeigte, dass größere Batch-Größen einen direkten positiven Effekt auf die Leistungskennzahlen haben. Das System zeigt dabei bei identischer Batch-Größe durchweg schnellere Verarbeitung auf dem GB200 im Vergleich zum H100. Dies unterstreicht die Hardwarevorteile des GB200 NVL72. Allerdings wurde auch deutlich, dass kleine Batch-Größen weniger effizient genutzt werden können, was insbesondere beim Einsatz auf anderen Hardwareplattformen wie dem B200 oder RTX 5090 noch Optimierungspotenzial birgt. Die implementierten PD- und großskaligen EP-Ansätze nehmen dabei eine Schlüsselrolle ein.
PD ermöglicht eine flexible und effiziente Aufteilung der Vorbefüllungs- und Dekodieraufgaben, wodurch die Ressourcen optimal genutzt werden und Engpässe reduziert werden. Der großskalige Expertenparallelismus verbessert zusätzlich die Leistung des Mixture-of-Experts-Modells, da durch die Verteilung des Expertenlastdrucks die Belastung auf den Speicherzugriff reduziert wird. Dieses Zusammenspiel von Hardwareeigenschaften und Softwareoptimierungen macht die hochperformante Anwendung von DeepSeek auf der GB200 NVL72 Plattform möglich. Trotz der bereits hervorragenden Ergebnisse ist die Entwicklung keineswegs abgeschlossen. Zukünftige Optimierungen könnten die Performance weiter steigern.
Die Fokussierung auf Präfill-Phase und Latenzoptimierungen soll Schritt für Schritt die Gesamtdurchsatzwerte erhöhen und die Antwortzeiten verkürzen. Darüber hinaus gibt es noch nicht komplett ausgeschöpfte Potenziale bei der Nutzung der speicher- und rechenintensiven Kernel des GB200 NVL72. Effiziente Überlappung von Kommunikation und Berechnung könnte ebenfalls weitere Verbesserungen ermöglichen, insbesondere durch ähnliche oder weiterentwickelte Verfahren gegenüber den bisherigen H100-basierten Prozessen. Ein weiteres spannendes Forschungsfeld ist die Multi-Token Prediction (MTP), bei der mehrere Token parallel in einem Vorwärtspass vorhergesagt werden. Diese Technik verspricht insbesondere bei kleinen Batches Effizienzgewinne und eine bessere Auslastung der Hardware.
Die Integration und Optimierung dieser Methode könnten zu einer weiteren Steigerung der realen Dekodierraten führen. Die Zusammenarbeit zwischen den beteiligten Entwicklungsteams war entscheidend für diese Fortschritte. Neben der SGLang Core Team-Community und den Mooncake-Spezialisten spielte auch das NVIDIA-Team, bestehend aus Hardware-, DevTech-, FlashInfer-Teams und weiteren Experten, eine wesentliche Rolle bei der Entwicklung, Portierung und Optimierung der Kernkomponenten für die Blackwell-Architektur. Diese Kooperation unterstreicht die Bedeutung interdisziplinärer Ansätze in modernen KI-Entwicklungsprojekten. Zusammenfassend zeigt der Einsatz von DeepSeek auf der GB200 NVL72 mit Prefill-Decode-Disaggregation und großskaligem Expertenparallelismus eindrucksvoll, wie sich Hardwareinnovation und maßgeschneiderte Softwarelösungen kombinieren lassen, um erhebliche Performancegewinne zu erzielen.
Die 2,7-fache Steigerung der Dekodierdurchsatzrate gegenüber bisherigen Systemen ist ein deutliches Zeichen für die Fortschritte im Bereich KI-Infrastruktur und stellt eine vielversprechende Basis für zukünftige Forschungs- und Anwendungsprojekte dar. Unternehmen und Entwickler, die leistungsfähige KI-Modelle betreiben möchten, können von diesen Technologien nachhaltig profitieren und so den Weg zu noch leistungsfähigeren KI-Diensten ebnen.