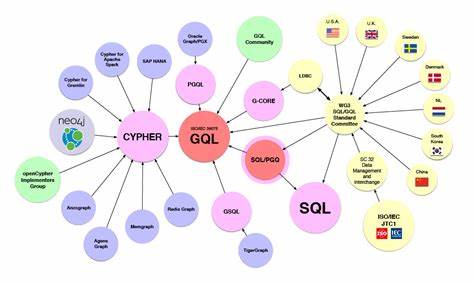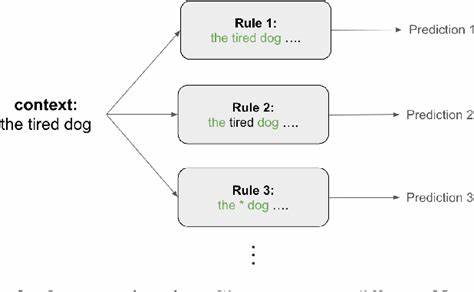
Transformer-Modelle haben die Welt der künstlichen Intelligenz revolutioniert und besonders die Verarbeitung natürlicher Sprache auf ein ganz neues Niveau gehoben. Trotz ihrer enormen Leistungsfähigkeit bleibt das genaue Innenleben dieser Modelle für viele Fachleute teilweise rätselhaft. Die Frage, wie Transformer in der Lage sind, Kontext zu verstehen und darauf basierend sinnvolle Vorhersagen zu erstellen, ist zentral für die Weiterentwicklung und den verantwortungsvollen Einsatz solcher Systeme. Ein neuer Ansatz, der vielversprechende Einblicke bietet, nutzt klassische N-Gramm-Statistiken – eine Methode, die eigentlich aus der traditionellen Sprachverarbeitung stammt – um die komplexen Funktionen von Transformern besser nachvollziehbar zu machen.N-Gramm-Modelle arbeiten mit Wahrscheinlichkeiten für Sequenzen von Wörtern oder Zeichen, die in einer bestimmten Reihenfolge auftreten.
Dabei untersucht man zum Beispiel, wie wahrscheinlich es ist, dass auf eine bestimmte Wortfolge ein bestimmtes nächstes Wort folgt. Obwohl diese Methode im Vergleich zu modernen neuronalen Netzwerken einfach aussieht, zeigt sich nun, dass N-Gramm-Statistiken eine hervorragende Basis bilden, um die Mechanismen vieler Transformer-Vorhersagen zu modellieren und zu verstehen.Durch die systematische Analyse der Vorhersagen von Transformers in Bezug auf N-Gramm-Regeln konnten Forscher wichtige Erkenntnisse gewinnen. Eine davon ist die Fähigkeit, den Trainingsprozess des Modells besser zu überwachen und etwaiges Überanpassen, also Overfitting, zu erkennen. Normalerweise benötigt man dafür einen separaten, sogenannten Holdout-Datensatz, um zu testen, ob das Modell nur die Trainingsdaten auswendig gelernt hat oder tatsächlich generalisieren kann.
Mit der neuen Methode ist es möglich, dieses Overfitting direkt während des Trainings anhand von N-Gramm-Regeln zu identifizieren, was eine effizientere und kontrollierte Optimierung erlaubt.Ein weiterer spannender Aspekt ist das Verständnis der Lernkurve von Transformern. Zu Beginn des Trainings scheinen die Modelle eher einfache statistische Muster zu erfassen, die sich mit N-Gramm-Statistiken gut beschreiben lassen. Im Laufe der Zeit entwickeln sich die Modelle jedoch weiter und beginnen, komplexere Strukturen und Abhängigkeiten in der Sprache zu erkennen. Dies lässt sich quantitativ messen und gibt Aufschluss darüber, wie die Sprachmodelle „reifen“ und komplexere sprachliche Phänomene erfassen.
Interessanterweise erklären N-Gramm-basierte Regeln einen großen Teil der Vorhersagen von Transformern sehr gut. Untersuchungen an verschiedenen Datenquellen, wie unter anderem TinyStories und Wikipedia, zeigen, dass die Top-1-Vorhersagen in 79 bzw. 68 Prozent der Fälle mit denen von komplexen N-Gramm-Regelsystemen übereinstimmen. Das bedeutet, dass trotz der großen Komplexität von Transformern ein wesentlicher Teil ihres Verhaltens durch einfachere, statistisch fundierte Regeln nachvollziehbar ist.Diese Erkenntnisse bieten nicht nur theoretischen Wert, sondern haben auch praktische Konsequenzen.
Zum Beispiel können Entwickler von Sprachmodellen durch den Einsatz von N-Gramm-Statistiken Evaluierungen und Fehlersuchen gezielter durchführen. Außerdem ermöglichen diese Methoden, Ressourcen effizienter zu nutzen, da weniger umfangreiche Validierungsdatensätze notwendig sind und Modelle dadurch schneller und mit weniger Rechenaufwand optimiert werden können.Das Modell-Varianz-Kriterium, eine weitere wichtige Entdeckung, beschreibt unter welchen Umständen Transformer-Vorhersagen besonders gut durch N-Gramm-Regeln abgebildet werden können. Dieses Kriterium hilft zu verstehen, wann sich das Verhalten eines Modells als statistisch stabil und vorhersagbar erweist und wann komplexere, nichtlineare Muster vorliegen, die über einfache N-Gramme hinausgehen. Die Anwendung dieser Theorie liefert damit eine Grundlage, um geeignete Modellarchitekturen und Trainingsstrategien zu entwickeln, die genau auf die jeweiligen Anforderungen zugeschnitten sind.
Ein weiteres bemerkenswertes Ergebnis ist die Perspektive, wie Transformer-Modelle sich im Grenzfall verhalten, wenn die N-Gramm-Regelsätze immer komplexer und ausführlicher gestaltet werden. Die Annäherung an die Vorhersagen der Transformer legt nahe, dass viele der scheinbar komplexen Sprachmuster letztlich auf einer erweiterten Form von N-Gramm-Statistiken beruhen. Diese Sichtweise könnte dazu beitragen, das innere Zusammenspiel von Kontextverarbeitung und Mustererkennung in Transformern besser theoretisch zu fassen und weiterführende Algorithmen zu entwerfen, die sowohl leistungsfähig als auch erklärbar sind.In der Praxis bedeutet diese Forschung eine Brücke zwischen klassischen statistischen Methoden und modernen Deep-Learning-Ansätzen. Während neuronale Netzwerke oft als Blackbox angesehen werden, eröffnen N-Gramm-Analysen einen Zugang, diese Blackbox zu öffnen und nachvollziehbar zu machen, was tatsächlich hinter den Kulissen passiert.