In der Welt der Künstlichen Intelligenz (KI) konkurrieren heutzutage zahlreiche Produkte und Agenten miteinander – sei es bei KI-basierten Empfangsmitarbeitern, Coding-Agents oder Textgenerierungstools. Auf den ersten Blick scheinen viele dieser Anwendungen ähnlich zu sein, doch das eigentliche Unterscheidungsmerkmal liegt in ihren Evaluierungen. Für KI-native Unternehmen sind Evaluierungen weit mehr als nur ein Werkzeug zur Qualitätssicherung. Sie bilden die Grundlage des Produkts selbst. Dieser Gedanke mag kontrovers erscheinen, doch er ist essenziell, wenn man nachhaltigen Erfolg bei der Entwicklung moderner KI-Systeme anstrebt.
Die Rolle von Evaluierungen darf deshalb nicht an externe Frameworks ausgelagert werden. Stattdessen sollten KI-Ingenieure die Evaluierungsmethoden als zentrales Element ihrer Produktentwicklung begreifen und beherrschen. Die fundamentale Erkenntnis ist einfach: Ohne messbare und zuverlässig dokumentierte Evaluierungen kann keine Verbesserung am System erfolgen. Entwicklerteams bewegen sich ansonsten gewissermaßen im Blindflug. Besonders angesichts der hohen Dynamik in der Entwicklung von Large Language Models (LLMs) und anderen KI-Technologien muss die Evaluation flexibel und leichtgewichtig sein, um mit dem rasanten Tempo der Innovation Schritt zu halten.
Schwerfällige und starre Test-Frameworks passen einfach nicht mehr in die Arbeitswelt innovativer KI-Teams. Ein Paradebeispiel für diesen agilen Umgang mit Evaluierungen ist die Entwicklung bei Tusk, einem Tool zur automatisierten Generierung von Unit-Tests für Softwareprojekte unter Einsatz von KI. Das Unternehmen hat früh erkannt, dass traditionelle Evaluierungsansätze ihren Anforderungen nicht gerecht werden. Die ständige Weiterentwicklung des Codes und sich beständig ändernde Features erfordern flexiblere und schnell anpassbare Methoden. Die Herausforderung bestand darin, das komplexe System von Tusk in sinnvolle Komponenten zu zerlegen, um für jeden Bereich individuelle Tests und Evaluierungen aufzusetzen.
Damit wird gewährleistet, dass einzelne Funktionen unabhängig geprüft und optimiert werden können, ohne die gesamte Anwendung zu simulieren. Diese Teileinheiten haben oft ihre eigenen unterschiedlich strukturierten Ein- und Ausgaben. Ein signifikanter Vorteil entsteht, wenn jeder Funktionsbaustein klar definierte Ein- und Ausgabeschnittstellen besitzt. Hier setzt die funktionale Programmierung an, die bei Tusk bewusst bevorzugt wird. Durch Vermeidung von objektorientierten Mustern, komplexen Klassenhierarchien und globalen Zuständen entwickelt das Team einen klaren Datenfluss innerhalb jeder Funktion, der einfach nachvollziehbar und isolierbar ist.
Das bedeutet, dass für die Evaluierung nicht mehr das komplette System aufgesetzt werden muss. Stattdessen kann eine einzelne Funktion anhand eines Datensatzes direkt und effizient geprüft werden. Ein ähnlicher Umgang mit Evaluierungen wird so möglich, wie man es von Unit-Tests her kennt: klar, präzise und wartbar. Ein Beispiel aus der Praxis verdeutlicht dies sehr gut: Die sogenannte „Test File Incorporation“, ein Prozess, bei dem neue generierte Tests sauber und konsistent in bestehende Testdateien eingefügt werden, ist ein kritischer Schritt bei Tusk. Entwickler wollen, dass die Testdateien nicht nur funktionieren, sondern auch lesbar, sauber formatiert und gut strukturiert bleiben.
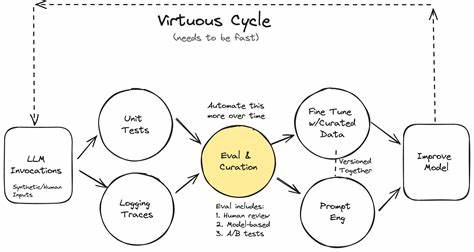
Um die beste Vorgehensweise umzusetzen, mussten verschiedene Ansätze schwerpunktmäßig auf Zuverlässigkeit und Laufzeit getestet werden. Ohne ein flexibles Eval-Setup wäre es nicht möglich gewesen, diese Varianten schnell und systematisch miteinander zu vergleichen. Der Durchbruch war die Erkenntnis, dass Evaluierungen nicht zwangsläufig komplex und aufwendig sein müssen. Ein einfacher aber klarer Vertrag zwischen Input und Output genügt – dass bedeutet, es muss genau definiert sein, was in die Funktion hineingegeben wird und was als Resultat herauskommen soll. Die Ergebnisse lassen sich mittels Schnittstellen zu modernen Werkzeugen wie Cursor oder Claude weiter automatisiert und in übersichtlichen, meist HTML-basierten Berichten visualisieren.
Diese Berichte bieten Entwicklern eine schnelle und intuitive Möglichkeit, die Leistungsfähigkeit einzelner Komponenten anhand realer Daten zu bewerten. Diese Leichtgewichtigkeit in der Evaluierung bringt wesentliche Vorteile mit sich. Zum einen ist die Geschwindigkeit, mit der solche Eval-Skripte entstehen, enorm. Wo früher monatelange Infrastrukturprojekte für Tests notwendig waren, lassen sich nun in wenigen Minuten funktionale Prüfungen schreiben. Reagiere das System auf Änderungen in Input- oder Outputformat schnell, führt das zur einfachen Anpassung der Datensätze und folglich zu einer neuen Auswertung.
Zudem entstehen keine hohen Kosten durch externe Services oder komplexe Tools – es genügt ein schlankes Set an selbst entwickelten Skripten und eine Dateiablage, die zunehmend zur Quelle der Wahrheit wird. Mit zunehmender Nutzung etablierte sich diese Haltung innerhalb des Teams: Statt blind Intuition oder wenigen Beispieltests zu vertrauen, steht mit den evaluierten Ergebnissen eine messbare und visuell nachvollziehbare Datenbasis. Unterschiedliche Ansätze für die gleiche Funktion werden einfach nebeneinander in die Berichte gepackt, was eine klare Entscheidungsgrundlage schafft. Ebenso können Einfluss neuer Modelle schnell untersucht und mit bekannten Strategien verglichen werden. Diese Transparenz und Agilität beschleunigen den gesamten Entwicklungsprozess erheblich.
Aus der Praxis von Tusk lässt sich für weitere KI-Ingenieure eine zentrale Erkenntnis ableiten: Auch wenn am Anfang das Evaluieren mühsam erscheinen mag, zahlt sich der Aufwand langfristig vielfach aus. Produkte, die auf einer eval-getriebenen Entwicklung basieren, erreichen deutlich öfter Produktionsreife und eine konstant hohe Qualität. Dabei geht es nicht darum, besonders aufwendige Analysen zu produzieren, sondern darum, sinnvolle, flexible und möglichst automatisierte Kontrollmechanismen zu etablieren, die ständig mitwachsen. Der Fokus auf funktionale Programmierung als Grundlage dieses Ansatzes ist ebenfalls ein wertvoller Tipp. Die saubere Trennung von Zuständigkeiten, die Vermeidung von komplexen Abhängigkeiten und der reduzierte Datenfluss erleichtern nicht nur die Entwicklung, sondern schaffen auch die Basis für verlässliche und wiederholbare Evaluierungen.
In Kombination mit modernen AI-Assistenzwerkzeugen, die Resultate automatisiert aufbereiten, entsteht so eine effiziente Methodik zur Qualitätssicherung in einem sich schnell wandelnden Umfeld. Insgesamt zeigt das Beispiel von Tusk eindrucksvoll, dass man Evaluierungen nicht als lästige Pflicht oder als etwas Externes sehen darf. Sie sind ein integraler Teil des Produkts und der Entwicklungsstrategie. Gerade in Zeiten, in denen KI-Agenten und Systeme beinahe täglich erweitert und optimiert werden, sichern flexible, leichte und unmittelbar nutzbare Eval-Methoden den Fortschritt. Wenn KI-Ingenieure ihre Evaluierungen selbst gestalten und diese als ein lebendiges Produktmerkmal verstehen, dann legen sie die Grundlage für nachhaltigen Erfolg – und das bei minimalem Mehraufwand.
Abschließend lässt sich festhalten: Der Schlüssel zum Erfolg moderner KI-Produkte liegt in der eval-getriebenen Entwicklung. Ob durch funktionale Programmierung oder einfache, schnell anpassbare Skripte – eine solide Evaluierung öffnet den Blick auf die Qualität des Systems und ermöglicht gezielte Verbesserungen. KI-Ingenieure, die diesen Gedanken verinnerlichen, sind bestens gerüstet, um ihre Produkte in einer schnelllebigen, innovativen Branche konstant voranzubringen und marktfähig zu halten. Es bleibt spannend zu beobachten, wie viele Unternehmen diesem Modell folgen und welchen Innovationsschub es der KI-Entwicklung in Zukunft verleiht.