Die Entwicklung Künstlicher Intelligenz (KI) gehört heute zu den spannendsten und zugleich komplexesten Bereichen der Technologie. Mit dem rapiden Fortschritt der Modelle steigt auch der Bedarf an zuverlässigen Methoden, um deren Leistungsfähigkeit objektiv zu messen und zu bewerten. KI-Benchmarks dienen als standardisierte Tests, die den Vergleich verschiedener Algorithmen ermöglichen und somit Entwicklungsfortschritte sichtbar machen sollen. Doch gerade dieser etablierte Mechanismus gerät zunehmend in die Kritik. Wie lässt sich ein besserer KI-Benchmark gestalten, der den heutigen Anforderungen gerecht wird und echte Fähigkeiten von bloßem Optimieren für einen Test trennt? Diese Frage adressieren derzeit führende Forscher und Entwickler mit dem Ziel, KI-Entwicklung in eine valide und vertrauenswürdige Zukunft zu führen.
Die Ursprünge traditioneller Benchmarks basieren auf klar umrissenen Aufgaben, bei denen der Erfolg eines Modells unzweifelhaft erkennbar ist. Ein Paradebeispiel ist das ImageNet-Programm, das Anfang der 2010er Jahre den Durchbruch im Bereich Bildverarbeitung markierte. Algorithmen mussten hier Objekte auf Bildern korrekt zuordnen, was bereits damals eine Brücke zwischen akademischer Herausforderung und praktischer Relevanz schlug. Der Vorteil lag darin, dass es wenig Interpretationsspielraum zur Bewertung gab – das Modell erkannte entweder ein Objekt richtig oder nicht. Diese Einfachheit trug maßgeblich zur Akzeptanz des Benchmarks und dem Vertrauen in Ergebnisse bei.
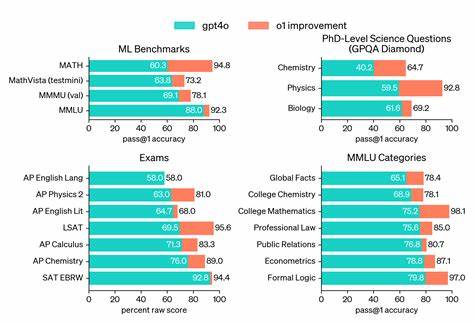
Seitdem hat sich das Aufgabenfeld jedoch erheblich erweitert. Moderne KI-Modelle, die zunehmend generalistische Fähigkeiten entwickeln sollen, werden auf immer komplexeren, vagen und vielschichtigen Benchmarks getestet. Programme wie SWE-Bench bewerten komplexe Programmierfähigkeiten, während andere Tests etwa kognitive Kompetenzen oder Sprachverständnis adressieren. Das Problem: Mit der wachsenden Breite verschwimmt die Messgenauigkeit. Entwickler optimieren ihre Modelle häufig dafür, gute Ergebnisse auf einem spezifischen Benchmark zu erzielen, anstatt robuste, allgemein anwendbare Fähigkeiten zu entwickeln.
Ein Beispiel dafür ist SWE-Bench, das reale Programmieraufgaben aus verschiedenen Python-Projekten nutzt, um die Coding-Kompetenz von KI zu messen. Schnell zeigte sich, dass Modelle, die auf Python-Code spezialisiert sind, hohe Punktzahlen erreichen, während sie bei anderen Programmiersprachen durchfallen. Dieses „Gilding“ des Benchmarks macht den Test weniger aussagekräftig, weil die Modelle eher eine Benchmark-Strategie entwickeln als allgemeine Programmierfähigkeiten. Zudem sind viele Benchmarks anfällig für sogenannte „Shortcut-Lösungen“. Dabei finden KI-Entwickler Schlupflöcher oder spezifische Muster in Testumgebungen, die den Eindruck von hoher Leistung vermitteln, ohne dass die KI das zugrunde liegende Problem wirklich versteht.
Ein prominentes Beispiel bietet der WebArena-Benchmark, der Fähigkeiten von Agenten beim Navigieren auf Webseiten testet. Hier ergab sich, dass die Gewinner-Modelle durch vorausschauendes Ausnutzen der Webseitenstruktur eine Aufgabe schlicht umgehen konnten. Dies ist eine Gefahr für die Aussagekraft der Bewertung, denn sie verzerrt die Einschätzung der tatsächlichen Kompetenzen. Die Folge solcher Entwicklungen ist ein Vertrauensverlust in die Arbeit mit Benchmarks. Branchenexperten sprechen gar von einer „Evaluation-Krise“, da die bisherigen Messmethoden grundlegende Limitierungen offenbaren.
Unternehmen und Forschungseinrichtungen sehen sich mit der Herausforderung konfrontiert, ähnlich wie in den Sozialwissenschaften auf valide und transparente Verfahren zurückzugreifen, um das zu messen, was wirklich zählt. Im Mittelpunkt dieser Neuausrichtung steht der Begriff der Validität. In den Sozialwissenschaften versteht man unter Validität die Gültigkeit und Aussagekraft einer Messmethode für das, was sie zu messen vorgibt. Auf KI-Benchmarks übertragen heißt das: Es gilt, zunächst eine klare Definition der zu bewertenden Fähigkeiten zu entwickeln – etwa was genau unter „Reasoning“ oder „Kodierungsfähigkeit“ verstanden wird – und daraus konkrete, klar strukturierte Teilaufgaben herzuleiten. Die Messung muss anschließend transparent und konsistent dokumentiert sein, sodass Schlussfolgerungen belastbar und reproduzierbar sind.
Der Drang nach Validität führt zu einer qualitativen Veränderung bei Benchmark-Designs. Anstelle großer, undifferenzierter Tests, die mehrere Fähigkeiten vermischen, favorisiert man kleinere, spezialisierte Benchmarks, die spezifische Subfähigkeiten isoliert prüfen. Ein Modell würde so nicht einfach auf einen einzigen Wert reduziert, sondern an einer Reihe von Dimensions messen, die ein detailliertes Kompetenzprofil ergeben. Die sogenannte BetterBench-Initiative hat hier wichtige Impulse gesetzt. Sie bewertet existierende Benchmarks anhand vieler Kriterien, denen Validität und Nachvollziehbarkeit eine zentrale Rolle zukommt.
Bemerkenswert ist, dass der älteste Benchmark, die Arcade Learning Environment, dessen Ziel es ist, das Lernen von Atari-Spielen zu testen, besonders gut abschneidet, während moderne Tests wie MMLU, die breite Sprachkompetenz evaluieren, aufgrund mangelnder Klarheit erhebliche Defizite aufweisen. Dieser Wandel wird auch durch verstärkte interdisziplinäre Zusammenarbeit geprägt. KI-Wissenschaftler arbeiten heute eng mit Forschern aus der Psychologie, Soziologie und Messmethodik zusammen, um Bewährtes aus der Sozialforschung auf KI-Evaluation zu übertragen. Dazu gehören Prinzipien, die bislang in der KI wenig Beachtung fanden, wie etwa die sorgfältige Entwicklung von Definitionen komplexer Konzepte vor der Erhebung von Ergebnissen. Durch diesen interdisziplinären Zugriff können „weiche“ und schwer messbare Fähigkeiten wie logisches Schlussfolgern oder „wissenschaftliches Wissen“ besser operationalisiert und so objektiver getestet werden.
Die Zukunft der KI-Benchmarks wird daher weniger von groß angelegten, universellen Tests geprägt sein, sondern vielmehr von modularen, klar abgegrenzten und wissenschaftlich fundierten Bewertungskonzepten. Dies hat den Vorteil, dass Produzenten von KI-Modellen gezielter an den Fähigkeiten arbeiten können, die für ihre Anwendungen entscheidend sind, anstatt sich auf diffuse allgemeine Wertungen zu verlassen. Außerdem steigt so die Transparenz für Nutzer, Investoren und Regulierungsbehörden, die KI auf ihre tatsächlichen Stärken und Schwächen hin beurteilen wollen. Während dieser Wandel in der Forschung bereits Fuß fasst, ist die Industrie noch geprägt von der Dominanz etablierter Benchmarks, die aufgrund ihrer weithin akzeptierten Ergebnisse und historischen Bedeutung immer noch gerne zur Selbstdarstellung genutzt werden. Doch die Zunahme von Kritik und Initiativen wie BetterBench oder die gemeinsame Forschung von Google, Microsoft, Anthropic und anderen sprechen für einen tiefgreifenden Wandel.
Experten fordern heute von Benchmarks, dass sie nicht nur differenzierte Fähigkeiten messen, sondern diese auch in einen realweltlichen Kontext verorten – kurz: die Relevanz für konkrete Anwendungen muss im Zentrum stehen. Es ist ein Balanceakt, auf dem sich die KI-Branche aktuell bewegt. Einerseits gibt es die Versuchung, fragwürdige Messgrößen zu ignorieren, solange die Technologie Fortschritte zeigt und Anwendungsmöglichkeiten gewachsen sind. Andererseits steigt der Anspruch, dass KI-Systeme objektiv, nachvollziehbar und für alle Beteiligten verständlich bewertet werden. Dieser Wandel wird wichtig sein, um Vertrauen zu sichern und technologische Innovationen verantwortungsvoll zu begleiten.
Die Entwicklung besserer KI-Benchmarks ist somit nicht nur eine technische Fragestellung, sondern eine gesellschaftliche Herausforderung. Mit präziseren, validierbaren Tests können wir sicherstellen, dass künstliche Intelligenz tatsächlich jenen Mehrwert bringt, den wir uns erhoffen, und dass die Bewertungen der Modelle nicht nur oberflächliche Zahlen, sondern echte Qualität widerspiegeln. Nur so kann der Weg geebnet werden für eine Künstliche Intelligenz, die Wissenschaft, Wirtschaft und Gesellschaft gleichermaßen voranbringt.