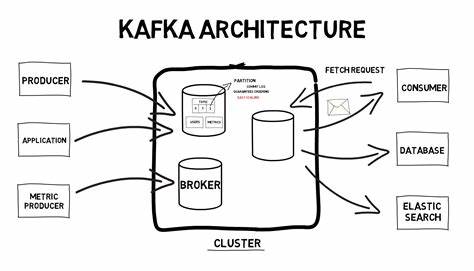
Apache Kafka hat sich über die letzten Jahre zu einem der bedeutendsten Werkzeuge für die Verarbeitung großer Datenmengen in Echtzeit entwickelt. Viele Unternehmen und Projekte setzen auf Kafka, um zuverlässig und skalierbar Nachrichtenströme zu verarbeiten. Doch was macht Kafka in technischer Hinsicht so bemerkenswert? Um das zu verstehen, lohnt sich ein genauer Blick in die Interna und die Codebasis des Systems – von den grundlegenden Komponenten bis hin zu neueren Entwicklungen wie dem KRaft-Modus. Kafka basiert auf der Idee eines verteilten, replizierten Logs, das Daten dauerhaft speichert und einen zuverlässigen Nachrichtentransport garantiert. Dabei spielen drei Hauptakteure eine zentrale Rolle: Die Broker, die Daten entgegennehmen und speichern, die Produzenten, die Nachrichten in das System einspeisen, und die Konsumenten, die Daten aus Kafka lesen.
Das Besondere ist unter anderem die Partitionierung, die parallele Verarbeitung und somit Skalierbarkeit ermöglicht. Jede Partition wird dabei auf einem oder mehreren Broker-Replikaten gehostet, um Ausfallsicherheit sicherzustellen. Der Einstiegspunkt in die Kafka-Architektur liegt beim sogenannten Broker-Server, der beim Start durch ein Skript namens kafka-server-start.sh initialisiert wird. Dieses Skript ruft letztlich die Java-Klasse kafka.
Kafka auf, welche die zentrale Steuerung des Servers übernimmt. Wesentliche Schritte dabei sind das Einlesen der Konfigurationsdatei, das Erzeugen eines Server-Objekts und das Einrichten von Shutdown-Hooks für einen sauberen Dienstabschluss. Alles läuft auf der JVM, was den Vorteil hat, dass das System sowohl performant als auch plattformübergreifend ausgeführt werden kann. Historisch gesehen nutzte Kafka Zookeeper für die Koordination und das Management clusterweiter Metadaten. Zookeeper war dabei eine Art zentraler Speicher für Informationen über Cluster-Zustände, zum Beispiel welche Broker verfügbar sind, wer die Leader-Partitionen innehat oder welche ACL-Regeln gelten.
Zookeeper stellt dabei ein hierarchisches, dateisystemähnliches Datenmodell bereit, in dem Kafka seine Informationen ablegt. Dabei gab es auch praktische Möglichkeiten wie sogenannte Watcher, die auf Änderungen an bestimmten Datenknoten reagieren konnten und so eine eventbasierte Synchronisierung ermöglichten. Die Abhängigkeit von Zookeeper führte allerdings zu Komplexitäten in Aufbau, Betrieb und Skalierung. Aus diesem Grund wurde mit dem KIP-500 das Projekt KRaft eingeleitet, das die komplette Metadatenverwaltung direkt in Kafka integriert. KRaft nutzt das „Raft“-Konsensprotokoll, um in verteilten Systemen einen replizierten Zustand sicherzustellen – eine bewährte Lösung, die beispielsweise auch in Kubernetes Anwendung findet.
Dieses Eliminieren von Zookeeper reduziert den operativen Aufwand erheblich und verbessert die Skalierbarkeit, da die Metadaten lokal auf den Brokern gehalten und synchronisiert werden. Wie genau sieht der Übergang aus und wie erkennt Kafka, ob Zookeeper benötigt wird? Das geschieht anhand der Konfiguration: Sobald die Eigenschaft process.roles gesetzt ist, arbeitet Kafka im KRaft-Modus. An diesem Punkt wird eine andere Server-Implementierung geladen: KafkaRaftServer statt KafkaServer. Diese neue Architektur baut die Steuerung und Kommunikation komplett innerhalb von Kafka auf, was das System zukünftig leichter erweiterbar und wartbar macht.
Ein weiterer faszinierender Teil der Kafka-Codebasis ist das Netzwerkmangement. Kafka verwendet java.nio Channels und arbeitet mit einem asynchronen, nicht blockierenden Modell, das es ermöglicht, Tausende von Verbindungen mit nur wenigen Threads effizient zu bedienen. Die Kommunikation zwischen Clients und Brokern basiert auf einem eigenen TCP-Protokoll, das verschiedene Listener-Konfigurationen unterstützt, etwa PLAINTEXT oder SSL-verschlüsselte Verbindungen. Im Betrieb wird jede Listener-Verbindung durch einen Acceptor-Thread überwacht, der eingehende Verbindungsanfragen akzeptiert.
Diese werden per Round-Robin an sogenannte Prozessor-Threads verteilt, welche die zugehörigen Datenströme bearbeiten. Für die weitere Verarbeitung gibt es Handler-Threads, die eigentliche Anfragen wie Fetch oder Produce auswerten und die passenden Aktionen auslösen. Dieses fein abgestimmte Zusammenspiel aus Acceptor, Processor und Handler ermöglicht eine hohe Parallelität und Latenzoptimierung. Innerhalb des Processors übernimmt eine spezielle Komponente namens Selector das Event-Handling für die Socket-Kanäle. Sie prüft, ob Daten bereitstehen, ohne dabei zu blockieren, und löst bei Bedarf Verarbeitungsroutinen aus.
Alle eingehenden Anfragen passieren dann einen zentralen RequestChannel, der eine threadsichere Warteschlange darstellt und sicherstellt, dass die Anzahl gleichzeitig verarbeiteter Anfragen kontrolliert bleibt. So wird das System vor Überlast geschützt. Nachdem die Anfrage den Handler erreicht hat, erfolgt die eigentliche Verarbeitung. Bei einer Produce-Anfrage beispielsweise übergibt Kafka die Daten an den LogManager, der sich um die Speicherung und Verwaltung der Log-Dateien kümmert. Kafka nutzt hier ein cleveres Konzept der Partitionierung.
Jeder Topic-Partition ist ein Verzeichnis zugeordnet, in dem sogenannte Segmente liegen. Diese bestehen aus Log-Dateien, Index-Dateien und Zeitindex-Dateien, die zusammen eine schnelle Suche, Denormalisierung und effizientes Lesen ermöglichen. Die Log-Dateien enthalten die Nachrichtendaten, während die Offset-Indizes und Zeit-Indizes dazu dienen, den Inhalt schnell anhand von Offsets oder Zeitstempeln zu lokalisieren. Diese Indexdateien werden durch den Einsatz von mmap in den Speicher abgebildet, was extrem schnelle Zugriffe erlaubt, ohne den Speicher übermäßig zu belasten. Das System schreibt neue Nachrichten zunächst in den Speicher und schreibt sie später periodisch auf die Festplatte, was für eine hohe Schreibperformance sorgt.
Regelmäßige Aufgaben wie das Löschen veralteter Logs, das Kompaktieren von Daten oder das Flushen der Speicherinhalte werden über den LogManager gesteuert. Für diese Mechanismen werden geplante Hintergrundprozesse eingerichtet, die periodisch die gespeicherten Partitionen überwachen und gegebenenfalls Maßnahmen einleiten. So bleibt das System performant und befreit sich automatisch von überflüssigen Daten. Detailliert betrachtet ist das Log-Management eines der komplexeren und zugleich spannendsten Bestandteile im Kafka-Code. Durch die Kombination von Java-File-Channels für die Datenspeicherung, MappedByteBuffer für die Indizes und nebenläufiger Verwaltung versetzt sich Kafka in die Lage, anspruchsvolle Workloads zu bewältigen – von hochfrequenten Schreibvorgängen bis hin zu schnellen Suchanfragen.
Die Abfolge einer Produce-Anfrage verdeutlicht sehr gut, wie die einzelnen Kafka-Komponenten zusammenwirken. Ausgehend von der Netzwerk-Schicht gelangen die empfangenen Daten über den RequestChannel zum Handler, der die Produzenten-Anfrage identifiziert. Anschließend erfolgt eine Reihe von methodischen Aufrufen, die alle das Ziel haben, die Daten in der richtigen Partition und im dazugehörigen UnifiedLog abzuspeichern. UnifiedLog ist eine Abstraktion, die sowohl lokale als auch fernliegende Log-Speicher verwalten kann und zum Beispiel für das geplante Tiered Storage eingesetzt wird. Die Art des Zugriffs auf Indizes ist dabei besonders effizient, weil Kafka über implementierte binäre Suchalgorithmen auf den gemappten Index-Dateien blitzschnell die genauen Positionen der gewünschten Nachrichten ermitteln kann.
Das Zusammenspiel aus In-Memory-Mapping, Concurrency-Safe-Collections und bewährten Suchalgorithmen macht Kafka so performant und skalierbar. Zusammengefasst bietet der Blick in die Interna von Apache Kafka eine beeindruckende Analyse moderner Softwarearchitektur. Es zeigt sich, wie ein Open-Source-Projekt, das auf traditionellen Java-Technologien aufbaut, durch intelligente Abstraktionen und clevere Systementwürfe großen Mehrwert schafft. Die Transformation von einem Zookeeper-abhängigen System hin zu KRaft dokumentiert auch die Innovationskraft und Anpassungsfähigkeit der Kafka-Community an neue Herausforderungen. Für Entwickler, die sich mit Streaming-Architekturen beschäftigen, bietet Kafka ein solides Fundament, das sich erweitern, anpassen und studieren lässt.
Die offene Codebasis ist ein echtes Lehrbuch für verteilte Systeme, nicht-blockierende Netzwerk-Programmierung und effizientes Dateimanagement. Die Exploration von Kafka ermöglicht nicht nur Einsichten in ein hochentwickeltes Produktivsystem, sondern eröffnet auch viele Möglichkeiten für eigene Experimente, Optimierungen und Beiträge zur stetigen Weiterentwicklung einer der wichtigsten Plattformen für Streaming-Daten der heutigen Zeit.