Die Welt der Künstlichen Intelligenz (KI) und insbesondere der großen Sprachmodelle (Large Language Models, LLMs) erlebt gegenwärtig eine beispiellose Evolution. Traditionelle Transformer-Modelle, die in den vergangenen Jahren die Aufmerksamkeit der Forschung und Industrie auf sich gezogen haben, stoßen beim Verarbeiten großer Textmengen an fundamentale Grenzen. Das wichtigste technische Hindernis dabei ist die quadratische Komplexität der Self-Attention-Mechanismen, die exponentiell mit der Länge des Eingabetextes ansteigt und somit den Speicher- und Rechenaufwand stark limitiert. Dies erschwert das Arbeiten mit Kontexten, die über mehrere tausend Token hinausgehen, und macht ultra-lange Kontextfenster praktisch nicht nutzbar. In diesem Zusammenhang sticht eine neue Forschung heraus, die mit einem völlig anderen, non-attention-basierten Ansatz die Quadratische Barriere durchbricht und damit Kontext-Längen im Bereich von Hunderttausenden bis hin zu potenziell Millionen von Token ermöglicht.
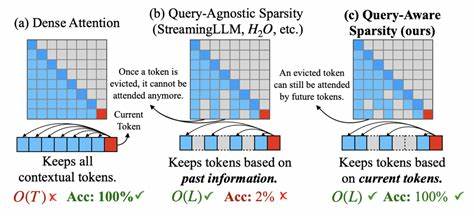
Dieser innovative Ansatz ist nicht nur ein Meilenstein für die AI-Forschung, sondern erlaubt auch praktische Anwendungen, die bisher nicht realisierbar waren. Die klassische Transformer-Architektur ist gebaut auf dem Prinzip der Self-Attention. Dabei werden die Beziehungen jedes einzelnen Tokens mit allen anderen Tokens im Eingabesequenz gemessen, was bei langen Texten zu einem quadratischen Anstieg der erforderlichen Rechenressourcen führt. Das hat trotz einiger Optimierungsversuche klare Grenzen bei der maximal verarbeitbaren Textlänge gesetzt. Forscher Andrew Kiruluta, Preethi Raju und Priscilla Burity schlagen mit ihrem Ansatz eine grundlegend neue Richtung vor, indem sie gänzlich auf token-zu-token-Attention verzichten.
Dies ermöglicht es, die Längenskala von Kontextfenstern nahezu linear zu skalieren, ein Quantensprung für Anwendungen, die auf extrem lange Dokumente angewiesen sind. Im Kern ihres Modells stehen verschiedene innovative Komponenten, die zusammenarbeiten, um Effizienz und Leistungsfähigkeit zu steigern. Die sogenannten State Space Blocks, inspiriert durch die S4-Architektur, spielen dabei eine zentrale Rolle. Diese Blöcke lernen kontinuierliche Zeitfaltungskerne, die sich perfekt eignen, um Sequenzen über lange Zeiträume hinweg effizient zu repräsentieren. Anders als Self-Attention operieren diese Strukturen nahezu linear mit der Länge der Sequenz.
Das heißt, egal wie viele Tokens hinzugefügt werden, der Rechenaufwand steigt nur minimal an. Zusätzlich integrieren die Forscher sogenannte Multi Resolution Convolution Layers. Diese Schichten erfassen lokale Kontexte auf verschiedenen Ebenen der Dilation, also der Ausdehnung der Filter. Dadurch können feingranulare Details ebenso verarbeitet werden wie übergeordnete grobe Zusammenhänge, was bei der Verarbeitung von Sprache essentiell ist. Diese mehrstufige Betrachtung sorgt dafür, dass sowohl kleinere tokenübergreifende Muster als auch größere semantische Zusammenhänge erkannt werden können.
Ein weiterer wichtiger Baustein ist ein ressourcenschonender Recurrent Supervisor. Dieser hält einen globalen versteckten Zustand über mehrere aufeinanderfolgende Datenabschnitte hinweg aufrecht. In der Praxis bedeutet das, dass das Modell kontinuierlich Informationen von vorherigen Teilen eines ultra-langen Textes speichert und mit neu ankommenden Daten kombiniert. Statt jeden Abschnitt isoliert zu betrachten, entsteht so eine kohärente und globale Sicht auf schriftliche Inhalte, die bisher in Modellen mit kürzeren Kontextfenstern nicht realisierbar war. Das System nutzt zudem eine Retrieval-Augmented External Memory, ein externes Speicher konzept, das hochdimensionale Chunk-Embeddings speichert und bei Bedarf abrufen kann.
Dabei wird vermieden, dass quadratic operations erneut in den Prozess eingeführt werden, was wiederum den Rechenaufwand reduziert. Dieses externe Gedächtnis ermöglicht es, gewaltige Mengen von Kontextinformationen handhabbar zu machen, ohne die Rechenperformance einzubüßen. Die Kombination dieser Komponenten eröffnet völlig neue Perspektiven für den Einsatz von Sprach-KI in unterschiedlichsten Bereichen. Anwendungen, die bislang von der Begrenzung des Kontextfensters ausgebremst wurden, profitieren unmittelbar. Dazu zählen unter anderem die Analyse und Verarbeitung umfangreicher wissenschaftlicher Publikationen, bei denen Zusammenhänge über sehr lange Textpassagen hinweg gezogen werden müssen.
Auch in der juristischen Dokumentenanalyse kann das Modell wesentlich tiefere Einblicke bieten, da ganze Gesetzessammlungen oder Gerichtsurteile „ganzheitlich“ verarbeitet werden können. Darüber hinaus könnten Chatbots und assistive KI-Systeme mit deutlich mehr Kontextwissen agieren. Bislang bekannte Systeme verlieren bei sehr langen Gesprächen oder umfangreichen Dokumenteneinbindungen schnell den Überblick. Die non-attention-basierte Architektur könnte dem entgegenwirken, indem globale Zustände über gesamte Kommunikationsverläufe gespeichert werden. So wird die Dialogqualität deutlich verbessert und die Nutzererfahrung natürlicher und informativer.
Auch der kreative Bereich der KI-generierten Texte könnte durch diese Technologie profitieren. Autoren und Content-Creator sind oft beschränkt durch die Größe des zugrundeliegenden Sprachmodells hinsichtlich Storytelling über längere Passagen. Ein Modell, das mühelos Millionen Tokens verarbeiten kann, eröffnet Raum für komplexe narrative Strukturen und fein abgestimmte Charakterentwicklungen, die sich über weite Teile eines Dokuments erstrecken. Dies kann maßgeblich die Qualität und Varietät von KI-generierten Werken heben. Technisch gesehen ist der Schritt weg von Attention und hin zu State Space Modellen ein Paradigmenwechsel, der möglicherweise das Fundament für die nächste Generation von großen Sprachmodellen legen wird.
Die Transformer-Architektur ist seit ihrer Einführung das dominierende Modell. Doch der steigende Bedarf nach längeren Kontexten macht traditionelle Ansätze immer ineffizienter und unbequemer. Die hier vorgestellte Architektur mit ihren modularen Komponenten ist ein vielversprechender Weg, um diese Skalierungsproblematik zu lösen. Die Relevanz dieses Ansatzes zeigt sich auch an der wachsenden Forschungslandschaft im Bereich non-attention Modelle. State Space Modelle und ihre Derivate werden zunehmend erforscht, da sie kontinuierliche Repräsentationen erlauben, die neben Effizienz auch neue Arten von Induktivbias einführen können.
Das Potenzial, sozusagen „zeitkontinuierliche“ Abhängigkeiten über riesige Sequenzen zu modellieren, erhöht die Präzision in komplexen Aufgaben erheblich. Natürlich steht diese Technologie noch am Anfang und es gibt Herausforderungen, die in zukünftigen Studien adressiert werden müssen. Beispielsweise ist die Implementierung und das optimale Training solcher komplexen Hybridsysteme anspruchsvoll. Auch die praktische Integration in bestehende Softwareinfrastrukturen muss sorgfältig erfolgen. Dennoch zeigt das vorliegende Modell, dass es möglich ist, die enormen Beschränkungen der quadratisch skalierenden Self-Attention ohne Verzicht auf Modellqualität zu überwinden.
Die Implikationen dieser Forschung sind weitreichend. Wissenschaft, Recht, Medien, Kommunikation und viele weitere Felder können von dieser neuen Technologie profitieren. Das Modell bietet die Grundlage, natürliche Sprache in bisher ungekanntem Umfang und Tiefe zu verstehen und zu verarbeiten. Dies wird sicher auch den Weg für noch intelligentere und anpassungsfähige KI-Systeme ebnen. Zusammenfassend lässt sich sagen, dass die überwindung der quadratischen Barriere durch einen non-attention-basierten Ansatz in großen Sprachmodellen einen bedeutenden Fortschritt darstellt.
Die Kombination aus State Space Blocks, Multi Resolution Convolution, Recurrent Supervisor und externem Retrieval-Speicher verspricht sowohl Effizienz als auch Skalierbarkeit für ultra-lange Kontextfenster. Damit eröffnet sich eine neue Ära in der Entwicklung und Anwendung von Künstlicher Intelligenz, deren volle Wirkung erst noch erkannt und genutzt werden wird.