Künstliche Intelligenz (KI) und insbesondere große Sprachmodelle (Large Language Models, LLMs) haben in den letzten Jahren eine bemerkenswerte Aufmerksamkeit erhalten. Trotz ihres enormen Potenzials und der rasanten Weiterentwicklung bleiben ihre inneren Abläufe für viele Menschen, vor allem für jene ohne technischen Hintergrund, schwer nachvollziehbar. Ein besonders wichtiger technische Baustein hinter diesen Systemen ist der Transformer, der als Herzstück moderner Sprachmodelle gilt. Um die komplexe Technologie verständlich zu machen, nutzen Experten vereinfacht gesagt die Analogie einer Fabrik, die den Ablauf vom Rohmaterial bis zum fertigen Produkt visualisiert. Mit dieser Vorstellung wird die Arbeitsweise eines Transformers und eines LLMs anschaulich und greifbar – auch für Laien, die sich für KI interessieren, aber keine Informatiker sind.
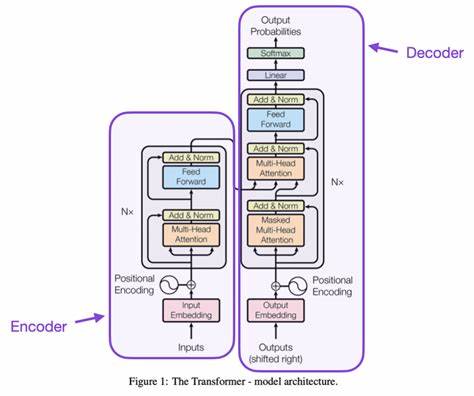
Die Grundlage eines großen Sprachmodells ist die Eingabe von Text in Form von Wörtern. Man kann sich das vorstellen wie eine Lieferung von Rohmaterial am Ladehof einer Fabrik. Die einzelnen Wörter des Textes werden zunächst in eine numerische Form gebracht – in sogenannte Vektoren. Diese Umwandlung wird als Wortembedding bezeichnet und ist vergleichbar mit dem Entladen und Erkennen der Materialien am Ladehof. Jedes Wort erhält dabei eine Art Zahlenprofil, das seine Bedeutung im Kontext der KI repräsentiert.
Anschließend kommen auf der Fabriksequenz Arbeiter zum Einsatz, die jedem Wortvektor einen Reihenfolgenvermerk geben. Diese Schritt ist als Positionscodierung (Positional Encoding) bekannt. Die KI muss nämlich wissen, in welcher Reihenfolge die Worte im Satz stehen, denn die Bedeutung eines Satzes hängt stark von seinem Aufbau ab. Ohne diese Positionierung würde die Maschine den Zusammenhang verlieren und Textinhalte falsch interpretieren. Man kann sich das so vorstellen, als ob die Arbeiter jedem Material eine Seriennummer anheften, damit es später richtig verarbeitet wird.
Im Herzen des Transformers befinden sich dann zwei Ebenen von Aufsichtspersonal, vergleichbar mit Managern, die in der Fabrik den Arbeitsfluss steuern. Die sogenannten Multi-Headed Attention-Module wirken wie hochrangige Supervisoren, die gleichzeitig verschiedene Informationsströme beobachten und sicherstellen, dass relevante Zusammenhänge zwischen den Worten erfasst werden. Diese mehrköpfige Aufmerksamkeit ermöglicht es der KI, unterschiedliche Blickwinkel gleichzeitig zu analysieren und Verbindungen zu erkennen, die für das Verständnis von Kontext und Bedeutung entscheidend sind. Auf einer anderen Ebene gibt es die Self-Attention, übersetzt als Selbstaufmerksamkeit. Diese analog zu niedrigeren Aufsehern sorgt dafür, dass jedes Wort innerhalb des Eingabestroms seine Beziehung zu allen anderen Wörtern analysiert.
Auf diese Weise versteht die Maschine zum Beispiel, dass sich das Wort „es“ eher auf „backen“ als auf „Kirsche“ bezieht, wenn im Satz die Rede davon ist, wie man einen Kirschkuchen zubereitet. Diese Prozess erlaubt es, klare Zusammenhänge zu erfassen, selbst wenn die Wörter räumlich voneinander entfernt sind. Die gesammelten Informationen werden dann von sogenannten Analysten verarbeitet, die komplexe Berechnungen durchführen und erste Ergebnisse in numerischer Form zusammenfassen. Diese Phase entspricht neuronalen Netzwerken, die aus den eingegebenen Vektoren und Relationen die wichtigsten Merkmale extrahieren und neue Datenmuster ableiten. Das Ergebnis ist eine Art vorläufiger Bauplan für die endgültige Textantwort, allerdings noch in rein mathematischer Form.
Zudem gibt es im Transformer sogenannte Residual Connections, die man sich wie Expediteure vorstellen kann, welche fortwährend überprüfen, ob die neuen Ergebnisse mit den ursprünglichen Eingaben übereinstimmen. Dieser Mechanismus sorgt für einen verbesserten Informationsfluss und verhindert den Verlust wichtiger Daten während der Verarbeitung. Dadurch wird die Stabilität und Genauigkeit des Modells deutlich erhöht. Die eigentliche Produktion erfolgt in mehreren aufeinanderfolgenden Schichten, vergleichbar mit mehreren Teams von Arbeitern und Assemblierern, die das Produkt Schritt für Schritt verfeinern. Bei jedem Durchlauf verbessern die Maschinen die Verarbeitungsergebnisse und verfeinern den Output.
Erst nachdem alle Stufen durchlaufen sind, kommt der finale Prozess – das Zusammensetzen des verständlichen Textes. Die Zahlenwerte werden zurück in lesbaren Text übersetzt, den die Nutzer dann sehen und verstehen können. Diese Fabrik-Analogie erleichtert das Verständnis von komplexen KI-Prozessen erheblich. Obwohl sie nicht jedes technische Detail abbildet, gibt sie eine klare Vorstellung, wie große Sprachmodelle arbeiten, warum Transformer so revolutionär sind und wie sie in verschiedenen Branchen eingesetzt werden können. Geschäftsleute, Lehrkräfte und interessierte Laien können dank solcher vereinfachten Darstellungen ein grundlegendes Verständnis aufbauen, das für die professionelle Nutzung und Bewertung von KI-Technologien entscheidend ist.
Darüber hinaus zeigen große Sprachmodelle, die auf Transformer basieren, eine beeindruckende Flexibilität. Sie sind in der Lage, verschiedenste Aufgaben zu bewältigen – von Textübersetzung und Textgenerierung über Beantwortung komplexer Fragen bis hin zur Analyse großer Datenmengen. Die zugrundeliegende Technologie ermöglicht es, den Kontext über lange Textabschnitte hinweg zu erfassen und sinnvolle Verbindungen herzustellen, was zuvor in der KI-Forschung als äußerst herausfordernd galt. Der steigende Gebrauch von Transformers stimuliert auch die Entwicklung neuer KI-Anwendungen und verändert die Art und Weise, wie Unternehmen mit ihren Daten umgehen. Beispielsweise können Kundendienstsysteme durch den Einsatz großer Sprachmodelle personalisierter und effizienter werden.
Auch in der Medizin, im Bildungswesen und der Forschung eröffnen sich neue Möglichkeiten, indem große Mengen an Informationen schnell und präzise verarbeitet und verständlich aufbereitet werden. Trotz der enormen Fortschritte bleibt es wichtig, die Grenzen und Herausforderungen der Technologie nicht außer Acht zu lassen. Ein Transformer kann nur so gut sein wie die Daten, mit denen er trainiert wurde. Zudem spielt die riesige Rechenleistung, die für Training und Betrieb erforderlich ist, eine entscheidende Rolle. Nicht jeder Interessierte hat Zugriff auf entsprechende Hardwareressourcen, was die Entwicklung im Bereich KI teilweise bremst.
Nichtsdestotrotz zeigt die Veranschaulichung der komplexen Abläufe mittels einer Fabrik-Analogie, dass die Auseinandersetzung mit großen Sprachmodellen und Transformer-Technologien auch für weniger technisch versierte Menschen zugänglich gemacht werden kann. Dieses Prinzip ist entscheidend, um die Akzeptanz und das Verständnis von KI in Gesellschaft und Wirtschaft zu stärken. Letztlich sprechen wir bei Transformern und LLMs von innovativen Systemen, die mithilfe moderner Algorithmen menschliche Sprache auf eine Art und Weise verstehen und erzeugen können, die vor wenigen Jahren noch undenkbar schien. Die Nutzung dieser Technologie wird in Zukunft weitere Bereiche unseres Lebens und Arbeitens transformieren – vom Alltag über die Forschung bis hin zu komplexen Geschäftsanwendungen. Das Erlernen der Grundlagen mit Hilfe anschaulicher Analogien ist daher ein wichtiger erster Schritt für alle, die sich mit Künstlicher Intelligenz auseinandersetzen möchten.
Nur so kann ein breiter Dialog gefördert werden, der sowohl Chancen als auch Herausforderungen dieser Technologie transparent macht und letztlich zu einer verantwortungsvollen Nutzung beiträgt.