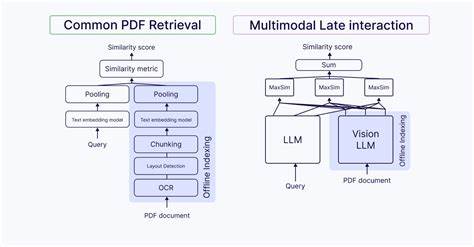
In der heutigen Ära der digitalen Informationsflut steigen die Anforderungen an Such- und Retrieval-Technologien rasant an. Insbesondere bei der Verarbeitung von multimodalen Daten – also Kombinationen aus Text, Bildern, Tabellen, Diagrammen und weiteren visuellen Inhalten – stoßen herkömmliche Suchmodelle schnell an ihre Grenzen. Hier kommen multimodale Late Interaction Modelle ins Spiel, die eine neue Dimension der semantischen Suchpräzision und Dokumentenverarbeitung ermöglichen. Diese Modelle sind speziell darauf ausgelegt, die Komplexität und Vielfalt moderner Dokumente zu bewältigen. Anders als klassische dichte Vektor-Modelle, die Inhalte in einer einzigen, zusammengefassten Repräsentation kodieren, bewahren Late Interaction Modelle die granularen Details von Texttokens oder Bild-Patches.
Dadurch ist eine differenzierte und kontextbewusste Analyse möglich, die den tatsächlichen Informationsgehalt von komplexen Dokumenten deutlich genauer erfasst. Eine der zentralen Herausforderungen bei der Arbeit mit multimodalen Daten besteht darin, dass visuelle Elemente wie Diagramme, Tabellen oder eingebettete Bilder oft in unmittelbarem Kontext zu Texten stehen, deren Bedeutung sich nur durch eine gemeinsame Betrachtung erschließt. So kann eine dichte Vektorreduktion dafür sorgen, dass etwa die Information über die Art eines Diagramms oder die Verbindung zwischen einer Tabelle und ihrer bildlichen Darstellung verloren geht. Late Interaction Modelle umgehen dieses Problem, indem sie verschiedene Datenmodalitäten auf Token- oder Patch-Ebene embedden und in einem gemeinsamen semantischen Raum verknüpfen. Die Funktionsweise basiert auf der Idee der Mehrvektor- oder Multi-Vector-Repräsentation.
Ein Dokument wird nicht als ein einzelner Vektor repräsentiert, sondern durch eine Sammlung von Vektoren, die einzelne Komponenten oder Segmente abbilden. Das ermöglicht, bei der Suchanfrage eine sehr feingranulare Ähnlichkeitsberechnung auszuführen, bei der einzelne Suchbegriffe oder Bildbeschreibungen individuell mit den entsprechenden Text- oder Bildabschnitten abgeglichen werden. Als zentraler Operator kommt hierbei der sogenannte MaxSim-Algorithmus zum Einsatz, der aus einer Menge von Ähnlichkeiten zwischen Tokens oder Patches die höchste Relevanz für das Ergebnis herausfiltert. Diese Herangehensweise ist besonders wertvoll bei Anwendungen wie der Suche in wissenschaftlichen Arbeiten, Finanzberichten oder gescannten PDFs, in denen visuelle und textuelle Inhalte eng miteinander verwoben sind. So lassen sich gezielt Seiten mit spezifischen Diagrammtypen, Tabellen inklusive passender Erläuterungstexte oder auch Abschnitte mit Referenzen auf bestimmte Abbildungen auffinden – eine Aufgabe, die mit traditionellen dicht aggregierten Vektoren oftmals unzureichend gelöst werden kann.
Beispiele wichtiger Modelle aus diesem Bereich sind ColBERT, welches auf BERT basiert und vornehmlich Textdokumente mit Late Interaction bearbeitet, sowie ColPaLI und ColQwen, die den Ansatz multimodal erweitern und Bilder sowie gescannte Dokumente als Eingabe berücksichtigen. ColPaLI arbeitet mit PaliGemma und ermöglicht das Einbringen visueller Patch-Embeddings in Suchprozesse, während ColQwen als schlankere, effiziente Variante mit kleineren Eingabepatches und permissiver Lizenzierung dient. Neben der verbesserten Treffergenauigkeit schaffen diese Modelle Transparenz und Nachvollziehbarkeit, indem sie sichtbar machen, welche einzelnen Tokens oder Bildsegmente zur Wahrscheinlichkeit eines Suchergebnisses beitragen. Dies erleichtert nicht nur die systemseitige Erklärbarkeit, sondern gibt Endanwendern Vertrauen in die Funktionsweise und die ermittelten Resultate. Allerdings bringen multimodale Late Interaction Modelle auch technische Herausforderungen mit sich.
Insbesondere der Speicherbedarf wächst durch die Speicherung vieler Vektoren pro Dokument erheblich an. Zudem sind viele etablierte Vektor-Datenbanken nicht auf den Umgang mit Multi-Vector-Indizes optimiert, was die Sucheinflüsse, Skalierbarkeit und Performance beeinflussen kann. Die rechenintensive MaxSim-Operation erfordert zudem ein optimiertes Inferenz-Management, um in produktiven Umgebungen effiziente Laufzeiten zu gewährleisten. Ein weiterer kritischer Punkt ist die sogenannte cross-modale Alignment-Technologie, die sicherstellt, dass Text- und Bildinformationen in einen einheitlichen semantischen Raum eingebettet werden und vergleichbar sind. Um diese Herausforderungen produktiv zu adressieren, sind spezialisierte Infrastruktur- Anbieter und Softwarelösungen entstanden, die multimodale Late Interaction auf Enterprise-Niveau umsetzen.
Mixpeek ist ein solcher Anbieter, der es ermöglicht, multimodale Inhalte aus unterschiedlichen Quellen wie PDFs, Videos, Bildern und Audio nahtlos zu indexieren und hochperformant abzufragen. Dabei integriert Mixpeek fortschrittliche Feature-Extraktoren sowie Late Interaction Modelle, unterstützt Multi-Vector-Indizes und bietet umfangreiche Tools für Monitoring, Evaluation und Upgrade-Management. So erhalten Unternehmen eine robuste und flexible Plattform, um multimodale Suche und Retrieval in realen Anwendungsszenarien einzusetzen. Im Fazit lässt sich festhalten, dass multimodale Late Interaction Modelle die Grenzen traditioneller Suche sprengen und eine tiefgreifende semantische Analyse verschiedenartiger Inhalte ermöglichen. Gerade in Branchen wie Finanzdienstleistungen, Forschung, Recht und Medienproduktion, wo Dokumente oft komplex strukturiert und multimedial sind, eröffnen diese Technologien völlig neue Möglichkeiten.
Die Fähigkeit, Text und Bild gemeinsam und granular zu verarbeiten, erlaubt es Entwicklern und Unternehmen, präzisere, erklärbare und leistungsfähigere Suchanwendungen zu schaffen, die dem Nutzer Mehrwert und Effizienz bringen. Durch kontinuierliche Forschung, technologische Innovationen und die Entwicklung spezialisierter Infrastruktur wächst das Potenzial von multimodalen Late Interaction Modellen beständig. Sie stehen exemplarisch für den Wandel hin zu KI-gestützten Systemen, die Inhalte nicht nur oberflächlich durchsuchen, sondern deren Bedeutung und Struktur wirklich erfassen – für ein umfassendes, zukunftsfähiges Informationsmanagement.