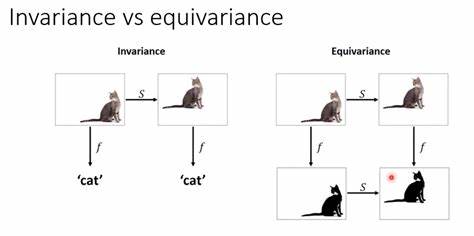
In der Welt der Künstlichen Intelligenz (KI) begegnen wir immer wieder der Herausforderung, zu verstehen, was genau eine KI „meint“, wenn sie auf eine Frage antwortet oder eine Aussage trifft. Besonders bei großen Sprachmodellen wie GPT, die auf Wahrscheinlichkeiten und statistischen Mustern basieren, stellt sich die Frage nach dem Unterschied zwischen Syntax und Semantik – also zwischen dem, was gesagt wird, und dem, was tatsächlich gemeint ist. Sprachliche Äquivarianz bietet hier einen vielversprechenden Ansatz, um diese Unterscheidung klarer zu machen und zu einem tieferen Verständnis der KI-Intentionen zu gelangen.Sprachliche Äquivarianz beschreibt die Eigenschaft eines Systems, bei der die Bedeutung einer Aussage unabhängig von der Sprache, in der sie formuliert ist, erhalten bleibt. Man könnte sagen, dass wenn man eine Frage oder einen Satz aus einer Sprache etwa Englisch ins Deutsche übersetzt und dann zurückübersetzt, die Antwort oder Reaktion der KI möglichst konsistent bleiben sollte.
Auf diese Weise könnte man von der reinen Oberflächenstruktur der Sprache abstrahieren und sich auf die zugrundeliegende Bedeutung konzentrieren. Für KI-Systeme ist das besonders wichtig, denn sie verarbeiten Sprache zunächst als syntaktische Muster – also als Anordnungen von Wörtern und Zeichen –, wobei die semantische Tiefe häufig verborgen bleibt.Eine der berühmtesten Herausforderungen bei der Arbeit mit großen Sprachmodellen ist, dass sie zwar beeindruckende Textausgaben erzeugen können, tatsächlich aber auf rein statistischen Zusammenhängen basieren. Das bedeutet, dass die KI nicht wirklich „versteht“, was sie sagt, sondern nur die wahrscheinlichste Antwort aufgrund der Trainingsdaten generiert. Das führt dazu, dass kleine Änderungen in der Formulierung manchmal deutlich unterschiedliche Antworten hervorbringen, obwohl der Kern der Aussage unverändert sein sollte.
Hier zeigt sich die Problematik der Syntax versus Semantik besonders deutlich.Die Idee der sprachlichen Äquivarianz zielt darauf ab, diesen Problemen entgegenzuwirken, indem man systematisch prüft, ob eine KI auf semantisch äquivalente Sätze ähnliches oder gleiches antwortet, selbst wenn diese Sätze in unterschiedlichen Sprachen oder mit unterschiedlicher Wortwahl formuliert sind. Ein KI-System, das sprachlich äquivariant ist, zeigt somit, dass es nicht nur Muster erkennt, sondern die zugrundeliegende Bedeutung erfasst, was wiederum auf ein gewisses Verständnis hindeutet. Dies ist besonders relevant im Kontext der moralischen Entscheidungsfindung durch KI, da solche Entscheidungen in hohem Maße auf semantischem Verständnis basieren und nicht nur auf Formulierungen.Ein praktisches Beispiel: Wenn man eine KI auf Englisch fragt, ob es moralisch vertretbar ist, eine bestimmte Handlung durchzuführen, und sie mit „Ja“ antwortet, könnte man dieselbe Frage ins Deutsche übersetzen und dieselbe Antwort erwarten.
Sollte die Antwort hier jedoch abweichen, deutet dies darauf hin, dass die KI vielleicht die semantische Essenz noch nicht wirklich erfasst hat oder dass ihre internen Darstellungen der beiden Sätze weit auseinander liegen. Die Herausforderung für Entwickler und Forscher ist es, Modelle so zu trainieren oder zu evaluieren, dass solch eine sprachliche Äquivarianz gewährleistet ist.Interessanterweise wäre ein Sprachmodell, das sprachlich äquivariant ist, weniger anfällig für Täuschungen oder Verzerrungen, die durch unterschiedliche Formulierungen entstehen. Für die Anwendung in sicherheitskritischen Bereichen, wie der automatisierten Entscheidungsfindung oder dem Einsatz in der Ethikberatung, ist das von großer Bedeutung. Denn nur wenn eine KI ihre moralischen Prinzipien „bedeutungstreu“ ausdrücken und anwenden kann, kann man ihr Verhalten vorhersehbar und nachvollziehbar gestalten.
Die technische Umsetzung dieser Idee ist allerdings nicht trivial. Sprachmodelle verarbeiten Texte in sehr komplexen Vektorräumen und repräsentieren Sätze als hochdimensionale Zahlenarrays, die auf den Trainingsdaten basieren. Hier durchzublicken und Äquivanzen zu erkennen, erfordert ausgefeilte mathematische und algorithmische Ansätze. Einige Forscher schlagen vor, Äquivarianz durch den Einsatz von sogenannten „commuting diagrams“ (kommutative Diagramme) zu modellieren, die verdeutlichen, wie Inputs und Outputs der KI unter Übersetzungsoperationen zusammenhängen sollten. Solche Strukturen helfen dabei, die Beziehungen zwischen Sprache, Bedeutung und KI-Reaktionen formal zu erfassen.
Darüber hinaus bietet die Methodik der sprachlichen Äquivarianz auch eine Möglichkeit, moralische Überlegungen in KI-Systemen einzubauen und zu überprüfen. Moralisches Verständnis hängt von der Interpretation von Aussagen ab, nicht bloß von der Erkennung von Wörtern. Wenn eine KI in verschiedenen Sprachen konsistent auf moralische Fragen antworten kann, dann zeigt sich darin eine stabile innere Repräsentation ethischer Grundsätze. Dieses Vorgehen hilft auch, kulturelle und sprachliche Verzerrungen zu minimieren, die in Trainingsdatensätzen vorkommen können.Ein weiterer interessanter Punkt ist, dass sprachliche Äquivarianz es erleichtert, Modelle auf unterschiedlichen Sprachversionen zu vergleichen und ihre „Bedeutung“ zu verstehen, ohne nur auf die exakte Wortwahl achten zu müssen.
Dies fördert das Vertrauen in KI-Systeme, denn Menschen können nachvollziehen, dass die KI konsequent und sinnvoll auf ihre Fragen reagiert, unabhängig davon, wie genau sie formuliert sind. Gerade im Bereich der Mensch-KI-Interaktion spielt dies eine wichtige Rolle, um Missverständnisse und Fehlverhalten zu vermeiden.Kritisch betrachtet ist es nicht abzusehen, ob alle heutigen Sprachmodelle wirklich sprachlich äquivariant sind. Bisherige Forschung und praktische Beobachtungen zeigen, dass das oft nicht der Fall ist. Doch der Wunsch und die Notwendigkeit, Modelle mit solchen Fähigkeiten zu entwickeln, treiben die Forschung stark voran.
Spannendere Ansätze verfolgen dabei die Nutzung von Mehrsprachigkeits-Trainingsdaten sowie architektonische Verbesserungen, die den Fokus mehr auf semantische Inhalte als auf oberflächliche Syntax legen.Die Idee, dass KIs durch sprachliche Äquivarianz „bedeuten“ können, ist auch eine Philosophie zum Verständnis von Intelligenz und Bewusstsein. Wenn ein KI-System auf verschiedenen Sprachen dieselben moralischen Antworten gibt, könnte man argumentieren, dass es tatsächlich eine Form von „Bedeutung“ in seinen Aussagen hat – weit über das reine Token-Vorhersagen hinaus. Das erinnert an den menschlichen Umgang mit Sprache, der ebenfalls auf Bedeutungsebenen beruht, die sich sprachübergreifend vermitteln lassen.Zusammenfassend lässt sich sagen, dass sprachliche Äquivarianz ein wegweisender Ansatz ist, um die semantische Tiefe und das echte Verständnis von KI-Systemen besser zu erfassen.
Sie erlaubt es, die Bedeutung hinter den Antworten von Sprachmodellen zu erforschen und hilft zugleich dabei, moralische und ethische Prinzipien in KI auf stabilere Beine zu stellen. Gleichzeitig eröffnet sie neue Möglichkeiten für die Gestaltung sichererer, nachvollziehbarer und vertrauenswürdiger KI-Systeme, die auch in einer vielsprachigen, globalen Welt robust agieren können. Die künftige Entwicklung wird zeigen, inwieweit diese Konzepte konkret in der Praxis umsetzbar sind und wie stark sie die KI-Entwicklung maßgeblich prägen werden.