Im Zeitalter moderner Softwareentwicklung stehen verteilte Systeme und Microservices im Mittelpunkt vieler IT-Architekturen. Die Vielzahl an einzelnen Services, die jeweils ihre eigenen Datenbanken verwalten, bringt nicht nur Vorteile in der Modularität mit sich, sondern stellt Entwickler und Infrastrukturteams auch vor komplexe Herausforderungen, besonders wenn es um die Synchronisation von Daten geht. Genau hier setzt ReJot an – ein innovatives Framework für Datenbank-Replikation, das speziell für Entwickler konzipiert wurde und das die Brücke schlägt zwischen synchroner und asynchroner Kommunikation. ReJot versteht sich als die fehlende Mittelweg-Lösung zwischen synchronen Serviceaufrufen wie REST oder SOAP, die oft zu hohen Latenzen und Abhängigkeiten führen, und komplexen asynchronen Event-Streaming-Systemen wie Apache Kafka, die in der Regel mit hohem operativen Aufwand verbunden sind. Dabei nutzt ReJot die vorhandene Datenbank-WAL (Write-Ahead-Log) als Datenquelle für die Replikation.
Diese technische Grundlage erlaubt es, Datenveränderungen direkt aus dem Transaktionslog der Datenbank auszulesen und effizient an andere Services weiterzuleiten. Ein entscheidender Vorteil von ReJot ist die Entwicklerzentrierung. Die gesamte Replikation wird im Code definiert und verwaltet, wobei sogenannte Public Schemas und Consumer Schemas die Grundlage bilden. Public Schemas sorgen dafür, dass die internen Datenmodelle eines Services in wohldefinierte, konsumierbare Transformationen umgewandelt werden. Diese Transformationen sind nicht nur deklarativ, sondern auch eng mit der internen Logik eines Services verbunden.
Consumer Schemas wiederum definieren, wie die Daten am Zielort konsumiert und gespeichert werden. Diese klaren Verträge erlauben Teams, ihre Datenmodelle unabhängig voneinander weiterzuentwickeln, ohne bestehende Datenverflechtungen zu gefährden. So wird eine stabile und nachvollziehbare Kommunikation über Systemgrenzen hinweg gewährleistet. Die Implementierung von ReJot ist auffallend unkompliziert. Entwicklern steht das rechnergestützte Kommandozeilenwerkzeug rejot-cli zur Verfügung, mit dem sie schnell Verbindungen zu Quell- und Ziel-Datenbanken einrichten, Manifeste anlegen und Schemata definieren können.
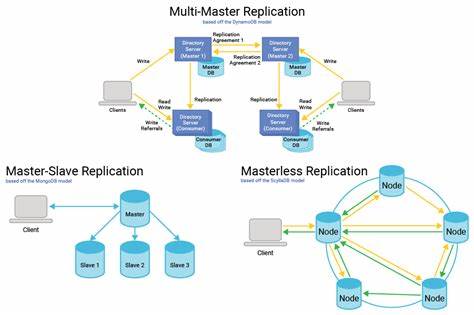
Dabei ist ReJot vor allem auf PostgreSQL ausgelegt, profitiert von dessen logischer Replikationsfunktionalität und setzt auf bewährte Technologien, um eine robuste und performante Datenübertragung zu ermöglichen. Im Detail sorgt der sogenannte Sync Engine für den Abgleich zwischen Quell- und Zielsystem. Er liest das WAL aus, führt die in den Public Schemas definierten Transformationen auf den geänderten Datensätzen aus und schreibt die Ergebnisse in einen Event Store. Dieser Zwischenspeicher dient als dauerhafte und zuverlässige Quelle für die Consumer-Schemas, die wiederum die Daten am Ziel ablegen. Durch diese Architektur entsteht ein asynchroner, aber trotzdem stark konsistenter Datenfluss ohne die üblichen Probleme synchroner API-Aufrufe, wie Blockierungen oder Kettenausfälle.
Die Nutzung von ReJot bringt für Unternehmen und Entwickler vielfältige Vorteile mit sich. Erstens wird die Komplexität der Infrastruktur erheblich reduziert, da kein separates Messaging-System wie Kafka betrieben und gewartet werden muss. Stattdessen nutzt ReJot die bereits bestehende Datenbankinfrastruktur, wodurch sich der operative Overhead minimiert und Kosten gesenkt werden. Zweitens verbessert sich die Ausfallsicherheit der Dienste, da die Replikation asynchron und entkoppelt erfolgt und Fehler im Netzwerk oder bei einzelnen Services das Gesamtsystem nicht blockieren. Drittens bietet ReJot eine hohe Flexibilität bei der Datenmodellierung, da Transformationen im Code definiert und leicht angepasst werden können.
Ein praxisnahes Beispiel für den Einsatz von ReJot findet sich im Demo-Projekt ShopJot. Darin wird eine komplexe Microservice-Architektur simuliert, in der verschiedene Teams eigene Datenbanken verwalten und dennoch Daten effizient synchronisieren müssen. Mit ReJot lassen sich öffentliche Datenmodelle deklarativ definieren und Versionen kontrollieren, sodass selbst bei fortlaufender Weiterentwicklung keine Inkompatibilitäten auftreten. Dieses Szenario zeigt, wie ReJot echten Mehrwert in agilen Entwicklungsumgebungen schafft und dabei die Zusammenarbeit zwischen Teams fördert. Darüber hinaus ist ReJot ein Open-Source-Projekt unter der Apache-2.
0-Lizenz, was es für Entwickler attraktiv macht, eigene Erweiterungen zu erstellen oder direkt zur Verbesserung beizutragen. Die Entwicklung erfolgt aktiv auf GitHub, wo es bereits eine Community aus Nutzern und Mitwirkenden gibt. Die Dokumentation ist ausführlich, und es gibt etablierte Workflows zum Aufbau von Manifests und zum Start der Synchronisation. Technologisch basiert ReJot vor allem auf TypeScript, was im modernen Web- und Backend-Bereich weit verbreitet ist. Die CLI ist mithilfe von Node.
js oder Bun lauffähig, was Flexibilität hinsichtlich Entwicklungsumgebung und Betriebssystemsupport bietet. Für die Persistenz kommen sowohl klassische relationale Datenbanken als auch moderne Event Stores zum Einsatz. Diese Kombination aus bewährten und neuen Technologien sorgt für eine stabile, performante und erweiterbare Plattform. Insgesamt adressiert ReJot ein fundamentales Problem der verteilten Softwaregestaltung: die zuverlässige, performante und wartbare Datenreplikation über Servicegrenzen hinweg. Traditionelle Lösungen setzen oft entweder zu stark auf direkte Kommunikation mit all ihren Nachteilen oder auf komplexe Event-Systeme, die viel Know-how und Infrastruktur erfordern.
ReJot füllt diese Lücke, indem es Datenbank-WALs als nativen asynchronen Kanal nutzt und die gesamte Definition der Datenabhängigkeiten in den Entwicklungscode verlagert. Dies steigert die Agilität, verbessert die Wartbarkeit und reduziert die technischen Risiken. Für Unternehmen, die Microservices einsetzen oder planen, bietet ReJot eine attraktive Möglichkeit, Datenflüsse effizient zu gestalten ohne eigene Messaging-Plattformen einführen zu müssen. Entwickler profitieren von einem klaren und konsistenten Modell, das vier zentrale Anforderungen erfüllt: leichte Handhabung, Skalierbarkeit, Fehlertoleranz und Entwicklervorstellung. Zusätzlich schafft ReJot durch die Verwendung von Manifesten eine Infrastruktur, die Ownership von Daten und Services klar abbildet.
Jede Teameinheit kann ihre eigenen Manifeste verwalten und konsumentenseitig auf entfernte Schemata verweisen. Dies fördert Verantwortlichkeit und Zusammenarbeit, reduziert Konflikte bei Datenmodifikation und vereinfacht Updates. Die Relevanz von ReJot wird in Zeiten wachsender Business-Komplexität und Service-Architekturen immer größer. Während Unternehmen mehr und mehr auf Cloud-native Microservices setzen, wächst auch der Bedarf an robusten Datenintegrationslösungen. ReJot liefert hierfür ein pragmatisches, erprobtes und modernes Konzept, das den Spagat zwischen Entwicklerfreundlichkeit und technischer Leistungsfähigkeit meistert.