Parsing-Techniken bilden das Rückgrat zahlreicher Compiler, Interpreter und Analysewerkzeuge in der Softwareentwicklung. Während klassische rekursiv-absteigende Parser vielen Entwicklern vertraut sind, bietet das Top-Down Operator Precedence Parsing, auch bekannt als Pratt-Parsing, eine faszinierende Alternative. Dieses Verfahren verbindet einfache Strukturen mit optimierter Ausdrucksauswertung, insbesondere bei komplexen grammatikalischen Konstruktionen wie mathematischen oder logischen Ausdrücken. Das Konzept wurde bereits 1973 von Vaughan Pratt entwickelt und hat in den letzten Jahren durch die Popularisierung von Douglas Crockford erneut an Bedeutung gewonnen. Seine Anwendung in realen Projekten wie GCC, Parrot und dem beliebten Javascript-Validator JSLint untermauert seine praktische Relevanz.
Im Kern basiert das Verfahren auf einer Unterscheidung der Operatoren nach deren Bindungsstärke, auch als "binding power" bezeichnet. Diese numerische Kennzahl definiert, wie fest ein Operator an seine Argumente gebunden wird und bestimmt somit die Reihenfolge der Auswertung in verschachtelten Ausdrücken. Dabei ist das entscheidende Prinzip: Der Operator mit höherer Bindungsstärke "gewinnt" und assoziiert den dazwischenliegenden Ausdruck mit sich. Im Gegensatz zu klassischen rekursiv-absteigenden Parsern, die semantische Aktionen an Grammatikkonstruktionen (BNF-Regeln) anhängen, ordnet das Top-Down Operator Precedence Parsing diese Aktionen direkt den einzelnen Tokens zu. Dadurch wird der Code nicht nur schlanker und wartbarer, sondern die Flexibilität bei der Behandlung unterschiedlicher Operatorpositionen erhöht sich deutlich.
Eine wichtige Unterscheidung in diesem Modell ist zwischen Präfix- und Infix-Operatoren. Ein und derselbe Operator kann je nach Kontext unterschiedliche Bedeutungen haben, wie etwa das Minuszeichen, das als Präfix eine Negation und als Infix eine Subtraktion darstellt. Die Token implementieren dazu zwei unterschiedliche Handler: „nud“ (null denotation) für Präfix und „led“ (left denotation) für Infix. Die Parserfunktion selbst arbeitet rekursiv und beachtet dabei die Bindungsstärken, um die Reihenfolge und Tiefe der Auswertung zu steuern. Dabei wird ein rechter Bindungswert (rbp) als Parameter benutzt, der angibt, ab welchem Präzedenzniveau weitere Operatoren aufgenommen werden.
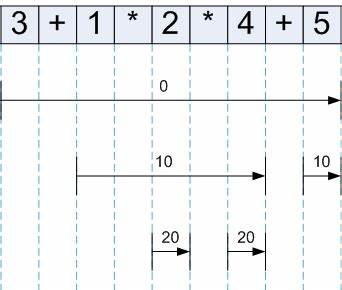
So verhindert der Parser, dass Ausdrücke zu tief oder zu flach ausgewertet werden, und hält sich stets an die festgelegte Operatorpriorität. Ein einfaches Beispiel verdeutlicht den Mechanismus: Ist der Bindungswert des aktuellen Operators kleiner als der des folgenden, wird die Rekursion tiefer ausgeführt, um die höher priorisierten Operationen zuerst auszuwerten. Auf diese Weise entsteht eine optimierte Verarbeitung von Ausdrücken wie "3 + 1 * 2 * 4 + 5", bei der Multiplikationen vor Additionen korrekt ausgewertet werden. Für die praktische Umsetzung werden Token-Klassen definiert, die neben ihrer Bindungsstärke auch eigene Implementierungen für die nud- und led-Methoden mitbringen. Literalwerte benötigen nur eine nud-Methode, da sie als terminale Symbole keine weiteren Argumente auswerten müssen.
Operatoren implementieren jeweils passende led-Methoden zur rechten Argumentauswertung, einige zusätzlich nud-Methoden für Präfixgebrauch. Das Parsing verläuft in einer Schleife, die Tokens so lange verarbeitet, wie deren Bindungsstärke dies erlaubt. Das Einstiegsfunktion „expression“ nimmt einen Standardwert von 0 für den rechten Bindungswert an, um die gesamte Eingabe jeweils vollständig auszuwerten. Schrittweise wandelt der Parser Eingabetext in verschachtelte Ausdrücke um, die durch einfache Python-Operatoren in der Implementierung ausgewertet oder weiterverarbeitet werden können. Die Erweiterung des Parsers zeigt sich besonders klar im Umgang mit unären Operatoren, etwa der negativen Vorzeichenbehandlung.
Durch Ergänzung einer passenden nud-Methode für den Minus-Operator wird das Präfix-Verhalten eingeführt und eine hohe Bindungsstärke garantiert, sodass diese Operationen vor Multiplikation oder Addition ausgeführt werden. Ebenso erlaubt die Technik die Behandlung von Rechtsassoziativität, wie beim Exponentenoperator ^. Durch die Anpassung der Übergabewerte an rekursive Aufrufe kann der Parser steuern, ob aufeinanderfolgende Potenzierungen korrekt von rechts nach links gruppiert werden – ein Problem, das viele klassische Parser mit statischer Grammatikdefinition schwer lösen. Auch Klammerung und Gruppierung werden elegant implementiert. Der linke Klammer-Token fungiert als Präfixtoken und ruft in seiner nud-Methode eine Unterauswertung auf.
Dann wird mit einem einfachen Matching-Mechanismus geprüft, ob nach der Gruppe eine schließende Klammer folgt. Dies ermöglicht die korrekte Handhabung selbst verschachtelter Ausdrücke, ohne dass der Parser unnötig komplex oder unübersichtlich gestaltet werden muss. Im Vergleich zu traditionellen automatischen Parsergeneratoren bietet Top-Down Operator Precedence Parsing einige Vorteile. Es erfordert keine komplexe Grammatikdefinition oder mehrstufige Lookahead-Analysen, sondern arbeitet mit einem mehr oder weniger einfachen Satz von Regeln, die direkt an Tokens geknüpft sind. Dies führt zu kürzerem, flexibleren und leichter wartbarem Code.
Zudem kann die Methode auch auf umfangreichere und komplexere Sprachen oder Domänen erweitert werden, da Token individuell zugeschnittene Verarbeitungen bekommen und die Bindungsstärke fein abgestimmt werden kann. Die Leistungsfähigkeit zeigt sich darin, dass pro Token im Schnitt nur wenige Funktionsaufrufe nötig sind, unabhängig von der Komplexität des Eingangsausdrucks. Damit lässt sich eine beeindruckende Parsing-Geschwindigkeit erreichen, die in vielen Anwendungsfällen völlig ausreicht und selbst relativ komplexe Ausdrücke effizient verarbeitet. Dennoch ist TDOP nicht frei von Herausforderungen: Die korrekte Festlegung der Bindungsstärken verlangt Sorgfalt und Erfahrung, insbesondere bei neuen Operatoren oder besonderen Sprachdesigns. Auch die Kodierung von Token-Handlern muss konsequent durchdacht werden, um die Lesbarkeit und Erweiterbarkeit des Parsers zu gewährleisten.