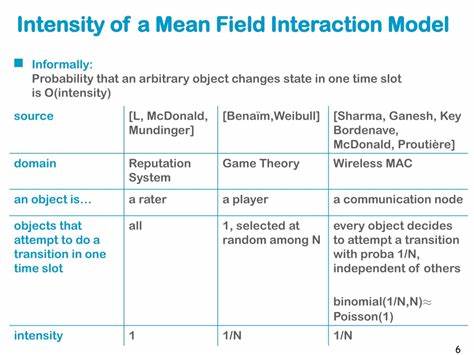
Im Bereich der Künstlichen Intelligenz und der Robotik gewinnt das Verständnis und die Steuerung von Multiagentensystemen zunehmend an Bedeutung. Besonders herausfordernd ist es, wenn es um den Einsatz von hunderten oder gar tausenden von Agenten geht, die in Wettbewerbsumgebungen agieren und komplexe Teamstrategien entwickeln müssen. Klassische Ansätze im Multiagenten-Reinforcement-Learning, wie MADDPG (Multi-Agent Deep Deterministic Policy Gradient) und MAAC (Multi-Agent Actor-Critic), stoßen hier an ihre Grenzen, da sie nicht effizient mit der steigenden Agentenzahl skalieren. Aus genau diesem Grund ist die Mean-Field-Theorie zu einem fokusbildenden Konzept geworden, das auf makroskopischer Ebene eine Annäherung an die Population von Agenten und deren Interaktionen mit der Umgebung ermöglicht. Mean-Field-Methoden betrachten die kollektive Wirkung eines Agentenfeldes anstatt auf einzelne Agenten zu fokussieren und ebnen somit den Weg für robustes Lernen selbst in extrem großen Teams.
Das innovative Konzept der Mean-Field-Interaktionen beruht darauf, dass in sehr großen Systemen das Verhalten eines einzelnen Agents kaum das Gesamtergebnis beeinflusst, vielmehr ist es die Verteilung und der aggregierte Einfluss aller Agenten, der zählt. Dieser faktische Übergang zu einer Kontinuumsperspektive erlaubt die Verwendung von stochastischen Differentialgleichungen und anderen mathematischen Werkzeugen, um die Dynamiken und optimalen Strategien zu erlernen. Die Herausforderung bestand bisher darin, diese Theorie wirksam in praxisnahe und simulationsstarke Algorithmen zu integrieren, die nicht nur robuste Performanz garantieren, sondern auch eine hohe Skalierbarkeit bezüglich der Agentenzahl aufweisen. In dem jüngsten Fortschritt auf diesem Gebiet wurde die traditionelle Proximal Policy Optimization (PPO) - eine bewährte Methode im Reinforcement Learning - erweitert und an die Anforderungen von Mean-Field-Interaktionen angepasst. Das neue Verfahren mit dem Namen Mean-Field Multi-Agent Proximal Policy Optimization (MF-MAPPO) ermöglicht es, effiziente und stabile Lernprozesse selbst in kompetitiven Mehragentenumgebungen mit umfangreichen Teamgrößen umzusetzen.
Dabei findet ein nullsummenbasiertes Spiel zwischen zwei gegnerischen Teams statt, bei dem für jedes Team das Ziel besteht, die optimale Gesamtstrategie in einem dynamischen Umfeld zu erfassen. Die Stärke von MF-MAPPO liegt darin, dass es die Wirksamkeit der finite-Population-Mean-Field-Approximation nutzt, um die Komplexität bei der Berechnung der Interaktionen drastisch zu reduzieren. Anstelle von internen Berechnungen zwischen einzelnen Agenten werden Mittelwerte über die Population herangezogen, wodurch das Modell auch bei 1000 oder mehr Agenten pro Team rechenbar bleibt. Dies ist ein enormer Vorteil gegenüber traditionellen MARL-Algorithmen, deren Rechenaufwand exponentiell mit der Anzahl der Agenten wächst. Die Anwendungsgebiete für solche Algorithmen sind breit gefächert.
Besonders im militärischen Kontext, wie bei groß angelegten Offensiv- und Defensivszenarien, bieten sich vielfältige Einsatzmöglichkeiten. Hier können realistische Simulationen von Kampfsituationen, Taktikentwicklung und Ressourcenmanagement erfolgen, die nicht nur akademischen, sondern auch praktischen Nutzen besitzen. Systeme, die in der Lage sind, komplexe Mehragenteninteraktionen auf Team-Ebene effizient zu steuern, können zukünftige Entscheidungsprozesse auf strategischer Ebene stark verbessern. Neben militärischen Simulationen finden sich auch im zivilen Einsatzbereich wertvolle Potenziale. Autonome Fahrzeugflotten, verteilte Drohnenschwärme oder intelligente Verkehrsnetzsteuerungen profitieren vom modellbasierten Lernen großer Agenten-Mengen mit kompetitiven und kooperativen Komponenten.
Die Mean-Field-Methodik bildet hierbei eine Brücke zwischen theoretischen Modellen und praxisorientierten Implementierungen. Technologisch gesehen basiert die Umsetzung von MF-MAPPO auf moderner Deep-Learning-Infrastruktur. Durch den Einsatz neuronaler Netzwerke können komplexe Zustand-Richtlinien-Zuordnungen erlernt werden, die die individuellen Agentenhandlungen mit den aggregierten Makrodynamiken in Einklang bringen. Die Trainingsprozesse werden dabei durch optimierte Gradientenverfahren und spezielle Regularisierungen unterstützt, die das Lernen stabil und effizient gestalten. Darüber hinaus fördert die Skalierbarkeit von MF-MAPPO eine realistische Abbildung von Szenarien, die bisher nur eingeschränkt simuliert werden konnten.
Die Möglichkeit, sowohl kooperative als auch konkurrierende Agententeams in großem Maßstab darzustellen, eröffnet Forschern und Entwicklern neue Horizonte bei der Gestaltung autonomer Systeme. Der algorithmische Fortschritt kann so in verschiedenen Bereichen adaptive und resiliente Systeme hervorbringen, die sich dynamisch an wechselnde Umweltbedingungen und Gegnerstrategien anpassen. Eine zentrale Herausforderung bleibt allerdings die Validierung der entwickelten Strategien und Modelle. Die Komplexität der Umgebungen und die Vielzahl der Agenten lassen eine vollständige theoretische Absicherung schwierig erscheinen. Hier kommen umfangreiche Simulationsstudien und empirische Bewertungen ins Spiel, die zeigen, dass MF-MAPPO in einer Vielzahl von Szenarien robuste Leistungswerte erzielt und das Lernen stabil hält.
Diese Ergebnisse sind oft der entscheidende Faktor bei der Akzeptanz solcher Algorithmen sowohl in der Forschung als auch in industriellen Anwendungen. Zukunftsorientiert eröffnen sich auch spannende Möglichkeiten durch die Kombination von Mean-Field-Ansätzen mit anderen modernen Technologien wie Transferlernen, Meta-Lernen und verteilte Optimierung. Solche hybriden Ansätze könnten die Adaptivität und Effizienz weiter erhöhen und den Einsatz großer Mehragentensysteme noch vielseitiger gestalten. Abschließend lässt sich festhalten, dass die Integration der Mean-Field-Theorie in moderne Reinforcement-Learning-Algorithmen wie PPO eine vielversprechende Methode darstellt, um die Herausforderungen der Skalierbarkeit und Komplexität in wettbewerbsorientierten Mehragentensystemen zu meistern. Der Erfolg von MF-MAPPO zeigt, wie theoretische Konzepte in praxisnahe Algorithmen überführt werden können, um realitätsnahe Mehragentensimulationen mit extrem großen Teamgrößen zu ermöglichen.
Diese Fortschritte bieten faszinierende Perspektiven für die Zukunft autonomer Systeme, in denen komplexe Teamdynamiken nicht nur simuliert, sondern auch effektiv gesteuert werden können.