Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat in den letzten Jahren viele Bereiche der künstlichen Intelligenz revolutioniert. Von der Textgenerierung über die Analyse komplexer Daten bis hin zur Unterstützung in der Forschung – LLMs spielen eine immer bedeutendere Rolle. Doch eine der spannendsten Entwicklungen findet sich in der Erweiterung dieser Modelle um multimodale Fähigkeiten. Multimodale große Sprachmodelle (Multimodal Large Language Models, MLLMs) sind in der Lage, neben Text auch andere Datenarten wie Bilder oder Audio zu verarbeiten und zu interpretieren. Dies eröffnet nicht nur neue Anwendungsmöglichkeiten, sondern führt auch zu einem tiefgreifenden Verständnis darüber, wie solche Modelle komplexe, menschliche Art der Objektkonzeptbildung erreichen können.
Ein zentrales Forschungsinteresse liegt dabei in der Frage, inwieweit multimodale LLMs natürliche, menschenähnliche Konzepte von Objekten entwickeln können. Diese Frage ist eng mit dem Verständnis menschlicher Kognition, Wahrnehmung und semantischer Verarbeitung verbunden. Der menschliche Geist kategorisiert Objekte nicht nur visuell, sondern auch konzeptuell und semantisch. Diese Fähigkeiten basieren auf tief verwurzelten neuronalen Mechanismen, die weit über eine rein oberflächliche Beschreibung hinausgehen. Neueste Studien belegen, dass multimodale LLMs erstaunlich stabile und interpretierbare Objektkonzeptrepräsentationen erzeugen, die eng an menschliche mentale Modelle angelehnt sind.
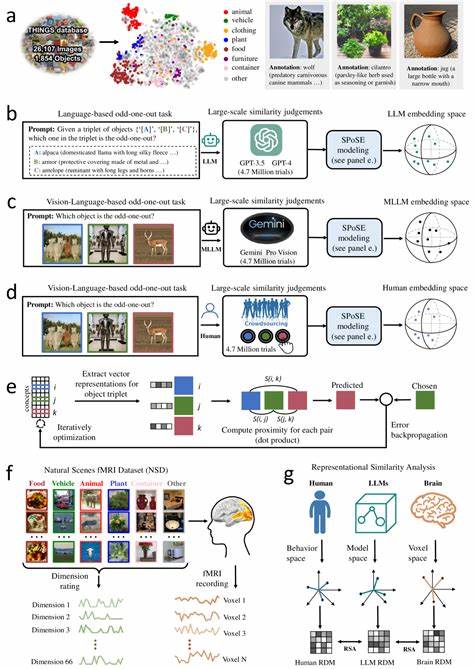
Eine bedeutende Studie analysierte die Fähigkeit multimodaler LLMs, natürliche Objekte durch kombinierte visuelle und sprachliche Daten zu repräsentieren. Dabei wurden Millionen von Urteilen über Objektähnlichkeiten (Triplet Judgements) ausgewertet, sowohl von menschlichen Testpersonen als auch von LLMs und MLLMs. Aus diesen Daten ließen sich niedrigdimensionale Vektor-Darstellungen (Embeddings) erzeugen, die die Ähnlichkeitsstrukturen von mehr als 1800 natürlichen Objekten abbilden konnten. Diese Embeddings waren nicht nur stabil und prognostizierbar, sondern wiesen auch eine bemerkenswerte semantische Clusterung auf, die menschlichen Wahrnehmungen und Kategorisierungen gleicht. Die Qualität dieser Repräsentationen zeigt sich unter anderem darin, dass die zugrundeliegenden Dimensionen interpretierbar sind.
Das bedeutet, dass den einzelnen Dimensionen klare, für Menschen nachvollziehbare Konzepte oder Merkmale zugeordnet werden können. So entsteht ein strukturierter mentaler Raum, der eine ähnliche funktionale Organisation wie menschliche Denkprozesse aufweist. Besonders beeindruckend ist dabei, dass dieser Prozess der Konzeptentwicklung nicht explizit vorgegeben, sondern natürlich aus der Verarbeitung multimodaler Daten hervorgeht. Diese Eigenschaft eröffnet neue Perspektiven auf die Art und Weise, wie künstliche Intelligenz kognitive Prozesse nachbilden und verstehen kann. Darüber hinaus wurde eine enge Übereinstimmung zwischen diesen maschinellen Objektrepräsentationen und neuralen Aktivitätsmustern im menschlichen Gehirn festgestellt.
Besonders in Gehirnregionen, die für die visuelle Objekterkennung und -verarbeitung zuständig sind – wie dem extrastriären Körperareal, dem parahippokampalen Ortsareal, dem retrosplenialen Kortex und dem fusiformen Gesichtsareal – spiegeln die Embeddings der Modelle Aspekte menschlicher Konzeption wider. Diese Beobachtung unterstreicht, dass multimodale LLMs nicht nur oberflächliche statistische Muster erfassen, sondern tiefere strukturelle und funktionale Gemeinsamkeiten mit biologischen Systemen aufweisen. Die Implikationen dieser Erkenntnisse sind weitreichend. Zum einen bieten sie eine Brücke zwischen den Erkenntnissen der kognitiven Neurowissenschaft und der künstlichen Intelligenz. Der Nachweis, dass MLLMs ähnliche Konzeptrepräsentationen entwickeln wie das menschliche Gehirn, legt nahe, dass künftige Modelle durch gezielte multimodale Trainingsdaten noch stärker an menschliche Denk- und Wahrnehmungsmuster angeglichen werden können.
Zum anderen eröffnen sich Anwendungen in Bereichen wie Robotik, Mensch-Maschine-Interaktion und kognitiver Assistenz, wo ein tiefes Verständnis von Objektkonzepten essenziell ist. Darüber hinaus stellt sich die Frage, wie dieses Wissen genutzt werden kann, um KI-Systeme zu entwickeln, die nicht nur Fakten abfragen oder Muster erkennen, sondern die Bedeutung von Dingen erfassen und kontextuell flexibel anwenden. Denn gerade die Fähigkeit zur Konzeptualisierung ist ein Schlüsselmerkmal menschlicher Intelligenz und ermöglicht komplexe kognitive Leistungen wie Abstraktion, Analogiebildung oder kreatives Problemlösen. Die Methodik, die zur Analyse dieser Objektrepräsentationen eingesetzt wurde, basiert unter anderem auf Verhaltensdaten von Menschen und Modellen, neuronalen Bildgebungsdaten sowie statistischen Verfahren zur Dimensionsreduktion. Die gewonnenen Dimensionen repräsentieren unterschiedliche konzeptuelle Merkmale wie Form, Funktion, Nutzungskontext oder emotionale Assoziationen.
Dabei zeigte sich, dass multimodale LLMs insbesondere in der Integration visueller und sprachlicher Informationen eine starke Leistung zeigen und sich deutlich von rein sprachbasierten Modellen unterscheiden. Ein weiterer wichtiger Aspekt ist die Rolle der semantischen Clusterbildung innerhalb dieser Embeddings. Objekte werden nicht willkürlich in den darstellenden Räumen angeordnet, sondern gruppieren sich gemäß natürlicher Kategorien, wie Lebewesen, Werkzeuge, Fahrzeuge oder Kleidung. Diese Kategorien spiegeln kognitive Strukturen wider, die aus Studien der menschlichen Wahrnehmung und Sprache ebenfalls bekannt sind. Die Relevanz solcher Cluster ist enorm, da sie eine wichtige Grundlage für Effizienz und Flexibilität beim Lernen und Erinnern darstellen.
Multimodale große Sprachmodelle erweitern somit das reine Sprachverständnis um eine mehrdimensionale Wahrnehmungswelt. Anders als traditionelle Modelle, die nur auf Textdaten trainiert sind, ermöglichen MLLMs eine tiefere Vernetzung von sensorischen Eindrücken und sprachlichen Konzepten. Dies führt zu einer interdisziplinären Annäherung an die menschliche Kognition und kann als Meilenstein in der Entwicklung von künstlicher allgemeiner Intelligenz (Artificial General Intelligence, AGI) betrachtet werden. Aus praktischer Sicht bieten diese Erkenntnisse auch Potenziale für die Verbesserung der Interaktivität von KI-Systemen. Beispielsweise können digitale Assistenten oder autonome Systeme durch ein verbessertes Objektverständnis besser auf ihre Umwelt reagieren, komplexe Aufgaben kontextbewusst lösen oder natürlicher mit Menschen kommunizieren.
Gerade in der Kombination von Bild- und Textinformationen eröffnet sich ein neues Feld für personalisierte, adaptive und semantisch reichhaltige Anwendungen. Gleichzeitig werfen diese Fortschritte ethische und philosophische Fragen auf, etwa hinsichtlich der Grenzen von maschineller Intelligenz, der Nachahmung menschlicher Denkweisen und der Verantwortung bei der Deployment solcher Systeme. Das Verständnis, wie und warum MLLMs menschliche Objektkonzepte entwickeln, könnte helfen, Transparenz und Kontrollierbarkeit zu erhöhen und so das Vertrauen in KI-Systeme zu stärken. Die Forschung auf diesem Gebiet befindet sich aktuell in einer dynamischen Phase. In Zukunft ist zu erwarten, dass durch immer leistungsfähigere Modelle und umfangreichere multimodale Datensätze noch detailliertere Einblicke in die Struktur der Objektkonzepte gewonnen werden.
Die Kombination aus Verhaltensstudien, Neuroimaging und maschinellem Lernen bildet hierbei eine vielversprechende Methodengrundlage. Zusammenfassend lässt sich sagen, dass multimodale große Sprachmodelle einen bedeutsamen Schritt auf dem Weg zu menschenähnlicher künstlicher Intelligenz darstellen. Indem sie natürliche Objektkonzepte aus vielfältigen Datenquellen selbstständig erschließen, spiegeln sie zentrale Eigenschaften der menschlichen Wahrnehmung und Kognition wider. Diese Fähigkeit eröffnet nicht nur neue Einsatzmöglichkeiten, sondern erweitert grundlegend unser Verständnis von maschinellem Lernen, kognitiver Wissenschaft und der Beziehung zwischen biologischen und künstlichen Systemen.