Diffusionsmodelle sind ein innovativer Ansatz im Bereich der künstlichen Intelligenz, der vertiefte Einblicke in die Generierung von Daten wie Bildern, Videos und sogar Text bietet. In den letzten Jahren haben diese Modelle enorm an Bedeutung gewonnen, insbesondere im Zusammenhang mit der Erzeugung hochwertiger Bilder, die Nutzer weltweit faszinieren. Während viele mit transformerbasierten Sprachmodellen, wie etwa ChatGPT, vertraut sind, ist das Verständnis für Diffusionsmodelle vielerorts noch nicht so verbreitet. Dabei hat diese Technologie das Potenzial, die KI-Landschaft in ähnlicher Weise zu prägen und bietet gleichzeitig spannende neue Möglichkeiten. Es lohnt sich daher, das Konzept und die Funktionsweise von Diffusionsmodellen genauer zu betrachten.
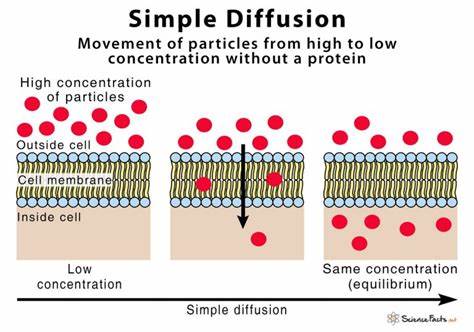
Grundidee der Diffusionsmodelle lässt sich mit einem einfachen Bild veranschaulichen. Man stelle sich ein Foto eines Hundes vor, das langsam mit zufällig eingefärbten Pixeln überlagert wird, bis es schließlich komplett in einem Rauschen aus farbigen Punkten aufgelöst erscheint. Dieses „Rauschen“ ähnelt dem statischen Bild auf einem Fernseher ohne Empfang. Alle möglichen Bilder, egal wie verschieden sie sind, können auf diesem Weg schrittweise in dieses reine Rauschen transformiert werden. Daraus ergibt sich eine spannende Erkenntnis: Zwischen jedem Bild und dem Rauschen existiert eine Art Gradientenpfad, der das Bild schrittweise zur verrauschten Version macht.
Ein Diffusionsmodell wird trainiert, um genau diesen Prozess zu verstehen. Dabei lernt es, von einem verrauschten Bild zurück zum ursprünglichen Bild zu gelangen, indem es das jeweils hinzugefügte Rauschen prognostiziert und entfernt. Während der Trainingsphase werden tausende von Bildern in graduell verrauschter Form genutzt, zusammen mit den dazugehörigen Bildbeschreibungen in Form von Text-Embeddings. Das Modell bekommt ein verrauschtes Bild und die Bildbeschreibung als Eingabe und versucht zu erraten, welche Art von Rauschen in jedem Schritt hinzugefügt wurde. Das Besondere dabei ist, dass anders als bei Sprachmodellen die Eingabe nicht aus einer Sequenz von Token besteht, sondern in jedem Schritt ein komplettes Bild verarbeitet wird.
Das Ziel ist es, den genauen Rauschanteil vorherzusagen, sodass das Bild durch sukzessives Entfernen von Rauschen rekonstruiert werden kann. Dieser iterative Vorgang wird “Denoising” genannt und funktioniert folgendermaßen: Bei der Bildgenerierung wird zunächst mit einem Bild aus reinem Rauschen begonnen. Dann entfernt das Modell schrittweise die erkannten Rauschschichten, bis am Ende ein neues, vom Modell generiertes Bild entsteht, das der Eingabebeschreibung entspricht. Diese Rückkehr vom Rauschen zum Bild ist das Hauptprinzip, das Diffusionsmodelle antreibt und von anderen KI-Modellen unterscheidet. Ein zentraler Bestandteil vieler Diffusionsmodelle ist der Einsatz eines Variational Autoencoders (VAE), eine spezielle Art von neuronalen Netzwerken, die bildliche Daten komprimieren können.
Bilder enthalten Millionen von Pixeln, jedes einzeln zu verarbeiten wäre enorm ressourcenintensiv. Der VAE lernt, Bilder in eine kompaktere, aber dennoch ausreichend aussagekräftige Form zu überführen, die besser maschinell zu handhaben ist. Im Gegensatz zu bekannten Kompressionsformaten wie JPEG, die stark strukturierte Informationen speichern, erzeugt der VAE eine kompakte Darstellung mit Eigenschaften, die für das Hinzufügen und Entfernen von Rauschen ideal sind. Das dadurch trainierte Modell arbeitet wesentlich effizienter und kann Bilder schneller generieren. Ein weiteres wichtiges Konzept ist die sogenannte „classifier-free guidance“.
Diese Technik stellt sicher, dass das Modell bei der Generierung tatsächlich auf die Eingabebeschreibung achtet und nicht einfach beliebige Bilder erzeugt. Während des Trainings wird die Bildbeschreibung gelegentlich absichtlich weggelassen, wodurch das Modell lernt, sowohl mit als auch ohne Eingabetext umzugehen. Bei der späteren Nutzung wird dieser Mechanismus verwendet, indem das Modell einmal mit und einmal ohne Beschreibung berechnet wird. Die Differenz der beiden Ergebnisse wird verstärkt, was die Aufmerksamkeit auf die Beschreibung erhöht und somit die Relevanz des generierten Bildes verbessert. Diffusionsmodelle unterscheiden sich grundlegend von transformerbasierten Sprachmodellen, die in den letzten Jahren die KI-Welt geprägt haben.
Während Transformer durch die Verarbeitung von Sequenzen einzelne Tokens (Bedeutungseinheiten) vorhersagen und hinzufügen, starten Diffusionsmodelle mit einer vollständig verrauschten Eingabe, die schrittweise gereinigt wird. Generatoren wie ChatGPT bekommen lediglich eine Texteingabe und erweitern diese Token für Token, wohingegen Diffusionsmodelle an jedem Step eine komplette Ausgabe erhalten und diese fortlaufend überarbeiten. Ein weiterer wesentlicher Unterschied ist, dass Diffusionsmodelle früher gestoppte Prozesse mit einem teilweise verrauschten Output quittieren, der noch nicht vollständig klar ist – während Transformer zu einem unvollständigen Text führen können, der schwer verständlich ist. Dieses Merkmal bietet einen praktischen Vorteil: Die Qualität der Ausgabe kann durch die Anzahl der Rauschreduktionsschritte angepasst werden. Wer schnell eine grobe Skizze braucht, lässt das Modell früher stoppen.
Wer optimale Bildqualität möchte, erlaubt dem Modell den gesamten Reinigungsprozess zu durchlaufen. Dies eröffnet einen flexiblen Umgang mit Ressourcen und Anwendungsanforderungen. Über die reine Bildgenerierung hinaus lassen sich Diffusionsmodelle auch auf Videos und Audio anwenden. Hierbei wird das Prinzip erweitert und anstelle einer Einzelbildmatrix mit verrauschten Pixeln, setzt man auf dreidimensionale oder sogar mehrdimensionale Matrizen, die sämtliche Frames eines Videos oder Audiosignale umfassen. Das Modell lernt dadurch nicht nur, Rauschen in einzelnen Bildern oder Tönen zu identifizieren, sondern auch zeitliche und kausale Zusammenhänge zwischen verschiedenen Frames oder Tonabschnitten zu berücksichtigen.
Gerade bei Videos funktioniert dieses Verfahren erstaunlich gut, auch wenn die kontinuierliche Länge von Bewegtbildern und deren Anforderungen an Konsistenz Herausforderungen mit sich bringen. Diffusionsmodelle für Texte sind dagegen noch in einem experimentellen Stadium, da sich Sprache nicht so einfach verrauschen lässt wie Bilder oder Audio. Der gängige Ansatz besteht darin, die eingebetteten Repräsentationen von Text zu verrauschen. Diese sogenannten Text-Embeddings werden in einen verrauschten Zustand versetzt und anschließend vom Modell wieder in verständlichen Text zurückverwandelt. Dies ist jedoch komplex, da eine einfache Rückübersetzung von verrauschten Embeddings in Wörter oft zu unverständlichen Sätzen führt.
Manche Systeme nutzen daher weitere Modelle, um die Embeddings zu dekodieren, was aber manchmal als Umgehung angesehen wird. Die Diffusionsmodelle zeigen, wie leistungsfähig das Prinzip „Rauschen hinzufügen und wieder entfernen“ in der KI ist. Es handelt sich nicht um eine proprietäre oder spezialisierte Lösung, sondern um einen sehr allgemeinen Mechanismus, der auf vielen Datenarten anwendbar ist. Die Forschung in diesem Bereich läuft intensiv weiter, da neue Techniken entwickelt werden, um Effizienz, Qualität und Anwendbarkeit stetig zu erhöhen. Google, OpenAI und andere führende Unternehmen tragen maßgeblich zu dieser Entwicklung bei und bringen stetig neue, verbesserte Modelle auf den Markt.
So wurde etwa kurz nach der Veröffentlichung vieler Begleitartikel mit dem Gemini Diffusion Modell ein besonders leistungsfähig erscheinender Text-Diffusionsansatz vorgestellt. Zusammenfassend lassen sich Diffusionsmodelle als eine neuartige Familie von KI-Modellen beschreiben, die sich fundamental von bisherigen Ansätzen, insbesondere von autoregressiven Sprachmodellen, unterscheiden. Die Grundidee, schrittweise Rauschen zu entfernen und anhand dessen neue Daten zu generieren oder rekonstruieren, hat die Tür zu hochwertigen Bild-, Video- und Audioerzeugungen weit aufgestoßen. Besonders für die Bildgenerierung haben Diffusionsmodelle bereits eine breit gefächerte Anwendung gefunden und erfreuen sich wachsender Beliebtheit unter Forschern und Anwendern. Im Gegensatz zu sequenziellen Generierungsprozessen arbeiten Diffusionsmodelle iterativ an einer vollständigen Ausgabe, die kontinuierlich verbessert wird, was sowohl Flexibilität in der Nutzung als auch eine einfache Qualitätssteuerung ermöglicht.
Zukünftig könnten sie auch bei der Verarbeitung und Erzeugung von Text eine bedeutendere Rolle spielen, wenn es gelingt, die besonderen Herausforderungen bei der Textrepräsentation zu meistern. Die stetige Weiterentwicklung von Diffusionsmodellen zeigt eindrucksvoll, wie vielseitige und kraftvolle Methoden der künstlichen Intelligenz entstehen können, wenn man neue mathematische und algorithmische Prinzipien miteinander kombiniert. Wer sich mit KI beschäftigen möchte, sollte die Mechanismen und Möglichkeiten von Diffusionsmodellen im Auge behalten, denn sie gehören zu den spannendsten Trends einer schnelllebigen Technologiebranche.