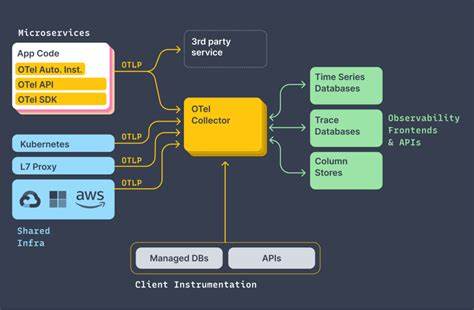
In der modernen IT-Landschaft sind verteilte Systeme allgegenwärtig und mit deren Komplexität wachsen auch die Anforderungen an Überwachung und Fehlersuche. Distributed Tracing hat sich als eine der effektivsten Methoden etabliert, um komplexe Anfragen über verschiedene Dienste hinweg nachzuvollziehen. OpenTelemetry (OTEL) bietet hierzu einen offenen Standard für die Erfassung und Weiterleitung von Telemetriedaten, insbesondere von Traces, die aus sogenannten Spans bestehen. Das effiziente Speichern und Abfragen dieser enormen Mengen an Trace-Daten stellt jedoch Organisationen vor Herausforderungen. Die Erfahrung zeigt, dass spaltenorientierte Speicherformate wie Apache Parquet eine entscheidende Schlüsselrolle bei der Skalierbarkeit und Performance spielen.
Distributed Traces bestehen aus einer Sammlung von Spans, wobei jeder Span ein einzelnes Ereignis oder eine Operation darstellt. Essenziell für jeden Span sind Attribute wie der Dienstname, die Operation (Span-Name), Zeitstempel, Dauer und diverse Schlüssel-Wert-Paare. In großen Systemen können Traces Milliarden von Spans ausmachen, was enorme Datenvolumina verantwortet. Die Speicherung erfolgt daher nicht nur aus Gründen der kurzfristigen Analyse, sondern auch zur Langzeitarchivierung und -durchsuchbarkeit. Die Wahl eines optimalen Speicherformats ist hier maßgeblich.
Im Gegensatz zu herkömmlichen zeilenorientierten Formaten wie JSON oder CSV bietet das spaltenorientierte Parquet-Format eine Reihe von Vorteilen, die speziell für Trace-Daten relevant sind. Parquet speichert jede Spalte separat, was bedeutet, dass Abfragen, die sich nur auf bestimmte Attribute beziehen, deutlich effizienter durchgeführt werden können. Beispielsweise kann eine Suche nach allen Spans eines bestimmten Dienstes gezielt nur die entsprechende Spalte lesen und so I/O-Vorgänge drastisch reduzieren. Diese Fähigkeit, nur die relevanten Daten auszulesen, nennt man häufig predicate pushdown oder column pruning und sie führt zu erheblichen Geschwindigkeitsvorteilen.Eine der grundlegenden Charakteristika von Traces ist ihre Baumstruktur mit einem einzelnen Root-Span, der den Startpunkt einer Transaktion oder Anforderung repräsentiert.
Jeder nachfolgende Span ist über eine Parent-Span-ID mit seinem unmittelbaren Vorgänger verbunden. Dies bildet eine gerichtete azyklische Graphenstruktur ab, die jedoch operationell als Baum betrachtet wird. Zum Speichern in Systemen wie ParseableDB werden solche Baumbäume flach auf Zeilen in Tabellen abgebildet, wobei die Parent-Child-Beziehung durch IDs erhalten bleibt und bei Abfrage oder Visualisierung rekonstruiert werden kann. Ein solcher Ansatz benötigt keinen spezialisierten Graphendatenbank-Ansatz, sondern profitiert von der flexiblen und effizienten Spaltenstruktur.Die Speicherung von Trace-Daten in Parquet bringt allerdings nicht nur Abfragevorteile, sondern auch eine erhebliche Reduktion der Datenmenge durch Kompression.
Trace-Daten sind naturgemäß redundant, da viele Spans sich dieselben Attribute teilen, etwa „service_name“ oder „operation_name“. Spaltenorientierte Speicherung erlaubt es, diese Redundanzen optimal zu komprimieren und so den Speicherverbrauch drastisch zu senken. So zeigt die Praxis, dass eine ursprünglich 1 Terabyte große JSON-Trace-Datei nach Umwandlung in Parquet typischerweise auf rund 130 Gigabyte schrumpft, was einer erheblichen Einsparung entspricht. Diese Komprimierung wirkt sich auch direkt auf die Geschwindigkeit von Abfragen aus, da weniger Daten gelesen werden müssen.Neben klassischen spaltenorientierten Komprimierungsmethoden nutzt Parseable erweiterte Techniken zur Attributsortierung und String-Matching.
Bekannte Felder wie „service.name“, „status.code“ oder „duration_ms“ werden während der Aufnahme in eigene dedizierte Spalten überführt, um schnelle Filterungen zu unterstützen. Dynamische oder seltene Attribute hingegen fasst das System in einer gemeinsamen „other_attributes“-Spalte als flexibles Key-Value-Store zusammen. Dieses Splitting zwischen starren und flexiblen Attributen gewährleistet ein optimales Gleichgewicht zwischen Leistungsfähigkeit und Anpassungsfähigkeit bei der weiteren Analyse.
Ein weiterer großer Vorteil liegt im deutlich reduzierten I/O-Aufwand durch die spaltenbasierte Datenorganisation. In traditionellen Formaten müsste man jedes Datenfragment komplett lesen, um einzelne Felder abzufragen. Parquet hingegen garantiert, dass nur die tatsächlich benötigten Spalten sequenziell gelesen werden, was die Anzahl der Festplattenzugriffe und deren Dauer merklich senkt. Zusätzlich tragen eingebaute Statistik- und Indexfunktionen von Parquet dazu bei, dass große Datenblöcke, die bereits als irrelevant erkannt wurden, übersprungen werden können. Die Folge ist eine stark beschleunigte Abfragegeschwindigkeit bei gleichzeitig geringerem Ressourcenverbrauch.
Neben der effektiven Nutzung der Festplatten-I/O profitiert die Verarbeitung auch auf CPU-Ebene erheblich. Spaltenorientierte Datenstrukturen sind besonders gut geeignet für CPU-Caches und SIMD-Vektoroperationen. Filter- und Aggregationsoperationen können auf ganzen Arrays von Werten gleichzeitig angewandt werden, was zu enormen Performancegewinnen bei der Analyse führt. Das Parquet-Design mit sogenannten Row-Groups ermöglicht es, ganze Datenblöcke auf einmal zu verarbeiten, wodurch Prozessordurchsatz und Effizienz steigen.Reale Plattformen wie Parseable und Tempo veranschaulichen den praktischen Erfolg dieses Konzepts.
Parseable wurde explizit für hohe Skalierbarkeit und Geschwindigkeit durch Spaltenorientierung ausgelegt. Ihr Ansatz verzichtet bewusst auf schwergewichtige Indexe, die bei großen Mengen an hochdiversifizierten Trace-Attributen sonst schnell gigantische Speicher- und Rechenressourcen binden würden. Tempo setzt ebenfalls auf Parquet, um beim Umgang mit Milliarden Spans Abfragen performant direkt auf den Parquet-Dateien durchzuführen. Das großartige dabei ist auch die Interoperabilität mit etablierten Big-Data-Tools wie Spark oder Presto, welche Parquet nativ unterstützen und so umfangreiche Analysen ohne aufwendige Umwandlungen ermöglichen.Die OpenTelemetry-Community ist sich der Vorteile spaltenorientierter Speicherung bewusst und erforscht zusehends Transport- und Speicherformate wie Apache Arrow für Telemetriedaten.
Obwohl das klassische OTLP-Protokoll auf Protobuf basiert, werden in Backends typischerweise spaltenorientierte Datenformate eingesetzt, um bestmögliche Komprimierung und schnelle Verarbeitung zu gewährleisten. Viele OTEL-Collector-Pipelines enthalten bereits Implementierungen zur Ausgabe von Trace-Daten im Parquet-Format, was die Integration in bestehende Ökosysteme erheblich vereinfacht.Im Gesamtbild adressieren spaltenorientierte Formate eine ganze Reihe mathematischer und betrieblicher Herausforderungen, die mit hochdimensionalen, hochgradig variablen Trace-Daten verbunden sind. Die Trennung der Attribute in Spalten reduziert die Komplexität zahlreicher Kombinationen, senkt die systembedingte Redundanz, minimiert Speicherauslastung und I/O-Aufwand. Diese Eigenschaften sind essenziell für die Bewältigung großer Datenmengen bei gleichzeitig hoher Ad-hoc-Abfrageperformance, wie moderne Observability-Systeme sie erfordern.
Für Organisationen, die mit konventionellen Observability-Stacks an Grenzen stoßen oder vor dem Hintergrund wachsender Datenvolumen eine nachhaltige, skalierbare Lösung suchen, sind spaltenorientierte Speicherformate wie Parquet eine unverzichtbare Komponente geworden. Die Verbindung von hohem Kompressionsgrad, schneller Datenzugriffszeit und flexibler Attributverarbeitung ermöglicht es, die volle Leistungsfähigkeit von Distributed Tracing auch in komplexesten Infrastrukturen zu gewährleisten.Zusammenfassend lässt sich festhalten, dass die Implementierung von OpenTelemetry-Traces in spaltenorientierten Dateien nicht nur eine innovative technische Lösung darstellt, sondern einen fundamentalen Wandel in der Handhabung großer Telemetriedatenmengen ermöglicht. Mit bewährten Technologien wie Apache Parquet sowie optimierten Datenmanagementansätzen in Systemen wie Parseable können Unternehmen besser auf die künftigen Anforderungen der Observability-Ära reagieren und ihre Analyse- und Fehlerbehebungsprozesse deutlich beschleunigen.