Visual Studio Code, kurz VS Code, hat sich seit seinem Erscheinen zu einem der beliebtesten Code-Editoren weltweit entwickelt. Ein bedeutender Meilenstein auf diesem Weg war die Neuentwicklung des Textbuffers im Jahr 2018, die in der Version 1.21 eingeführt wurde. Dieses Update war nicht nur ein technisches Upgrade, sondern brachte eine tiefgreifende Veränderung in Bezug auf Geschwindigkeit, Speicherverbrauch und Performance bei der Textverarbeitung mit sich. Besonders bei sehr großen Dateien zeigte sich die Dringlichkeit, bestehende Methoden zu überdenken und durch innovative Datenstrukturen und Algorithmen zu ersetzen.
Die Geschichte hinter dieser Neuentwicklung ist genauso faszinierend wie die technische Umsetzung selbst, denn sie gibt Einblicke in die Herausforderungen moderner Softwareentwicklung und die Bedeutung fundierter Performance-Analysen. Vor der Neuentwicklung nutzte VS Code eine einfache aber effektive Datenstruktur: ein Array aus einzelnen Zeilen. Dieses Modell war intuitiv, da der mentale Bezug von Entwicklern normalerweise zeilenorientiert ist. Quelltexte, Compiler-Fehlermeldungen, Tokenizer und Debugger arbeiten hauptsächlich zeilenbasiert. Deshalb erschienen Arrays eine logische Wahl.
Diese Struktur reichte für kleinere bis mittelgroße Dateien aus, da ein Zugriff auf eine einzelne Zeile sehr schnell möglich war. Änderungen an Textabschnitten wurden durch das Ersetzen oder Einfügen entsprechender Zeilenobjekte realisiert. Trotz dieser Einfachheit gab es erhebliche Probleme bei extrem großen Dokumenten. Anwender berichteten von Abstürzen aufgrund von Speicherüberschreitungen, wenn Dateien mit Millionen von Zeilen geöffnet wurden. Ein prominentes Beispiel war eine 35 Megabyte große Textdatei mit 13,7 Millionen Zeilen, deren Verarbeitung nahezu unmöglich schien.
Das Problem lag darin, dass für jede einzelne Zeile ein Objekt angelegt wurde, welches 40 bis 60 Byte Speicher beanspruchte – die Speicherbelegung war somit rund 20 mal größer als die ursprüngliche Dateigröße. Neben dem hohen Speicherverbrauch erwies sich die Art und Weise, wie der Editor Dateien öffnete, als Flaschenhals. Um das ursprüngliche Array zu erzeugen, wurde der Textinhalt split-weise in Zeilen aufgeteilt. Diese Zerlegung erzeugte viele einzelne String-Objekte und war aufwendig in der Verarbeitung, was die Ladezeiten großer Dateien massiv erhöhte. Die Entwickler von VS Code waren sich der Limitierungen bewusst und suchten nach einer besseren Lösung, die sowohl Speicher effizient nutzte als auch performanter arbeitete.
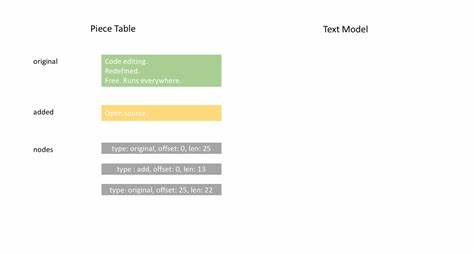
Die Suchfrage führte zu einer Untersuchung verschiedener Datenstrukturen. Die Entwickler stießen auf die „Piece Table“, eine etablierte Technik zur effizienten Verwaltung von Textänderungen. Eine Piece Table besteht aus zwei Hauptpuffern: einem Originalpuffer für den ursprünglichen Dokumentinhalt und einem Eingabepuffer, in dem alle nachträglichen Änderungen gesammelt werden. Statt ständig wörtliche Änderungen am Originaltext vorzunehmen, verwaltet die Piece Table eine Liste von Knoten („Nodes“), die Abschnitte innerhalb dieser beiden Puffer repräsentieren. Neue Eingaben werden an den Eingabepuffer angehängt, im Knotenbaum als eigener Knoten vermerkt und das Original bleibt unangetastet.
So lassen sich Änderungen sparsam und flexibel darstellen. Ein großer Vorteil dieser Methode ist die reduzierte Speicherbelegung, da keine vollständigen Kopien der Datei bei jeder Änderung erstellt werden müssen. Der Speicherbedarf wächst proportional zu den tatsächlich vorgenommenen Änderungen, nicht zur Gesamtgröße des Dokuments. Das macht Piece Tables besonders gut für umfangreiche Quelltexte geeignet, die aber oft nur kleine Stellen modifiziert bekommen. Trotz dieser Vorteile hatte die traditionelle Piece Table eine entscheidende Schwäche: die zeilenbasierte Navigation war ineffizient.
Möchte der Editor beispielsweise den Inhalt der Zeile 1000 abrufen, muss er vom Dokumentanfang aus alle vorkommenden Zeilenumbrüche zählen, um die richtige Position zu identifizieren. Gerade bei langen Dateien mit vielen Änderungen kann das zu einer erheblichen Performanceeinbuße führen, da die Zeitkomplexität dabei linear zur Anzahl der Knoten wächst. Um diesen Nachteil zu beseitigen, entwickelten die VS Code Entwickler eine raffinierte Lösung: Sie erweiterten die Piece Table um eine ergänzende Zeilen-Indexierung innerhalb der Knoten. Diese „LineStarts“-Informationen enthalten die relativen Offsets der Zeilenumbrüche innerhalb eines Textabschnitts. Dadurch kann der Editor schneller feststellen, welche Zeile an welcher Position liegt, ohne jeden einzelnen Buchstaben durchgehen zu müssen.
Doch der Speicherverbrauch und die Ladezeiten großer Dateien stellten weiterhin Herausforderungen dar. Besonders binding-spezifische Limits der zugrundeliegenden JavaScript-Engine V8 wurden sichtbar. Da große Textabschnitte nicht beliebig als einzelne Strings verarbeitet werden konnten (etwa wegen Limitierungen der max. Stringlänge), wichen die Entwickler von der ursprünglichen Idee ab, den Originalinhalt in einem einzelnen String zu speichern. Stattdessen hielten sie eine Liste von Puffern, die jeweils einen Chunk des Dokuments enthielten.
Diese Fragmentierung orientierte sich an den Chunk-Größen beim Laden aus dem Dateisystem, zumeist 64 KByte. Jeder Chunk wurde direkt der Piece Table hinzugefügt und als eigener Knoten verwaltet. Diese Technik sorgte dafür, dass beispielsweise Dateien mit 500 Megabyte Größe ohne Fehler geladen werden konnten, was vorher technisch unmöglich war. Die einzige Kostenkomponente bestand nun in der Verwaltung einer größeren Menge von Knoten. Um diesen Overhead bei der Suche nach Zeilen weiter zu minimieren, setzten die Entwickler auf eine balancierte Binärbaumstruktur – genauer gesagt einen Rot-Schwarz-Baum.
Rot-Schwarz-Bäume sind so konstruiert, dass sie beim Einfügen und Löschen von Knoten eine schnelle Umstrukturierung gewährleisten und dadurch eine logarithmische Zeitkomplexität für Suchoperationen garantieren. Durch eine gezielte Zwischenspeicherung von Metadaten wie Textlängen und Zeilenzählungen in den Teilbäumen eines Knotens konnte das System zeilenbasierte Suchen und Zugriffe noch weiter beschleunigen. Aufgrund dieser Architektur konnte der Editor schnell ermitteln, welcher Knoten die gesuchte Zeile enthält, ohne eine komplette Iteration durch alle Knoten zu benötigen. Eine zusätzliche Performanceverbesserung ergab sich daraus, dass die Zeilenumbrüche nicht bei jeder Änderung komplett neu berechnet werden mussten. Da Original- und Änderungs-Puffer entweder unveränderliche oder append-only Texte enthalten, bleiben deren Zeilenumbrüche konstant.
Die Knoten referenzieren lediglich die Zeilenpositionsarrays der jeweiligen Puffers und teilen so redundante Speicher- und Rechenkosten. Diese clevere Speichersharing-Technik erhöhte die Geschwindigkeit bei Teiloperationen massiv, teilweise um das Dreifache gegenüber vorherigen Implementierungen. Die daraus resultierende neue Text-Puffer-Lösung wurde intern am VS Code Team „Piece Tree“ genannt – eine Kurzform, die den Kern der Architektur trifft: Ein Baum von Textsegmenten aus mehreren Puffern. Diese Implementierung zeigte bei Benchmarks und realen Tests eine herausragende Performance. Die Speicherbelegung bei großen Dateien reduzierte sich drastisch, während Öffnungszeiten dank effizienter Indexierung und Speicherverwaltung merklich kürzer wurden.
Die Stabilität des Editors selbst verbesserte sich, insbesondere bei Dateien mit Millionen von Zeilen und zahlreichen Änderungen. Ein weiterer wesentlicher Punkt war jedoch, dass die neue Architektur nicht nur Theorie blieb: Sie wurde direkt in den produktiven VS Code Codebasis integriert und ist seit Version 1.21 Standard. Entwickler konnten somit sofort von den Vorteilen profitieren. Trotz der Vorteile gab es auch Grenzen und Herausforderungen.
Die zeilenbasierte Suche ist zwar sehr performant, aber bleibt bei extrem vielen Knoten (beispielsweise 1000 oder mehr bei einer großen Zahl von Änderungen) langsamer als das einfache Zeilenarray-Modell mit konstanter Zeit. Doch der Kompromiss erschien als richtig, da der häufigste Use Case keine sehr große Anzahl von kleinen Knoten erzeugt. Zudem sind selbst längere Zugriffe meist immer noch im Mikrosekundengegionen und damit für Anwender kaum wahrnehmbar. Das VS Code Team plant dennoch noch weitere Optimierungen, wie sogenannte Normalisierungsschritte, um bei Bedarf Knoten und Puffer neu zusammenzuführen und so die Struktur schlanker zu halten. Eine interessante Erkenntnis der Entwickler war deren Erfahrung mit einem nativen C++-Modul für den Textbuffer.
Sie hatten versucht, Vorteile in Geschwindigkeit und Speicher durch native Implementierung zu erreichen. Allerdings zeigte sich, dass die ständigen Übergänge zwischen JavaScript und C++ im konkreten Kontext der häufigen Methodenaufrufe den Performancegewinn zunichtemachten. Vor allem bei der oft genutzten getLineContent Funktion führte diese JavaScript-to-Native-Überquerung zu Verzögerungen und komplexen Speicherverwaltungskonflikten. Deshalb entschieden sie sich bewusst für eine reine JavaScript-Implementierung mit cleveren Algorithmen und Datenstrukturen. Dies ermöglichte V8 optimalen Code zu erzeugen und Methoden zu inline-cachen.
Außerdem blieb die Entwicklererfahrung konsistent und wartbar, was in einem Open-Source Projekt wie VS Code ein entscheidender Vorteil ist. Die Neuentwicklung des Textbuffers in VS Code kann als Beispiel gelten, wie moderne Software komplexe Herausforderungen durch algorithmische Intelligenz, Speichereffizienz und pragmatische Architekturentscheidungen löst. Der Fokus lag nie nur auf roher Rechenpower, sondern auf der Balance zwischen Geschwindigkeit, Speicherverbrauch, Wartbarkeit und Nutzererfahrung. Ausblickend plant das VS Code Team weitere Verbesserungen. Verbesserungen bei der Suche sollen künftig auch nicht zeilenweise funktionieren, um unnötige Aufrufe an teure Methoden zu vermeiden.
Außerdem sind effizientere Zugriffe geplant, bei denen keine kompletten Zeilenstrings generiert werden müssen, wie zum Beispiel das direkte Auslesen einzelner Zeichen ohne vollständige Kopien. In der Summe war die Neuentwicklung des Textpuffers 2018 ein essentieller Schritt, der VS Code half, seine Leistungsfähigkeit und Skalierbarkeit zu erhöhen. Gerade im Zeitalter riesiger Codebasen und vielseitiger Entwicklungsumgebungen verdient dieses Projekt als technisches Meisterwerk und erfolgreiches Beispiel nachhaltiger Performanceoptimierung besondere Beachtung.