Die moderne Datenanalyse entwickelt sich ständig weiter, getrieben von der wachsenden Datenmenge und dem Bedarf an immer schnelleren, flexibleren Datenverarbeitungsmöglichkeiten. In diesem Kontext gewinnt die Lakehouse-Architektur zunehmend an Bedeutung, da sie die Vorteile von Data Lakes und Data Warehouses vereint. Im Zentrum vieler solcher Architekturen steht die Fähigkeit, Daten im Parquet-Format effizient zu verarbeiten, einem spaltenbasierten Speicherformat, das besonders für analytische Workloads optimiert ist. ClickHouse hat sich in diesem Bereich als eine leistungsfähige, vielseitige Datenbank-Engine etabliert, die gezielt für schnelle Analyseanfragen auf Parquet-Dateien ausgelegt ist.ClickHouse existierte schon, bevor Begriffe wie „Lakehouse“ überhaupt geprägt wurden.
Ursprünglich als OLAP-Datenbank für Hochgeschwindigkeitsanalysen konzipiert, unterstützt ClickHouse von Haus aus zahlreiche Datenformate, unter anderem Parquet. Seine Fähigkeit, Parquet-Dateien direkt zu lesen und abzufragen – ohne vorherige Datenaufnahme oder -transformation – macht ClickHouse zu einem unverzichtbaren Werkzeug im modernen Data-Engineering-Toolset.Die Architektur von ClickHouse ermöglicht es, Daten unabhängig davon zu verarbeiten, wo sie gespeichert sind: ob on-premise, in der Cloud oder in hybridem Betrieb. Mit nativen Integrationen in Speicherlösungen wie Amazon S3, Google Cloud Storage oder Azure Blob Storage können Anwender enorme Datenmengen in Parquet-Format speichern und ad hoc direkt darauf zugreifen. Diese Flexibilität ist entscheidend für Unternehmen, die datengetriebene Entscheidungen in Echtzeit oder nahezu in Echtzeit treffen wollen, ohne sich den Aufwand und die Kosten eines vollständigen Datenimports aufzuerlegen.
Ein wesentliches Element der hohen Leistung bei der Abfrage von Parquet-Daten in ClickHouse ist die intelligente Parallelisierung. Parquet-Dateien sind strukturiert in sogenannte Row Groups und Column Chunks – also horizontale sowie vertikale Partitionen der Daten. Diese Struktur erlaubt es ClickHouse, die Arbeit effektiv auf mehrere CPU-Kerne zu verteilen. Selbst innerhalb einer einzelnen Datei können unterschiedliche Teile zeitgleich verarbeitet werden, wodurch ein Maximum an Rechenressourcen genutzt wird. Neben der parallelen Verarbeitung über mehrere Dateien hinweg erzielt ClickHouse so eine bemerkenswerte Skalierbarkeit.
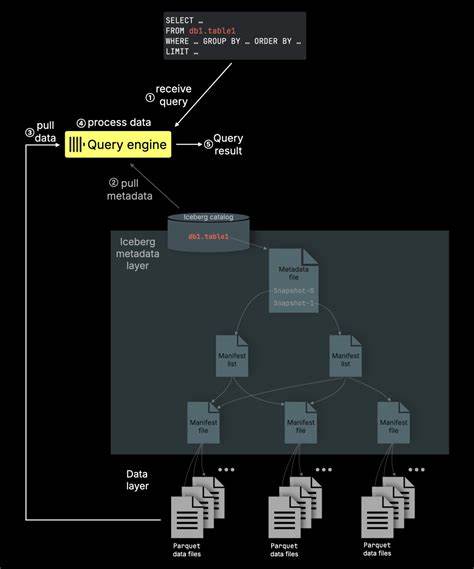
Die Parquet-Reader-Komponente von ClickHouse liest zunächst die Parquet-Daten mithilfe der Apache Arrow-Bibliothek und wandelt sie anschließend in das native In-Memory-Format von ClickHouse um. In Planung ist eine noch effizientere, native Parquet-Lesemethode, die die Zwischenschicht von Arrow eliminiert. Dies wird nochmals die I/O-Leistung optimieren und die Latenzzeiten bei komplexen Abfragen reduzieren. Die Einführung dieser neuen Reader-Version verspricht außerdem die Unterstützung für fein granularere Parallelisierungsstrategien wie die gleichzeitige Verarbeitung unterschiedlicher Spalten innerhalb eines Row Groups.Parallel zum Thema Parallelität spielt die Minimierung unnötiger I/O-Vorgänge eine zentrale Rolle für die Performance.
Parquet-Dateien speichern umfangreiche Metadaten, die eine präzise Filterung und Reduktion der eingelesenen Datenmenge ermöglichen. So können zum Beispiel min/max-Statistiken auf Zeilengruppenebene oder Bloom-Filter eingesetzt werden, um Datenblöcke gezielt auszuschließen, die den Suchkriterien nicht entsprechen. ClickHouse nutzt diese Mechanismen bereits effektiv, um nur die relevanten Datenpakete einzulesen, was besonders bei großen Datenbeständen eine enorme Zeitersparnis bedeutet.Trotz der schon hohen aktuellen Leistungsfähigkeit gibt es bei ClickHouse noch Entwicklungspotenzial, etwa durch die Integration hermetischer Optimierungen wie PREWHERE-Abfragen und lazy materialization. Sobald der native Parquet-Reader diese Funktionen unterstützt, werden weitere signifikante Verbesserungen in der Abfragegeschwindigkeit erreicht.
Diese Methoden erlauben es, erst Teile der Daten vorzuselektieren, bevor nachgelagerte Operationen ausgeführt werden, wodurch unnötige Arbeitsschritte vermieden werden.Die reale Leistungsfähigkeit von ClickHouse bei Parquet-Daten lässt sich in Benchmark-Tests ablesen, in denen verschiedene analytische Abfragen über riesige Datenmengen von 100 Millionen Zeilen ausgeführt wurden. Dabei zeigte ClickHouse beachtliche Ergebnisse mit Zeithorizonten von wenigen hundert Millisekunden für komplexe Abfragen. Obwohl die native MergeTree-Engine von ClickHouse, die speziell für Ingested Data optimiert ist, noch etwas schneller ist, muss man bedenken, dass Parquet als universelles Dateiformat mit vielen flexiblen Anwendungsfällen nicht primär auf maximale Performance getrimmt ist. ClickHouse gelingt es trotzdem, die Performance-Lücke zum spezialisierten MergeTree-Format signifikant zu verkürzen.
Zusätzlich überzeugte ClickHouse bei Vergleichen mit anderen populären Technologien wie PostgreSQL, Elasticsearch oder MongoDB. Während diese Systeme oft langsamer sind, vor allem bei großen datenintensiven Scan- und Aggregationsvorgängen, lagen die Parquet-Abfragen auf ClickHouse beispielhaft vorne. Die Kombination aus fortschrittlichen I/O-Reduktionsmechanismen, aggressiver Parallelisierung und effizienter Nutzung von Metadaten machen ClickHouse zu einer herausragenden Wahl für Lakehouse-Szenarien.Neben der reinen Performance punktet ClickHouse auch mit seiner Flexibilität. Die Engine kann im Cloud-Umfeld betrieben werden, etwa auf AWS, Google Cloud oder Azure, und es gibt voll gemanagte Versionen wie ClickHouse Cloud.
Unternehmen können aber auch ein Bring Your Own Cloud-Prinzip verfolgen und ClickHouse in ihrer eigenen Cloud-Infrastruktur betreiben. Das System skaliert mühelos von einzelnen Knoten bis hin zu großen Clusterumgebungen, was den Zugriff auf Parquet-Daten über mehrere Maschinen hinweg effizient koordiniert.Die Kombination aus Parquet und ClickHouse stellt die Basis für zukunftssichere Lakehouse-Lösungen dar. Diese Architekturen benötigen nicht nur schnelle Lesezugriffe auf große, unstrukturierte Datenbestände, sondern auch die Fähigkeit zur nahtlosen Integration von Daten aus unterschiedlichen Quellen. Dank über 80 nativer Integrationen und umfassender Unterstützung zahlreicher Dateiformate ist ClickHouse prädestiniert, dieser Herausforderung gerecht zu werden.
Abschließend lässt sich festhalten, dass ClickHouse bereits heute vieles von dem anbietet, was moderne Lakehouse-Architekturen fordern. Die Performance bei direkten Parquet-Abfragen ist beeindruckend, die geplanten Weiterentwicklungen versprechen zusätzliches Potenzial. Durch diese Kombination ist ClickHouse nicht nur ein schneller Analytics-Server, sondern eine strategische Plattform für zukunftsorientierte Datenanalyse, die den Spagat zwischen Data Lakes und Data Warehouses souverän meistert.Die Zukunft wird zeigen, wie sich die Integration weiterer Lakehouse-Features – wie zum Beispiel umfassende Metadatenverwaltung und Transaktionsmanagement im Stil von Iceberg oder Delta Lake – in ClickHouse gestaltet. Doch schon jetzt stellt die flexible, leistungsoptimierte Abfrage von Parquet-Dateien eine solide Basis dar, auf der Analysten, Dateningenieure und Unternehmen komplexe Insights gewinnen können.
Die Kombination aus etablierter Technologie und innovativen Optimierungen macht ClickHouse zu einem unverzichtbaren Baustein moderner Datenstrategien.