In einer Welt, in der digitale Inhalte exponentiell wachsen, stellt die Suche nach ähnlichen Objekten in großen Datenmengen eine enorme Herausforderung dar. Traditionelle Suchmaschinen stoßen an ihre Grenzen, wenn es darum geht, komplexe, hochdimensionale Daten zu verarbeiten. Genau hier kommt Faiss ins Spiel, eine von Facebook AI Research entwickelte Open-Source-Bibliothek, die eine schnelle und skalierbare Ähnlichkeitssuche ermöglicht. Diese Technologie revolutioniert die Art, wie wir Multimedia-Daten wie Bilder, Videos oder Textdokumente durchsuchen und verarbeiten. Ähnlichkeitssuche und ihre Herausforderungen Herkömmliche relationale Datenbanken arbeiten mit strukturierten Daten in Tabellenform.
Bei einer Bilddatenbank würde man die einzelnen Bilder mit symbolischen Informationen wie einer Bild-ID oder Textbeschreibungen verknüpfen. Diese klassischen Systeme sind jedoch nicht dafür geschaffen, die komplexen Beziehungen in Daten wie Vektorrepräsentationen abzubilden, die durch maschinelles Lernen und neuronale Netze erzeugt werden. Bei solchen Vektoren handelt es sich um hochdimensionale Zahlenarrays, die die Eigenschaften eines Objektes in einem mehrdimensionalen Raum darstellen. Die Suche nach Ähnlichkeiten in diesen Vektorräumen basiert auf mathematischen Konzepten wie der euklidischen Distanz oder dem Skalarprodukt, was sich grundlegend von herkömmlichen Schlüssel-Wert-Abfragen unterscheidet. Dies führt zu zwei zentralen Herausforderungen.
Zum einen müssen gigantische Mengen von Vektoren, teilweise in Milliardenhöhe, in Echtzeit durchsuchbar sein. Zum anderen ist die Berechnung von Abständen oder Ähnlichkeiten in hochdimensionalen Räumen enorm rechenintensiv, weswegen herkömmliche Systeme hier nicht performant agieren können. Die Rolle von Vektorrepräsentationen Mithilfe von Algorithmen wie word2vec, CNN-basierter Bildverarbeitung oder anderen Deep-Learning-Techniken werden Objekte in Form von Vektoren kodiert. Diese Vektoren fassen komplexe Merkmale kompakt zusammen und ermöglichen Anwendungen, bei denen Objekte durch ihre Nähe zueinander im Vektorraum als ähnlich identifiziert werden. So kann beispielsweise ein Bild eines Gebäudes in einem großen Bildarchiv anhand seiner Vektorrepräsentation ähnliche Fotos des gleichen Gebäudes finden, selbst wenn kein Name oder eine Textbeschreibung existieren.
Neben der Suche nach ähnlichen Objekten wird der Vektorraum auch für Klassifikationen genutzt. Klassifikatoren generieren Vektoren, deren Skalarprodukt mit einem Bildvektor angibt, wie wahrscheinlich es ist, dass das Bild ein bestimmtes Objekt – etwa eine Blume – enthält. Solche Anfragen nach maximalem innerem Produkt erfordern ebenfalls effiziente Algorithmen, um bei großen Datenbanken praktikable Antwortzeiten zu gewährleisten. Warum traditionelle Datenbanksysteme nicht ausreichen Standard-SQL-Datenbanken sind für Anfragen auf Schlüsselwerten oder eindimensionalen Bereichen ausgelegt. Diese Systeme zeichnen sich durch schnelle Zugriffe mittels Hash-Tabellen oder Indizes aus, sind jedoch ungeeignet, um Ähnlichkeiten in hochdimensionalen Vektorräumen akkurat zu ermitteln.
Ähnlichkeitssuche erfordert komplexe Berechnungen, die mit herkömmlichen Datenbanksystemen entweder unakzeptabel lange dauern oder gar nicht realisierbar sind. Zudem entstehen in modernen Multimedia-Anwendungen riesige Datenmengen mit Milliarden von Vektoren. Die Speicherung und Verarbeitung dieser Daten auf Festplatten sind viel zu langsam, weshalb die Suche üblicherweise vollständig im Arbeitsspeicher (RAM) stattfinden muss. Dies erfordert zudem hochoptimierte Speicher- und Rechenverfahren, damit die Suche auch bei massiven Datenmengen in Echtzeit funktioniert. Faiss – innovative Technologien für die Ähnlichkeitssuche Das von Facebook AI Research entwickelte Faiss-Bibliothekspaket wurde genau geschaffen, um diese Herausforderungen zu meistern.
Faiss bietet eine Sammlung verschiedener Algorithmen, die ein breites Spektrum an Performance- und Genauigkeitsanforderungen abdecken. Von exakten Durchläufen bis hin zu approximativen Methoden, die eine Balance zwischen Geschwindigkeit und Genauigkeit ermöglichen, ist Faiss modular aufgebaut und bietet für verschiedene Anwendungsfälle die passende Lösung. Ein Kernelement von Faiss ist die Verwendung produktquantisierter Vektoren (PQ). Durch eine komplexe Vorverarbeitung und Komprimierung werden die Ursprungsvektoren auf wenige Dutzend Bytes reduziert, wodurch der Speicherbedarf drastisch sinkt. Gleichzeitig können Berechnungen auf diesen komprimierten Repräsentationen trotzdem mit hoher Qualität und Geschwindigkeit erfolgen.
Dies erlaubt es Faiss, mit Datenmengen im Milliardenbereich umzugehen, was für traditionelle Systeme undenkbar wäre. Dank zahlreicher technischer Optimierungen ist Faiss in der Lage, mehrere tausend Suchanfragen pro Sekunde solo auf einer CPU zu bewältigen. Zusätzlich kann das System auf moderne GPUs ausweichen, die dank ihrer massiven parallelen Rechenkapazitäten die Performance nochmal drastisch erhöhen. Leistungsstarke GPU-Beschleunigung Faiss nutzt die Leistungsfähigkeit moderner Nvidia-GPUs der Compute Capability 3.5 und höher.
Die GPU-Version der Bibliothek bietet eine bis zu zwanzigfache Beschleunigung gegenüber CPU-Implementierungen, insbesondere auf moderner Pascal-Hardware wie der P100. Hierfür wurde ein spezieller, hochoptimierter Algorithmus für die sogenannte k-Auswahl entwickelt, mit dem innerhalb eines einzigen Durchlaufs die k besten Ergebnisse aus großen Datenströmen extrahiert werden können. Diese k-Auswahl gilt als eine der Flaschenhälse bei der Ähnlichkeitssuche auf GPUs, da klassische Verfahren wie Heaps nicht gut parallelisierbar sind. Faiss verarbeitet die k besten Vektoren parallel im GPU-Registerspeicher, was die Geschwindigkeit und Effizienz enorm steigert. Der automatische Datentransfer zwischen CPU und mehreren GPUs erfolgt nahtlos und ermöglicht Multi-GPU-Setups, die auch bei extrem großen Datensätzen skalieren.
Praktische Anwendungen und Evaluationen Faiss wurde anhand realer, milliardenschwerer Vektor-Datensätze evaluiert. Ein bekannter Benchmark ist Deep1B – eine Sammlung von einer Milliarde Bildvektoren, die mit CNNs extrahiert wurden. Für diesen Datensatz liefert Faiss bei einer Beschränkung von 30 GB RAM und einem genialen Indexierungsaufbau eine ausgezeichnete Balance zwischen Speicherbedarf, Genauigkeit und Geschwindigkeit. Beispielsweise erreicht die Suche nach den nächsten Nachbarn bei einer 1-recall@1-Genauigkeit von rund 40 Prozent eine Abfragezeit von circa zwei Millisekunden auf einer einzigen CPU-Kern. Diese Werte übertreffen früheren Stand der Technik bei weitem.
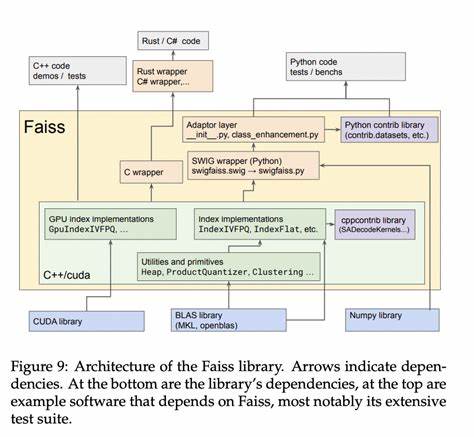
Forschungsergebnisse, die zur Einführung des Deep1B-Datensatzes veröffentlicht wurden, benötigten für vergleichbare Genauigkeitswerte viele Millisekunden pro Anfrage – ein deutlicher Nachweis für die Innovationskraft von Faiss. Neben der reinen Suche erlaubt Faiss auch die Konstruktion von k-Nachbarn-Grafen (k-NN-Grafen) in beeindruckenden Zeiträumen mittels GPU-Beschleunigung. So lassen sich auf acht P100-GPUs k-NN-Grafen für eine Milliarde Vektoren in nur wenigen Stunden erstellen, was neue Möglichkeiten für die Strukturierung und Analyse großer Datensätze eröffnet. Einfache Integration und vielseitige Nutzung Faiss ist in C++ geschrieben und verfügt über Python-Bindings, sodass Entwickler und Data Scientists unkompliziert auf die Bibliothek zugreifen können. Die enge Integration mit numpy erleichtert die Nutzung in bekannten Data-Science-Workflows erheblich.
Über das Index-Konzept lassen sich diverse Index-Strukturen konfigurieren, mit denen Vektoren gespeichert, durchsucht und bei Bedarf auch nachträglich hinzugefügt oder gelöscht werden können. Dank der flexiblen Index-Hierarchien kombiniert Faiss verschiedene Suchverfahren in modularen Pipelines je nach Anwendungsfall. Das ermöglicht es, sowohl exakte als auch approximate Suchen effizient zu gestalten und das konkrete Geschwindigkeits- und Genauigkeitsverhältnis für die jeweilige Aufgabe zu optimieren. Fazit Faiss stellt eine Meilenstein-Bibliothek für die Ähnlichkeitssuche in großen Vektordatenbanken dar. Sie schließt eine wichtige Lücke in der Verarbeitung moderner, unstrukturierter Multimedia-Datenmengen, die mit traditionellen hochstrukturierten Datenbanksystemen nicht zufriedenstellend zu bewältigen sind.
Die Kombination aus ausgeklügelten Komprimierungsverfahren, CPU- und GPU-Optimierungen sowie einer intelligenten Indexierung macht Faiss zur bevorzugten Lösung für Industriestandards rund um die Vektorähnlichkeitssuche. Damit eröffnet Faiss in Bereichen wie Bildersuche, Empfehlungssystemen, Dokumentenklassifikationen und vielen weiteren KI-Anwendungen völlig neue Leistungsdimensionen. Wer auf der Suche nach einer skalierbaren, effizienten und gut unterstützten Bibliothek für die Ähnlichkeitssuche ist, findet mit Faiss ein leistungsfähiges Werkzeug, das den Anforderungen von heute und morgen gerecht wird.






![Tulsi Gabbard on Her Visit to Hiroshima [video]](/images/603CD375-D6BD-4EE2-990A-09E92A7F519C)