Seit den 1960er Jahren prägen relationale Datenbanken mit globalem, gemeinsam genutztem und veränderlichem Zustand die Welt der Datenverarbeitung. Trotz der vielfältigen NoSQL-Alternativen hat sich an diesem grundlegenden Prinzip kaum etwas geändert. Interessanterweise haben sich Entwickler längst von veränderlichen globalen Variablen im Programmcode verabschiedet – doch in der Datenbankabfrage- und Speicherwelt hält man unbeirrt an eben diesem Muster fest. Warum tolerieren wir also diese Form von gemeinsamem, veränderlichem Zustand auf Systemebene? Die Antwort ist meist schlicht Gewohnheit und vorhandene Werkzeuge, die wenig Alternativen bieten. Dabei eröffnen sich mit neuen Modellen riesige Potenziale für bessere, effizientere und skalierbarere Systeme.
Ein zukunftsweisender Ansatz sieht Datenbanken nicht als veränderlichen Speicher, sondern als eine ständig anwachsende Sammlung unveränderlicher Fakten. Diese sogenannten Immutable Events tragen den status quo über die Zeit hinweg mit sich und erlauben es, statt der herkömmlichen imperativen Abfragen auf Momentaufnahmen vielmehr in Echtzeit eingehende Datenströme funktional zu verarbeiten. Genau hier setzt Apache Samza an, ein von LinkedIn entwickeltes Framework für verteilte Stream-Verarbeitung. Samza nutzt die Logik eines veränderlichen Datenbanksystems, dreht es jedoch sprichwörtlich von innen nach außen, indem es das bisher verborgene technische Kernstück – den Append-Only Commit Log – ins Zentrum des Architekturmodells rückt. Apache Kafka bildet hierbei das Fundament.
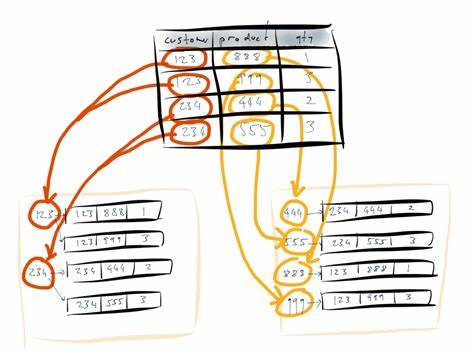
Kafka ist eine hochskalierbare, verteilte, dauerhafte Commit-Log-Plattform, die alle eingehenden Daten als sequentielle Event-Streams auffasst und abspeichert. Dieses Logs werden nicht überschrieben oder verändert, sondern nur fortlaufend erweitert. In traditionellen Datenbanken ist der Änderungsverlauf oft verborgen oder wird früh überschrieben, wodurch wichtige historische Informationen verloren gehen. Durch Kafka aber wird jeder einzelne Datenpunkt permanent gespeichert und bleibt jederzeit zugänglich. Auf dieser Grundlage ermöglichen Systeme wie Samza, aus diesen unveränderlichen Ereignissen kontinuierlich abgeleitete Sichtweisen, sogenannte Materialized Views, zu generieren.
Das sind spezialisierte, für schnelle Lesezugriffe optimierte Datenstrukturen, die aus der unveränderlichen Ereigniskette erstellt und kontinuierlich aktualisiert werden. Dieser Paradigmenwechsel bringt zahlreiche Vorteile mit sich. Zum einen werden durch die Trennung von Schreiben und Lesen Komplexität und Fehlerquellen im System deutlich reduziert. Das Schreiben in den logbasierten Speicher ist extrem performant und gleichzeitig einfach zu verwalten, da es nur sequentielles Anhängen bedeutet. Auf der Leseseite hingegen können beliebig viele Materialized Views parallel existieren, die verschiedene Anwendungsfälle abdecken – sei es schnelle Key-Value-Suchen, komplexe Join-Operationen oder sogar Volltextsuchen.
Dieses Entkopplungsmuster eröffnet vielseitige Möglichkeiten und bedeutet für Entwickler ein höheres Maß an Flexibilität und Agilität. Darüber hinaus beseitigt der Ansatz auch klassische Probleme aktueller Architekturen. Beispielsweise ist das Thema Caching, eines der ungeliebten Kapitel vieler Entwickler, hier wesentlich leichter zu handhaben. Während traditionelles, anwendungsseitiges Caching mit Cache-Invaliderungen, Rennbedingungen und kaltem Start kämpft, übernehmen Materialized Views genau diese Rolle auf Infrastruktur-Ebene. Sie sind von Natur aus konsistent, werden kontinuierlich aus dem unveränderlichen Log abgeleitet und müssen nicht aufwändig invalidiert oder synchronisiert werden.
Das reduziert nicht nur die Komplexität des Anwendungscodes, sondern sorgt auch für stabilere und vorhersehbarere Systeme. Die Auswirkungen auf Skalierbarkeit und Latenz sind ebenfalls bemerkenswert. Da Apache Kafka und Samza verteilte Systeme sind, können sie problemlos horizontal wachsen, um steigenden Datenmengen gerecht zu werden. Die sequentielle Log-Struktur erlaubt effiziente Schreiboperationen, die kaum Flaschenhälse erzeugen. Gleichzeitig ermöglichen Materialized Views schnelle Abfragen auf den abgeleiteten Daten, ohne die Schreiblaste zu stören.
Kombiniert mit einer robusten Fehlerbehandlung und Wiederherstellung aus den Events sind Systeme gebaut mit diesem Muster hochverfügbar und widerstandsfähig gegen Störungen. Ein weiterer Vorteil ist die Nachvollziehbarkeit und Auditierbarkeit von Datenänderungen. Ein unveränderlicher Event-Stream ermöglicht beispielsweise eine präzise zeitliche Rückverfolgung aller Datenänderungen, was klassische Datenbanken oft nur eingeschränkt bieten können. Sei es für Debugging, Compliance oder analytische Zwecke – die klare und vollständige Historie jeder Änderung ist ein enormer Gewinn. Es ist wichtig zu erwähnen, dass der Weg hin zu einer auf logbasierten, unveränderlichen Events beruhenden Architektur keine einfache Aufgabe ist.
Ganz im Gegenteil: Es handelt sich um einen tiefgreifenden Wandel, der auch neue Denkweisen, Werkzeuge und Prozesse fordert. Legacy-Systeme und deren Abhängigkeiten müssen berücksichtigt, bestehende Datenmodelle überdacht und neue Paradigmen in Softwareentwicklung und Betrieb etabliert werden. Doch die Investition lohnt sich langfristig, da Systeme dadurch skalierbarer, flexibler und zuverlässiger werden. Das Konzept der unveränderlichen Logs und deren Nutzung für Datenverarbeitung ist nicht neu – es wird unter dem Begriff Event Sourcing, dem Lambda-Architektur-Pattern oder im Kontext moderner Datenbanken wie Datomic schon seit Jahren diskutiert. Apache Samza verbindet diese theoretischen Konzepte mit praktischen Werkzeugen zur realen Umsetzung in großen, verteilten Infrastrukturen.
Insbesondere in Kombination mit Kafka als Basisplattform entstehen so Lösungen, die sowohl für Echtzeit-Analysen als auch für den produktiven Betrieb hochskalierbarer Anwendungen geeignet sind. Durch die Nutzung von Samza verschiebt sich die Verantwortung für Datenverarbeitung und Caching deutlich vom Anwendungsentwickler hin zur Plattform. Entwickler können ihre Aufmerksamkeit mehr auf Geschäftslogik und Anwendungsfunktionen richten, während die Dateninfrastruktur sich um Beständigkeit, Performance und Konsistenz kümmert. Neue Sichten auf die Daten lassen sich flexibel hinzufügen, ohne umfangreiche Migrationen oder Ausfallzeiten, da sie einfach neu aus dem Log aufgebaut und parallel betrieben werden können. Zusätzlich lässt sich durch diese Architektur auch das Thema Echtzeit-Interaktivität besser adressieren.
Wenn Materialized Views ständig aktualisiert werden, können Clients theoretisch auf Änderungen reagieren und Live-Updates erhalten. Das nutzt Frameworks wie React oder Angular im Frontend effektiv und verbessert die Benutzererfahrung signifikant. Statt statischer Abfragen entsteht so ein dynamisches, reaktives System, das weit über den traditionellen Request-Response-Zyklus hinausgeht. Es wird klar, dass das alte Modell mit einem monolithischen, veränderlichen Datenbanksystem zunehmend an seine Grenzen stößt, wenn es um moderne Anforderungen wie Skalierbarkeit, Echtzeitverarbeitung und hohe Verfügbarkeit geht. Apache Samza zeigt, wie eine Innenkehr der Datenbankarchitektur auf Basis von Immutable Streams und Materialized Views dazu beiträgt, diese Herausforderungen zu meistern.
Die Trennung von Schreib-Kommando und Lese-Sicht ist dabei das zentrale Gestaltungsmuster für Systeme der Zukunft. Die Zukunft der Datenbankarchitektur liegt in der konsequenten Ausrichtung auf unveränderliche Ereignisströme, die als zentrale Quelle der Wahrheit dienen. Alle weiteren Datenformen, Abfragen und Caches sind davon abgeleitet und jederzeit reproduzierbar. Systeme auf dieser Grundlage profitieren von besserer Wartbarkeit, leichterer Fehlerbehandlung und höherer Datenqualität. Apache Samza ist ein überzeugendes Beispiel dafür, wie man diesen modernen Ansatz heute schon realisieren kann.
Wer sich mit der Gestaltung großer verteilter Systeme beschäftigt, sollte die Prinzipien hinter Apache Samza und Kafka genau kennen. Sie bieten einen gut nachvollziehbaren, skalierbaren und robusten Weg, der weit über die traditionelle Anwendung von Datenbanken hinausgeht. Ebenso wichtig ist das Wechseln der Perspektive weg von global veränderlichem Zustand hin zu Streams von unveränderlichen Fakten. Nur so lassen sich die Herausforderungen moderner Anwendungen und deren enormer Datenmengen zukunftssicher bewältigen. Damit steht überraschenderweise kein technischer Phantastik-Code im Zentrum, sondern ein fundamentales Umdenken in der Art, wie wir Daten speichern, verarbeiten und konsumieren.
Apache Samza ist mehr als nur ein Framework zur Stream-Verarbeitung. Es ist der tragfähige Baustein für eine neue Generation von Datenbanken und Backend-Architekturen, die schon heute die Grundlage vieler großer Online-Systeme bilden und weiter wachsen werden.