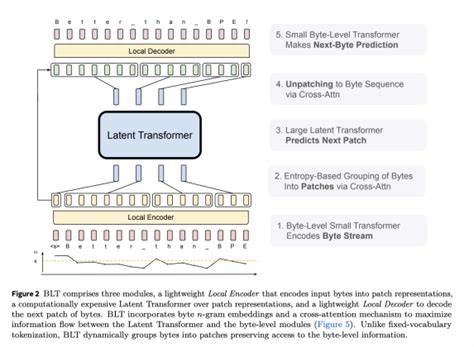
Die Welt der natürlichen Sprachverarbeitung (Natural Language Processing, NLP) steht niemals still. Ständig entstehen neue Technologien und Methoden, die darauf abzielen, Sprache besser zu verstehen und effizienter zu verarbeiten. Eine der spannendsten jüngsten Entwicklungen kommt von Meta mit ihrem sogenannten „tokenizer-free“ Patcher. Diese innovative Lösung verspricht, die Art und Weise grundlegend zu verändern, wie Sprachmodelle trainiert und angewandt werden. Im Folgenden wird erklärt, was genau Meta mit dem tokenizer-free Patcher vorstellt, wie diese Technologie funktioniert und welche Vorteile sie mit sich bringt.
Traditionell basieren die meisten NLP-Modelle auf Tokenizern – speziellen Programm-Modulen, die Text in einzelne Bestandteile, sogenannte Tokens, aufspalten. Diese Tokens können Wörter, Wortteile oder sogar einzelne Buchstaben sein. Tokenizer helfen dabei, Text in eine Form zu bringen, die von Modellen verarbeitet werden kann. Jedoch bringen Tokenizer auch Herausforderungen mit sich: Sie sind häufig auf bestimmte Sprachen spezialisiert, können fehleranfällig sein und erzeugen oftmals Komplexität beim Training und der Anwendung von Modellen. Hier setzt die Technologie von Meta mit dem tokenizer-free Patcher an.
Anstatt den Text vorzuverarbeiten und in Tokens zu unterteilen, ermöglicht dieser Patcher eine direkte Verarbeitung des Textes. Das bedeutet, dass der gesamte Workflow von der Textaufnahme bis zur Modellausgabe nahtloser und effizienter gestaltet wird. Entwickler und Forscher erhalten somit ein Werkzeug, das die Notwendigkeit herkömmlicher Tokenizer eliminiert und dadurch eine Reihe von Vorteilen mit sich bringt. Ein wesentlicher Vorteil des tokenizer-free Stichprinzips ist die Reduzierung von Fehlerquellen. Da traditionelle Tokenizer oftmals auf spezifische Wortgrenzen oder Sprachmuster optimiert sind, können sie bei unbekannten Wörtern oder Dialekten Fehler machen.
Das führt dazu, dass NLP-Modelle auf fehlerhafte Daten reagieren müssen, was die Genauigkeit und Leistung mindert. Mit dem tokenizer-free Patcher entfällt diese mögliche Fehlerquelle, denn der Text wird ganzheitlich betrachtet und direkt verarbeitet. Darüber hinaus eröffnet der tokenizer-free Ansatz eine höhere Flexibilität. Modelle, die ohne vorherige Tokenisierung auskommen, sind weniger abhängig von Sprach- oder Domänenspezifika. Das ist besonders relevant in einer globalisierten Welt, in der es unzählige Sprachen und Dialekte gibt, die von herkömmlichen Tokenizern nur schwer abgedeckt werden können.
Meta ermöglicht mit diesem Patchersystem somit eine verbesserte Adaptierung von NLP-Modellen auf verschiedenste Sprachkontexte. Nicht zu unterschätzen ist auch der Einfluss auf die Entwicklererfahrung. Das Einfügen des tokenzierfreien Patchers in bestehende Modelle kann die Komplexität der Entwicklungsprozesse deutlich reduzieren. Entwickler müssen sich nicht mehr mit fehleranfälligen Tokenizer-Konfigurationen beschäftigen, was Entwicklungszyklen beschleunigt und die Einstiegshürden für NLP-Projekte verringert. Außerdem steigt die Übersichtlichkeit des Codebases, da eine weniger komplexe Vorverarbeitung zu einem klareren Modell-Workflow führt.
Die Integration des tokenizer-free Patchers ist dabei nicht auf bestimmte Anwendungen begrenzt. Von Chatbots über maschinelle Übersetzung bis hin zur Textanalyse profitieren diverse Bereiche von einer effizienteren und fehlerärmeren Sprachverarbeitung. Insbesondere bei Zero-Shot-Anwendungen, bei denen Modelle ohne spezielles Training auf neue Aufgaben reagieren, zeigt der tokenizer-free Ansatz seine Stärken. Hier sorgt er für robustere Ergebnisse, da weniger Abhängigkeiten von spezifischen Textstrukturen bestehen. Neben den technischen Vorteilen adressiert Meta mit dem tokenizer-free Patcher auch die Herausforderung der Skalierbarkeit.
NLP-Modelle wachsen zunehmend in ihrer Komplexität und Größe, wodurch die Vorverarbeitungsschritte zu einem Flaschenhals werden können. Indem die Tokenisierung entfällt, entlastet Meta das gesamte System und schafft so Raum für größere und leistungsfähigere Modelle, ohne dass die Vorverarbeitung zum limitierenden Faktor wird. Darüber hinaus bietet der tokenizer-free Patcher eine verbesserte Kompatibilität mit unterschiedlichen Dateiformaten und Plattformen. Beispielsweise ist das Patchersystem so konstruiert, dass es nahtlos in bestehende Speicherungssysteme und App-Umgebungen integriert werden kann. Das fördert eine breitere Nutzung, sowohl im Community-Bereich als auch für kommerzielle Anwendungen.
Die Anpassungsfähigkeit des Patchers sorgt dafür, dass Entwickler die Technologie in vielfältigen Kontexten einsetzen und von den Vorteilen profitieren können. Ein spannendes Anwendungsgebiet für den tokenizer-free Patcher ist auch das Training von Modellen mit hohen Entropien, bei denen große Unsicherheiten im Sprachmaterial bestehen. Traditionelle Tokenizer haben bei solchen Aufgaben oft Schwierigkeiten, angemessen zu reagieren. Meta geht mit seinem Konzept der Entropie-Patchers neue Wege, indem sie mit einem adaptiven Mechanismus auf Unsicherheiten reagieren. So lassen sich präzisere Modelle konstruieren, die auch in komplexen Sprachsituationen stabile Leistungen zeigen.
Im Endeffekt steht der tokenizer-free Patcher exemplarisch für eine technologische Entwicklung, die NLP-Modelle leichter zugänglich, flexibler und robuster macht. Indem Meta die wichtigsten Schwachstellen der Tokenisierung überwindet, setzt das Unternehmen einen neuen Standard für die zukünftige Forschung und Entwicklung im Bereich der künstlichen Sprachverarbeitung. Die Kombination aus technischer Effizienz und einfacher Integration macht den tokenizer-free Patcher zu einem Werkzeug mit großem Potenzial. Die Community reagiert bereits positiv auf die Veröffentlichung dieser Technologie. Entwickler aus der ganzen Welt experimentieren mit dem Patchersystem, tauschen Erfahrungen aus und tragen zur kontinuierlichen Verbesserung bei.
Das Engagement und die Zusammenarbeit stellen sicher, dass der tokenizer-free Patcher nicht nur eine technische Spielerei bleibt, sondern zu einem festen Bestandteil moderner NLP-Workflows wird. Abschließend lässt sich festhalten, dass der tokenizer-free Patcher von Meta einen wichtigen Schritt in Richtung vereinfachter und effizienterer Sprachmodellierung darstellt. Die Möglichkeit, auf traditionelle Tokenizer zu verzichten, eröffnet eine breite Palette an neuen Möglichkeiten für die Verarbeitung natürlicher Sprache. Sowohl für Entwickler als auch für Anwender ist diese Innovation ein bedeutender Fortschritt, der langfristig die Qualität und Leistungsfähigkeit von KI-gesteuerten Sprachlösungen verbessern wird.