Die rasante Entwicklung im Bereich der künstlichen Intelligenz (KI) und insbesondere bei neuronalen Netzwerken hat immer wieder neue Architekturen hervorgebracht, die leistungsstärker und effizienter sind. Eine solche innovative Methode ist die Sparsely-Gated Mixture of Experts (MoE), die einen entscheidenden Fortschritt hinsichtlich der Kapazität von Modellen bei gleichzeitig reduzierten Rechenressourcen darstellt. Diese Technologie hat insbesondere im Kontext von Transformer-Modellen enormen Einfluss gewonnen und eröffnet neue Möglichkeiten für die Skalierung und Anwendung von KI-Systemen. Transformer-Architekturen sind heute das Fundament vieler moderner Anwendungen, von natürlicher Sprachverarbeitung bis hin zu Bildverarbeitung. Zentral im Transformer ist der Aufmerksamkeit-Mechanismus, der die Verknüpfung zwischen unterschiedlichen Elementen eines Inputs herstellt.
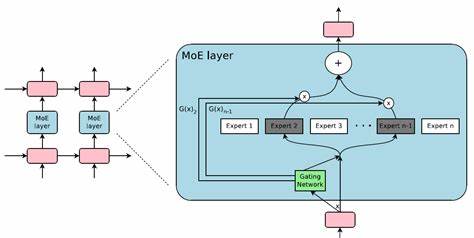
Direkt im Anschluss folgt häufig eine Feed-Forward-Schicht, die für die eigentliche „Verarbeitung“ der Daten zuständig ist. Diese Schicht hat normalerweise eine große Anzahl an Parametern, weil die versteckte Zwischenschicht oft mehrere Male größer als die Eingabedimension ausgelegt ist, um genügend Kapazität für komplexe Aufgaben zu bieten. Das Problem hierbei ist, dass für sehr große Modelle, die aus vielen Transformer-Blöcken bestehen, die Anzahl der Parameter und somit auch die Rechen- und Speicheranforderungen rapide ansteigen. Hier setzt die Sparsely-Gated Mixture of Experts Methode an und bietet eine elegante Lösung. Die Grundidee hinter MoE ist das Aufteilen der großen Feed-Forward-Schicht in mehrere sogenannte Experten, also kleine, spezialisierte Feed-Forward-Netzwerke.
Jeder dieser Experten verarbeitet nur einen Teil der Daten, nicht jedoch alle. Ein lernbarer Router, auch Gate genannt, entscheidet dynamisch für jeden Input-Token, welche Experten ihn bearbeiten sollen. Dabei werden für jeden Token nur wenige Experten ausgewählt, typischerweise zwei, aus einem Pool von mehreren, zum Beispiel acht. Der Router basiert auf einer linearen Transformation, die für jeden Token Relevanzwerte für jeden Experten berechnet. Anschließend wählt das System die besten Experten aus, führt die Verarbeitung durch und erstellt eine gewichtete Summe der Ergebnisse, wobei die Gewichte durch eine Softmax-Funktion aus den Relevanzscores bestimmt werden.
So entsteht eine hochgradig spezialisierte und zugleich effiziente Verarbeitung, bei der nur ein Bruchteil der insgesamt vorhandenen Parameter aktiv genutzt wird. Dieses Verfahren hat das Potenzial, die Kapazität eines Modells deutlich zu erhöhen, ohne dass die Kosten für die Berechnung proportional wachsen. Während das Modell insgesamt viel mehr Experten und damit mehr Parameter umfasst, wird für jedes einzelne Token nur ein kleiner Teil davon tatsächlich verwendet. Dies führt zu einer erheblichen Reduktion der erforderlichen Rechenleistung pro Input, was gerade bei sehr großen Modellen oder in ressourcenbegrenzten Umgebungen von enormem Vorteil ist. Ein wichtiger Aspekt bei Sparsely-Gated MoE ist die Herausforderung der sogenannten Lastenverteilung auf die Experten.
Ohne geeignete Maßnahmen neigt das Modell dazu, nur einige wenige Experten ständig zu bevorzugen, was zu einer schlechten Ausnutzung der Ressourcen und ineffizientem Training führt. Um dem entgegenzuwirken, werden verschiedene Strategien in das Training eingebaut, wie etwa zufällige Störungen in der Auswahl oder spezielle Verlustfunktionen, die eine gleichmäßigere Verteilung der Daten auf die Experten fördern. Die Implementierung der MoE-Architektur kann technisch anspruchsvoll sein, insbesondere wenn es darum geht, die parallelisierte Verarbeitung auf moderner Hardware wie GPUs effizient umzusetzen. Das sogenannte Shrinking-Batch-Problem beschreibt, dass Experten relativ zu den Batchgrößen viel kleinere Sub-Batches erhalten, was die Effizienz stark beeinträchtigen kann. Forschungsarbeiten wie das MegaBlocks-Projekt beschäftigen sich intensiv damit, diese Herausforderung zu adressieren und dadurch die praktische Nutzbarkeit von MoE-Modellen zu erhöhen.
Für Entwickler und Forschungsteams, die mit reinem Python und Numpy arbeiten, gibt es bereits nachvollziehbare Beispiele für eine MoE-Schicht, die das Prinzip illustrieren. Dabei wird zunächst der Router auf die Eingabedaten angewendet, um die besten Experten für jedes Token zu bestimmen. Anschließend werden die ausgewählten Experten mit den Token bearbeitet, und die Ergebnisse werden entsprechend gewichtet und zusammengeführt. Trotz fehlender vollständiger Vektorisierung verdeutlicht diese Form die Kernmechanismen von MoE und bietet eine Basis zum Verständnis und zur Weiterentwicklung. Sparsely-Gated MoE-Modelle haben sich in der Praxis bereits als äußerst leistungsfähig erwiesen.
Ein prominentes Beispiel ist das Mixtral-Modell, das über acht Experten verfügt und damit eine enorme Gesamtgröße aufweist. Trotzdem wird pro Token nur ein Teil des Modells aktiv genutzt, was eine Balance zwischen hoher Kapazität und praktikabler Laufzeit ermöglicht. Dadurch können Modelle mit komplexerer Repräsentationsfähigkeit trainiert und effizient eingesetzt werden. Die Fähigkeit, ausgewählte Experten pro Token zu aktivieren, ist ein Schritt hin zu modularen und adaptiven neurokognitiven Systemen, die flexibel auf unterschiedliche Aufgabenstellungen reagieren können. In gewisser Weise lässt sich dies metaphorisch mit Spezialisierung in menschlichen Teams vergleichen, bei denen Experten aus verschiedenen Bereichen zu Rate gezogen werden, ohne dass jeder jeden Aspekt bearbeitet.
Neben den technischen Voraussetzungen und Herausforderungen birgt MoE auch konzeptionelle Vorteile. Das Modell lässt Raum, um Experten gezielt auf bestimmte Teilaufgaben oder Eigenschaften zu trainieren – zum Beispiel könnte ein Experte besonders gut bei mathematischen Problemen, ein anderer bei sprachlicher Verarbeitung sein. Während im Verlauf der Tokenverarbeitung im Transformer diese Spezialisierungen oft verschwimmen, eröffnet das MoE-Prinzip neue Dimensionen im Design lernfähiger Systeme. Für die Zukunft der KI-Entwicklung bietet Sparsely-Gated Mixture of Experts somit eine vielversprechende Möglichkeit, Modelle weiter zu skalieren, ohne dabei an Effizienz einzubüßen. Dieser Ansatz erleichtert nicht nur die Erweiterung von Modellkapazitäten, sondern senkt auch die Barrieren für den praktischen Einsatz großer neuronaler Netzwerke in unterschiedlichen Anwendungsfeldern.
Abschließend lässt sich festhalten, dass die Sparsely-Gated MoE-Technologie die Grenzen traditioneller neuronaler Netze erweitert, indem sie smartere, spezialisierte und dennoch ressourcenschonende Netzwerke ermöglicht. Die Innovationen, die mit diesem Konzept einhergehen, sind grundlegend für die Weiterentwicklung von KI-Systemen und werden ihre Anpassungsfähigkeit und Leistungsfähigkeit in den kommenden Jahren maßgeblich prägen.




![Gigapixels of Andromeda [4K] [video]](/images/A8A66816-0EB2-4E62-AAC4-CA808CD36135)

