Die rasante Entwicklung großer Sprachmodelle hat in den letzten Jahren die Künstliche Intelligenz und ihre Anwendungen maßgeblich beeinflusst. Im Zentrum dieses Fortschritts stehen innovative architektonische Konzepte und Trainingsmethoden, die das Potenzial haben, Grenzen neu zu definieren. Die Falcon-H1-Serie stellt hierbei einen bedeutenden Meilenstein dar. Dieses Modellportfolio setzt mit einem hybriden Architekturmix aus klassischer Transformer-Attention und State Space Model (SSM) neue Maßstäbe für Leistung und Effizienz, was es besonders für verschiedene Einsatzszenarien attraktiv macht. Die Falcon-H1-Modelle sind in sechs unterschiedlichen Größen verfügbar, von 0,5 Milliarden bis hin zu 34 Milliarden Parametern.
Jedes Modell ist sowohl in einer Basisvariante als auch in einer auf Instruktionen abgestimmten Version erhältlich, um den spezifischen Anforderungen unterschiedlichster Anwendungen gerecht zu werden. Besonders bemerkenswert ist die Offenheit der Modelle, denn sie stehen unter einer sehr großzügigen Apache-2.0-Lizenz, was Entwicklung, Forschung und kommerzielle Nutzung stark erleichtert. Ein fundamentaler innovativer Kern der Falcon-H1-Serie ist das hybride Architekturdesign. Während klassische Transformer-Modelle allein auf der Attention-Mechanik basieren, kombiniert Falcon-H1 diese mit dem SSM, genauer gesagt dem sogenannten Mamba-2-Ansatz.
Diese Kombination erlaubt es, die Vorteile beider Welten zu nutzen: Die Attention-Komponente sorgt für flexible Kontextbeziehungen und starke Generalisierung bei verschiedener Aufgaben, während das SSM durch seine längerfristige Gedächtnisfähigkeit und geringeren Rechenaufwand bei großen Kontexten überzeugt. Besonders flexibel gestaltet sich die Möglichkeit, das Verhältnis von Attention- zu SSM-Köpfen frei anzupassen. Ein kleiner Anteil Attention ist bereits ausreichend, um beeindruckende Leistungswerte zu erzielen, während das SSM den Hauptanteil der scheinbar schwer berechenbaren Langzeitkontexte übernimmt. Dieses Design führt nicht nur zu einer deutlich schnelleren Inferenzzeit, sondern reduziert auch den Speicherverbrauch erheblich, was insbesondere in ressourcenbegrenzten Umgebungen wie Edge-Computing ein entscheidender Vorteil ist. Falcon-H1 deckt eine beeindruckende Bandbreite an Einsatzgrößen ab, von kleinen Modellen, die mit wenigen hundert Millionen Parametern arbeiten, bis hin zum 34 Milliarden Parameter starken Flaggschiffmodell.
Auffällig ist, dass dabei die kompakteren Modelle hinsichtlich Leistung mit deutlich größeren herkömmlichen Modellen konkurrieren können. So liefert das 0,5 Milliarden Modell Performance auf Augenhöhe mit typischen 7 Milliarden Modelle von 2024. Diese Verdichtung ermöglicht Einsparungen bei Hardwarekosten und Energieverbrauch, ohne dabei signifikante Qualitätseinbußen hinzunehmen. Ein weiteres Highlight ist die native Unterstützung von 18 Sprachen und die Skalierbarkeit auf über 100. Das enthält unter anderem europäische und asiatische Hauptsprachen sowie Sprachen des Nahen Ostens und Südasiens.
Der zugrunde liegende Tokenizer wurde auf vielfältigen multilingualen Daten trainiert und ermöglicht dadurch eine robuste Multilingualität, die sich sowohl bei einfachen als auch komplexeren sprachlichen Herausforderungen bewährt. Ein oft vernachlässigtes, aber zentrales Merkmal der Falcon-H1-Modelle ist ihre Fähigkeit, extrem lange Kontexte zu verarbeiten – bis zu 256.000 Tokens. In der Praxis unterstützt das die Verarbeitung von umfangreichen Dokumenten, mehrstufigen Dialogsystemen oder komplexeren Aufgaben im Bereich Langzeitgedächtnis und Textverständnis. Gerade für Anwendungsfelder wie Recht, Wissenschaft oder technische Dokumentationen eröffnet dies völlig neue Perspektiven, die mit rein transformerbasierten Modellen bisher nur eingeschränkt realisierbar waren.
Die Trainingsstrategie hinter Falcon-H1 setzte ebenfalls auf innovative Methoden. Entgegen vieler anderer Hybrid- und Transformer-Modelle wurde bei Falcon-H1 ein Training mit anspruchsvollen und komplexen Daten von Anfang an gewählt, statt sich einer Curriculum-Learning-Strategie mit einfacher zu schwieriger Progression zu bedienen. Dieser Ansatz ermöglicht dem Modell, komplexe Aufgaben frühzeitig zu erlernen und in der Folge effizienter auf sie zuzugreifen. Zudem erlaubt eine genaue Abschätzung der Memorierungsfähigkeit das gezielte und mehrfach Wiederverwenden hochwertiger Daten, was die Datenqualität im Training deutlich erhöht. Ein technisches Kernstück beim Training ist die Anwendung einer modifizierten Form des Maximalen Update-Parametrisierungskonzepts (μP).
Diese Erweiterung erlaubt es, hyperparametrische Optimierungen, die auf einem Basismodell ermittelt wurden, effizient und performant auf größere Modelle zu übertragen. Die modifizierte μP betrachtet dabei auch die individuelle Trainingsintensität verschiedener Modellparameter, was zu einer fein abgestimmten und gleichmäßigen Lernkurve führt, die besonders für Modelle mit komplizierten architektonischen Komponenten wie SSMs wichtig ist. Im Bereich der Trainingsdynamik wurde zudem großer Wert auf die Stabilisierung gelegt. Spezielle Maßnahmen gegen Trainingsspitzen und übermäßigen Rauschpegel sorgen dafür, dass die Modelle gleichmäßig und sauber trainieren. Die Integration von Gewichtungszerfall und eine angepasste Steuerung der Lernrate zusammen mit einem Batchgrößen-basierten Scaling nach dem neuesten Stand der Theorie unterstützen darüber hinaus ein robustes Training auch bei sehr großen Modellen.
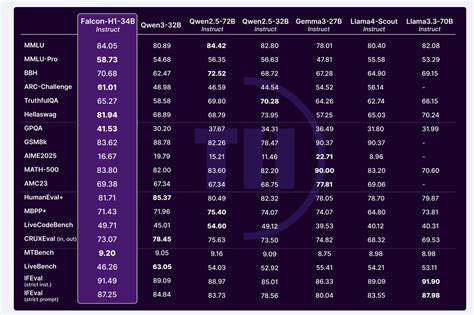
Leistungstechnisch haben Falcon-H1-Modelle schon ohne spezielles Fein-Tuning im Bereich der Schlussfolgerungen und Instruktionserfüllung sehr starke Ergebnisse erzielt. Besonders das instruct-tuned 34 Milliarden Modell konkurriert auf Augenhöhe mit führenden Transformer-Modellen mit ähnlicher oder sogar größerer Größe wie LLaMA 3.3 (70B) oder Qwen-Modelle, auch wenn es keinen expliziten Fokus auf reasoning-spezifisches Fine-Tuning gibt. Auch die kompakten Instruktionsmodelle im Bereich um 1,5 Milliarden Parameter können deutlich größere Wettbewerber schlagen. Beispielsweise liegt das Falcon-H1-1.
5B-Deep-Instruct leistungsmäßig über Qwen3 1,7B und vergleicht sich sogar mit manchen 7 Milliarden Modellen aus dem Jahr 2024. Das macht die Falcon-Reihe zum idealen Kandidaten für Anwendungen, die eine hohe Leistungsfähigkeit bei begrenzten Ressourcen benötigen. Falcon-H1 überzeugt zudem mit soliden Ergebnissen in mehrsprachigen Benchmarks, die eine durchweg hohe Qualität in verschiedenen Sprachfamilien und Regionen belegen. Dies unterstreicht die Robustheit der Multilingualität und die ausgefeilte Datenauswahl beim Training. Neben Klassikern wie Deutsch, Englisch, Spanisch und Französisch sind auch Sprachen wie Arabisch, Hindi, Koreanisch oder Urdu maßgeblich vertreten.
Auf dem Gebiet der Langzeitkontextverarbeitung hebt sich Falcon-H1 noch deutlicher ab. In vergleichenden Tests über lange Texte und komplexe Aufgabenpakete erzielte es im direkten Vergleich mit Spitzenmodellen wie Qwen2.5-72B teilweise vier- bis achtfach höhere Effizienz beim Handling langer Eingaben. Dies ist ein entscheidender Vorteil für Anwendungen in der Wissensarbeit, im wissenschaftlichen Bereich oder bei der Verarbeitung großer Textmengen. Neben der herausragenden Performance beeindruckt Falcon-H1 auch durch seine Effizienz.
Die Technologie ermöglicht eine schnellere Eingabe- und Ausgabeverarbeitung, gerade bei längeren Kontexten, mit deutlich reduziertem Energie- und Speicherverbrauch. Dies wird durch das innovative vLLM-Implementierungskonzept noch einmal maßgeblich unterstützt. Zwar sind attention-basierte Transformer bei kleinen Kontexten noch minimal schneller, doch im realen Einsatz, bei dem meist längere Kontextfenster benötigt werden, spielt Falcon-H1 seine Stärken voll aus. Die offene Verfügbarkeit unter einer liberalen Lizenz sorgt dafür, dass Forscher, Entwickler und Unternehmen die Falcon-H1-Serie frei für vielfältige Anwendungen nutzen können, ohne auf herkömmliche Lizenzierungsbarrieren zu stoßen. Das fördert eine lebendige Community und kontinuierliche Weiterentwicklung, was das Modellportfolio langfristig für verschiedenste Einsatzgebiete sehr attraktiv macht.
Insgesamt stellt Falcon-H1 eine bahnbrechende Entwicklung im Bereich großer Sprachmodelle dar. Der hybride Ansatz, gepaart mit innovativen Trainingsmethoden, führt zu einer neuen Klasse von Modellen, die sowohl in Effizienz als auch in Leistung neue Horizonte erschließen. Vom Edge-Device bis zum großskaligen Cloud-Einsatz bietet Falcon-H1 eine breit skalierbare Lösung, die dank seiner Langzeitkontextfähigkeit, Multilingualität und starken Fundamentalleistungen ideal für zukunftsträchtige KI-Anwendungen geeignet ist. Die Falcon-H1-Reihe vereint modernste Forschung mit praktischen Anforderungen und steht damit exemplarisch für die nächste Generation intelligenter Sprachsysteme.