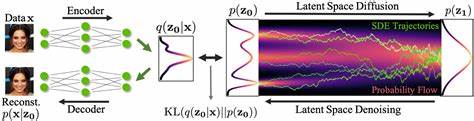
Das generative Modelling hat in den letzten Jahren enorme Fortschritte gemacht und stellt die Basis vieler moderner Anwendungen im Bereich Künstliche Intelligenz dar. Besonders bemerkenswert ist die Entwicklung und zunehmende Verbreitung von generativen Modellen, die nicht direkt mit Rohdaten wie Pixeln oder Audiosamples arbeiten, sondern stattdessen auf sogenannten latenten Repräsentationen basieren. Diese kompakten, höherstufigen Darstellungen abstrahieren die wesentlichen, für den Menschen wahrnehmbaren Informationen und erlauben so effektives und ressourcenschonendes Generieren von Inhalten. Dieser Ansatz wird als Generatives Modelling im Latent Space bezeichnet und ist ein wesentlicher Schritt in der evolutionären Entwicklung KI-gestützter Medienerzeugung. Latente Repräsentationen sind keine zufälligen oder physikalisch messbaren Größen, sondern vielmehr deterministische, nichtlineare Abbildungen der Eingangssignale.
Sie erfassen relevante Merkmale auf eine verdichtete Art und Weise, welche sich besonders gut für die Modellierung eignet. Statt oberflächliche Details oder irrelevantes Rauschen im Originalsignal abzubilden, konzentrieren sie sich auf den für die menschliche Wahrnehmung wichtigen Anteil der Daten. Dies sorgt für eine besonders effiziente Nutzung der Modellkapazitäten und erlaubt es, selbst mit vergleichsweise kleineren und schnelleren Netzwerken beeindruckende Resultate zu erzielen. Die Trainingsmethode, die sich heute etabliert hat, teilt sich in zwei klar voneinander getrennte Phasen auf. In der ersten Phase wird ein Autoencoder trainiert – ein neuronales Netzwerk, das aus einem Encoder und einem Decoder besteht.
Der Encoder komprimiert das Eingangssignal zu einer latenten Darstellung, der Decoder hingegen rekonstruiert aus den latenten Codes das ursprüngliche Signal so originalgetreu wie möglich. Wichtige Komponenten wie der Rekonstruktionsverlust, der Wahrnehmungsverlust und der adversariale Verlust sorgen dabei dafür, dass die Rekonstruktion sowohl quantitativ als auch qualitativ hochwertig bleibt. Erst in der zweiten Phase wird ein eigenständiges generatives Modell auf die zuvor extrahierten latenten Repräsentationen trainiert. Diese latenten Vektoren bilden für das generative Modell die neue Eingabe, wodurch es sich komplett auf diese abstrahierte Form der Daten konzentrieren kann. Moderne Verfahren nutzen hierfür autoregressive Modelle oder Diffusionsmodelle.
In dieser Phase bleiben die Encoder-Parameter unverändert und die Decoder werden nur bei der Generierung neuer Daten benötigt, um die latenten Repräsentationen wieder in die Signaldomäne zurückzuführen. Historisch gesehen sind Generative Modelle zunächst direkt auf Rohdaten wie Pixeln im Bild oder Samples im Audio angewendet worden. Modelle wie PixelRNN oder WaveNet generierten die Daten Schritt für Schritt auf der ursprünglichen Ebene. Diese direkte Arbeitsweise führte jedoch schnell an Skalierungsgrenzen, da das Modell gezwungen war, auch das für die menschliche Wahrnehmung irrelevante Rauschen zu modellieren. Es stellte sich heraus, dass etwaiger Informationsgehalt, der keinen Einfluss auf die Wahrnehmung hat, Ressourcen verschwendet und die Modellqualität sowie Effizienz beeinträchtigt.
Mit der Einführung von VQ-VAE, einem Modell zur diskreten latenten Repräsentation von Bildern, veränderte sich dieser Umstand grundlegend. VQ-VAE reduzierte die räumliche Auflösung deutlich und quantisierte die latenten Codes, wodurch das Modell effizienter auf einer kompakteren und besser modellierbaren Datenbasis arbeiten konnte. Erstmalig ließen sich so realistische, hochauflösende Bilder generieren, die zuvor nur mit generativen adversarialen Netzwerken (GANs) erreicht wurden. Die diskrete Kodierung war hierbei entscheidend, da autoregressive Modelle mit diskreten Eingabedaten deutlich besser umgehen konnten. Im Anschluss an VQ-VAE erweiterten innovative Modelle wie VQGAN dieses Konzept, indem sie durch adversariale Lernmechanismen die Bildqualität weiter steigerte und die Komprimierungsrate auch bei stark reduzierter Auflösung erhielten.
VQGAN gilt heute als eine der Schlüsselerfindungen, die die schnelle Entwicklung moderner generativer Modelle befeuert haben. Es ermöglichte die Erzeugung qualitativ hochwertiger Bilder bei deutlich reduziertem Rechenaufwand und Ressourcenverbrauch. Parallel entwickelte sich das Konzept der latenten Diffusionsmodelle weiter, welche die Vorteile latenter Repräsentationen mit der Stabilität und Ausdrucksstärke von Diffusionsverfahren verbanden. Diffusionsmodelle zeichnen sich durch ihren iterativen Verfeinerungsprozess aus, bei dem das Modell schrittweise verrauschte Versionen der Daten bereinigt. Im latent Space arbeiten sie auf kompakten Repräsentationen, was erheblich schneller und ressourcenschonender ist als auf Rohdaten.
Der Mehrstufigkeitsansatz bietet nicht nur verbesserte Effizienz, sondern ermöglicht auch eine differenzierte Behandlung der verschiedenen Signalanteile. Gerade in visuellen Daten spielt die Unterscheidung von Struktur und Textur eine wichtige Rolle. Die latente Repräsentation zielt darauf ab, strukturelle Informationen – die für das Verständnis des Bildes entscheidend sind – zu bewahren, während sie bei Texturdetails eher abstrahiert. Dies erlaubt dem generativen Modell, weniger redundante Informationen zu lernen und somit anspruchsvollere Bilder auf geringerer Datenbasis zu erzeugen. Der Weg vom klassischen Autoencoder zum heutigen Einsatz von latenten Repräsentationen ist geprägt von einem sorgfältigen Abwägen zwischen Rekonstruktionsqualität und Modellierbarkeit.
Das Ziel besteht darin, eine latente Repräsentation zu lernen, die einerseits das Ausgangssignal möglichst genau abbildet, andererseits aber einfach genug gestaltet ist, um von einem generativen Modell effizient und gut erlernbar zu sein. Die Kapazität der latenten Repräsentationen wird dabei durch Parameter wie die räumliche Auflösung des latenten Gitters und die Anzahl der Kanäle geregelt. Ein höherer Reduktionsfaktor verringert den Speicher- und Rechenaufwand, benötigt aber oft höhere Ausdruckskraft und kann gleichzeitig den Verlust wichtiger Details verursachen. Eine zu hohe Kapazität dagegen erschwert dem generativen Modell das Lernen. Dieses Wechselspiel muss pragmatisch und empirisch ausgeglichen werden.
Darüber hinaus spielen Verluste wie der KL-Divergenzterm bei variationalen Autoencodern eine regulierende Rolle. Allerdings ist ihr Einfluss in modernen Latent Space Modellen oft deutlich abgeschwächt, da ein zu starker Regularisierungsterm die encoderbedingte Information zu sehr einschränkt und die Rekonstruktionsqualität verschlechtert. Stattdessen werden heute meist Kombinationen aus Regressions-, perceptual- und adversarialen Verlusten genutzt, um die latente Repräsentation sinnvoll zu strukturieren, realistische Details einzufangen und gleichzeitig die Modellierbarkeit aufrechtzuerhalten. Ein weiterer zentraler Aspekt ist die Erhaltung der zugrundeliegenden Topologie und Struktur im Latent Space. Perzeptuelle Signale wie Bilder und Ton sind naturgemäß in regelmäßigen Gittern organisiert.
Diese Struktur vereinfacht die Anwendung leistungsstarker neuronaler Netzwerke, die auf Translationseigenschaften und stationäre Prozesse ausgelegt sind. Andererseits führt die strikte Beibehaltung des Gitters manchmal zu Ineffizienzen, denn nicht alle Regionen des Signals enthalten gleich viele relevante Informationen. Dieses sogenannte "Tyrannei des Gitters" Problem wird aktuell durch verschiedenartige adaptive oder hierarchische Repräsentationen adressiert, die je nach Kontext unterschiedliche Auflösungen oder sogar unstrukturierte Tokenisierungen erlauben, um so Daten gezielter komprimieren zu können. Obwohl im Bereich visueller Daten dieser Workflow weitgehend erprobt und optimiert ist, weisen andere Domänen wie Video und Audio noch komplexe Herausforderungen auf. Beispielsweise müssen temporale Redundanzen in Videos systematisch berücksichtigt werden, um flimmerfreie und konsistente Repräsentationen zu erzeugen.
In der Audioverarbeitung werden oft andere Prinzipien und rekurrente Netzwerke zur latenten Modellierung eingesetzt. Zudem unterscheiden sich die geeigneten Wahrnehmungsverluste und Discriminatorarchitekturen erheblich. Eine oft gestellte Frage ist, ob das zweistufige Training langfristig gegenüber vollständig end-to-end trainierten Modellen bestehen wird. Obwohl das gemeinschaftliche Lernen aller Komponenten technisch reizvoll ist und prinzipiell enger optimierte Systeme ermöglichen würde, spricht die signifikante Effizienzsteigerung, die die latente Modellierung heute bietet, klar für den zweistufigen Ansatz. Komplettes End-to-End-Training ist derzeit vor allem bei sehr kleinen bis mittleren Modellen anzutreffen, während hochqualitative großskalige Systeme weiterhin auf die Trennung in latente Repräsentation und separate Generierung setzen.
Zusammenfassend lässt sich feststellen, dass Generatives Modelling im Latent Space eine Schlüsselrolle bei der aktuellen und zukünftigen Entwicklung intelligenter, ressourceneffektiver Medienerzeugungssysteme spielt. Es kombiniert moderne neuronale Architekturprinzipien mit fundiertem Wissen über Wahrnehmung und Signalstruktur, um den Spagat zwischen Qualität und Effizienz zu meistern. Die kontinuierliche Optimierung von latenten Repräsentationen, Verlustfunktionen und Trainingsstrategien wird diesen Bereich noch weiter ausbauen und zu kreativ neuen Anwendungen in Bild-, Video-, Audio- und sogar Sprachverarbeitung führen. Für Forscher, Entwickler und Anwender bleibt das Verständnis dieser Prinzipien essenziell, um die Potenziale moderner KI-basierter Generierung voll auszuschöpfen.