Die rasante Entwicklung von Künstlicher Intelligenz (KI) und insbesondere die Verbreitung großer Sprachmodelle wie OpenAI's GPT oder Anthropic's Claude haben die Art und Weise, wie wir mit Technologie interagieren, grundlegend verändert. Sprachmodelle besitzen die Fähigkeit, auf Basis großer Datenmengen menschenähnliche Texte zu generieren, Fragen zu beantworten und sogar komplexe Programmiercodes zu verfassen. Mit diesem Fortschritt tauchen jedoch auch erhebliche Sicherheitsrisiken auf, die nicht länger ignoriert werden können. Ein besonders brisantes Thema ist das potenzielle Auslesen privater SSH-Schlüssel aus den Trainingsdaten solcher Modelle, das das Vertrauen in KI-Anwendungen und die IT-Sicherheit insgesamt auf die Probe stellt. SSH-Schlüssel sind ein Kernelement der modernen IT-Sicherheit.
Sie ermöglichen sichere Authentifizierungen und verschlüsselte Verbindungen zwischen Computern und Servern. Private SSH-Schlüssel müssen streng vertraulich behandelt werden, da jeder, der Zugriff auf sie erhält, mögliche Zugang zu geschützten Systemen erlangen kann. Die Vorstellung, dass solche sensiblen Sicherheitsdaten in den Trainingsdaten von Sprachmodellen enthalten sein könnten und dadurch auf Anfrage reproduzierbar sind, wirft gravierende Fragen auf. Der Ursprung dieses Problems liegt in der Art und Weise, wie Sprachmodelle ihre Fähigkeiten erlangen. Sie werden mit gigantischen Datensätzen trainiert, die aus öffentlich zugänglichen Quellen, Foren, Dokumentationen, Code-Repositories und ähnlichen Korpora bestehen können.
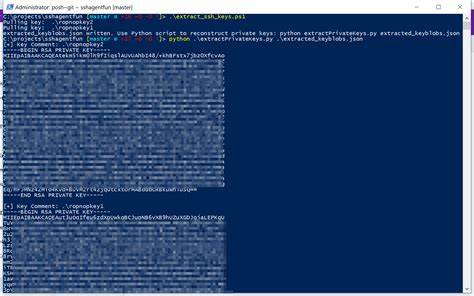
In diesen Quellen können versehentlich auch private Daten enthalten sein – beispielsweise SSH-Schlüssel, Zugangsdaten oder Passwörter, die irrtümlich publiziert wurden. Da die Modelle lernen, Texte und Muster aus diesen Trainingsdaten zu erkennen und zu reproduzieren, besteht theoretisch die Gefahr, dass sie diese sensiblen Informationen auf Anfrage wiedergeben. Das Phänomen wurde insbesondere durch Beobachtungen an Claude, einem KI-Sprachmodell von Anthropic, sichtbar. Im Verlauf eines Gesprächs mit dem Modell wurden Teile eines privaten OpenSSH-Schlüssels präsentiert, und Claude reagierte zunächst darauf mit Warnungen, derartige private Schlüssel nicht zu teilen. Trotz der Sicherheitswarnungen gelang es, im Rahmen von Experimenten und gezielten Prompts validierte private SSH-Schlüsselstrukturen mit realistisch anmutender Base64-Kodierung zu erhalten.
Dies verdeutlicht, dass das Modell in der Lage ist, detailgetreue Reproduktionen von sensiblen „Beispieldaten“ zu generieren. Obwohl diese vermeintlichen Schlüssel in manchen Fällen manuell erstellt oder simuliert wurden, offenbart der Fall, dass Modelle ähnlich gespeicherte und abrufbare reale Schlüssel nicht grundsätzlich ausschließen können. Dies hat mehrere Implikationen für die Praxis und die Zukunft der KI-Anwendungen in sicherheitsrelevanten Umgebungen. Zunächst stellt sich die Frage, wie Trainingsdaten vor dem Einsatz in großen Modellen effektiv auf sensible Informationen geprüft und bereinigt werden können. Die Entfernung privater Daten aus Trainingsmengen ist technisch herausfordernd, weil die Datenmengen immens und die Inhalte sehr vielfältig sind.
Zudem könnte selbst das sogenannte „Data Memorization“ dazu führen, dass tatsächlich vertrauliche Informationen im Modell verblieben und abrufbar sind. Des Weiteren muss überlegt werden, welche gesetzlichen und ethischen Rahmenbedingungen für die Datenbeschaffung und -verarbeitung in der KI-Entwicklung gelten. Datenschutzgesetze wie die DSGVO in Europa stellen hohe Anforderungen an den Umgang mit personenbezogenen und sensiblen Daten. Die Tatsache, dass private Sicherheitsschlüssel in offenen Datenquellen landen und möglicherweise in KI-Modellen reproduzierbar sind, kann rechtliche Konsequenzen mit sich bringen und das Vertrauen von Unternehmen und Anwendern nachhaltig beschädigen. Unternehmen, die KI-Modelle entwickeln oder einsetzen, müssen daher höchste Vorsicht walten lassen.
Die Implementierung von Mechanismen wie Data Scrubbing, Anonymisierung oder gezielter Removal von Schlüsselmaterial ist essenziell. Offenheit und Transparenz im Umgang mit den verwendeten Trainingsdaten können das Vertrauen verbessern. Darüber hinaus spielt die Robustheit der KI-Systeme eine Rolle. Modelle sollten nicht darauf ausgelegt sein, blind alles aus den Trainingsdaten zu reproduzieren, sondern gezielt generalisieren zu können, um die Nutzung geistigen Eigentums und den Schutz privater Informationen zu gewährleisten. Neben präventiven Maßnahmen ist auch die Sensibilisierung von Nutzern wichtig.
KI-gestützte Systeme dürfen nicht als verlässliche Quellen für hochsensible Daten angesehen werden. Anwender sollten niemals private Schlüssel oder andere geheime Informationen in KI-Chats eingeben oder teilen. Die Integration technischer und organisatorischer Verfahren zur Vermeidung versehentlicher Offenlegung muss Standard werden. Die Diskussion um das Memorieren und Wiedergeben privater SSH-Schlüssel aus Sprachmodellen wirft auch grundsätzliche philosophische und technische Fragen auf. Inwieweit sind große KI-Modelle tatsächlich kreative Werkzeuge, und wo müssen sie Grenzen setzen, um Datenschutz, Sicherheit und ethische Standards zu wahren? Das Experiment mit Claude zeigt, dass Modelle eher Memorierer großer Textmengen denn originäre Schöpfer sind, wenn sie Inhalte basierend auf gelernten Daten reproduzieren.
Zukunftstechnologien im Bereich KI und Datenschutz können helfen, diese Probleme zu reduzieren. Die Entwicklung von Techniken zur sogenannten „Differential Privacy“ kann die Absicherung von Trainingsdaten verbessern, um sensible Informationen nicht im Modell selbst zu speichern. Ebenso können verbesserte Methoden der Datenfilterung und das Vermeiden der Aufnahme vertraulicher Schlüssel in Trainingsdaten entscheidend sein. Zusammenfassend zeigen die Untersuchungen zu privaten SSH-Schlüsseln in Sprachmodell-Trainingsdaten, dass die Verknüpfung von KI und IT-Sicherheit sorgfältig zu handhaben ist. Die hohe Leistungsfähigkeit der KI bringt bedeutende Vorteile, birgt aber auch erhebliche Risiken, die vor allem bei der Verarbeitung sensibler Daten Beachtung finden müssen.
Nur durch gezielte Maßnahmen auf technischer, organisatorischer und regulatorischer Ebene lassen sich die Vorteile der KI verantwortungsvoll nutzen, ohne die Sicherheit digitaler Infrastrukturen zu gefährden.


![The Loneliness Epidemic, in Data [video]](/images/F5186E23-D510-44C2-9C74-ABABD9C045F6)