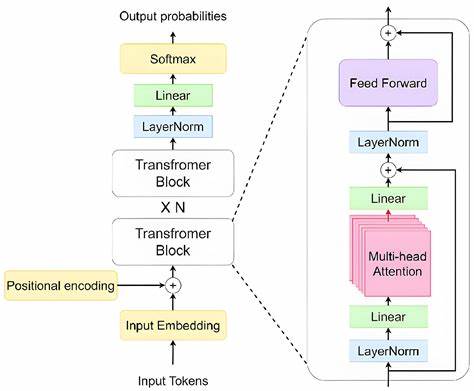
In der Welt der Künstlichen Intelligenz und insbesondere der Verarbeitung natürlicher Sprache (NLP) sind Transformer-Modelle seit Jahren eine zentrale Säule. In der Anfangsphase dominierten Encoder-Decoder-Kombinationen sowie reine Encoder-Architekturen wie BERT den Markt. Doch die Technologie entwickelt sich rasend schnell weiter, und derzeit steht ein Paradigmenwechsel bevor, der die Art und Weise, wie wir Embeddings erzeugen und nutzen, grundlegend verändert. Decoder-Only Transformer, die ursprünglich für Textgenerierung entwickelt wurden, können heute mit dem richtigen Fine-Tuning ebenso exzellente Encoder werden – und das auf einem Leistungsniveau, das traditionelle Encoder-Modelle abhängt. Diese Entwicklung ist maßgeblich, da sie sowohl die Effizienz steigert als auch die Abhängigkeit von proprietären Lösungen reduziert.
Decoder-Only Transformer sind speziell auf die Generierung von Textsequenzen ausgelegt. Modelle wie LLaMA, Mistral oder Qwen repräsentieren diese Architekturform und überzeugen durch ihre enorme Skalierbarkeit und Flexibilität. Anders als bei klassischen Encodern, die sequentiell kontextualisierte Repräsentationen erzeugen, fokussieren sich Decoder-Modelle auf autoregressives Lernen, also die Vorhersage des nächsten Tokens anhand zuvor gelesener Tokens. Diese Eigenart führte lange Zeit zur Annahme, dass Decoder-Only Modelle für Aufgaben wie semantische Suche oder Retrieval von Informationen weniger geeignet sind. Doch neueste Forschungen und Entwicklungen widerlegen diese Annahme eindrucksvoll.
Der Schlüssel zum Erfolg liegt in der gezielten Feinjustierung der Decoder-Only Modelle. Durch ein duales Training, bei dem sowohl ein generatives als auch ein embeddingsspezifisches Ziel verfolgt werden, lässt sich der Transformer so anpassen, dass er nicht nur hochwertigen Text generiert, sondern auch exzellente, semantisch aussagekräftige Vektorrepräsentationen liefert. Dieses Fine-Tuning kombiniert typischerweise den traditionellen Next-Token-Prediction-Ansatz mit einem kontrastiven Lernziel, etwa der InfoNCE-Verlustfunktion, welche die semantische Ähnlichkeit zwischen Texten in einem Vektorraum maximiert. Diese Methode hat mehrere Vorteile. Zum einen entfallen separate Modelle für Generierung und Embedding, was Hardware-Ressourcen spart und die Infrastruktur vereinfacht.
Unternehmen, die bereits große generative Sprachmodelle betreiben, können diese Modelle mit minimalem Mehraufwand gleichzeitig für semantische Suche und Retrieval-Aufgaben nutzen. Zudem senkt dies die Einstiegshürden für kleinere Forschungsteams und Unternehmen, die keine eigenen Encoder-Modelle trainieren oder auf teure API-Dienste zurückgreifen wollen. In der Praxis bedeuten diese Fortschritte, dass viele traditionelle Encoder-Modelle wie SBERT und seine Varianten an Bedeutung verlieren. Neuere Modelle, die auf Decoder-Only Architekturen basieren, erreichen auf etablierten Benchmarks wie dem Massive Text Embedding Benchmark (MTEB) hervorragende Ergebnisse. Modelle wie Seed-1.
5-Embedding oder die von ByteDance entwickelte Version demonstrieren eindrucksvoll, wie stark die Leistung dieser neuen Encodermodelle ist, teilweise mit mehr als doppelt so hohen Scores in Retrieval-Aufgaben verglichen mit älteren Architekturen. Ein weiterer interessanter Aspekt dieser Entwicklung ist die potenzielle Unterstützung multimodaler Daten. Während klassische Encodermodelle oft auf einzelne Datenquellen wie Text oder Bilder beschränkt bleiben, können gut trainierte Decoder-Only Modelle dank spezialisierter Instruktionen und Cross-Modality-Training verschiedene Modalitäten innerhalb eines integrierten Vektorraums repräsentieren. Dies eröffnet neue Möglichkeiten, etwa in der Suche mittels Bild- und Textkombinationen, bei denen sowohl visuelle als auch sprachliche Informationen effizient verarbeitet und abgeglichen werden können – ein Anwendungsfeld, in dem zuvor hauptsächlich spezialisierte Modelle wie CLIP dominierten. Natürlich gibt es auch Herausforderungen.
Die oft großen Modellgrößen von Decoder-Only Transformers steigern die Rechenkosten im Vergleich zu kompakten Encodern. Doch durch Techniken wie LoRA (Low-Rank Adaption) und QLoRA können Feinjustierungen auf ressourcenschonende Weise durchgeführt werden, ohne dass die Qualität leidet. Dies erlaubt sogar den Einsatz von kleineren LLMs unter einer Milliarde Parameter, die auf mobilen oder edge-nahen Geräten läuferfähig sind und dennoch hohe qualitative Leistungen erbringen. Das Fine-Tuning selbst erfordert präzises Design: Modelle müssen lernen, eine spezielle Token-Sequenz zu erkennen, die den Wechsel vom generativen Modus in den Embedding-Modus signalisiert. Darüber hinaus können modale Unterschiede über Instruktionen gesteuert werden, sodass Text, Bilder, Audio oder Video jeweils an die gleiche semantische Repräsentation gebunden werden.
Zudem lässt sich die Modellarchitektur teilweise anpassen – etwa durch die Nutzung bidirektionaler Aufmerksamkeit beim Embedding-Modus, was den Informationsfluss verbessert und somit meist aussagekräftigere Vektoren erzeugt als das rein autoregressive Standardverfahren. Die Kombination von generativen und embedder-orientierten Trainingszielen stellt zudem sicher, dass die Generierungsqualität nicht leidet, während gleichzeitig die embedding-spezifische Kennzahl optimiert wird. GRIT, ein prominentes Beispiel für diese Herangehensweise, belegt, dass es möglich ist, beide Welten zu vereinen, ohne Kompromisse einzugehen – ein entscheidender Schritt für den praktischen Einsatz. Für Entwickler und Unternehmen, die sich mit Suchmaschinen, Chatbots oder Retrieval-Augmented Generation (RAG) beschäftigen, bieten diese Entwicklungen eine neue strategische Option, die sowohl Performance als auch Kosten optimiert. So lässt sich ein generatives LLM für semantisch hochwertige Embeddings erweitern, was in einer Vielzahl von Anwendungsszenarien von Vorteil ist – sei es die präzisere Beantwortung von Nutzeranfragen, bessere Content-Clusterung oder die Verbesserung empfohlener Inhalte.
Darüber hinaus sind die Möglichkeiten in sprachübergreifenden und multilingualen Settings bedeutend. Die aktuellen State-of-the-Art Decoder-Only Encodermodelle zeigen durchgehend starke Leistungen in Multi-Language-Benchmarks, oft besser als frühere Encoder-Modelle. Dies beruht auf der umfassenden Sprachbasis in den Trainingsdaten großer LLMs und deren Fähigkeit, Sprachstrukturen abseits des Englischen zu verarbeiten und in einen gemeinsamen semantischen Raum einzubetten. Fazit ist, dass Decoder-Only Transformer mittlerweile als vollwertige Encoder etabliert sind, die dank innovativem Fine-Tuning sowohl im Bereich Embeddings als auch Textgenerierung glänzen können. Sie bieten die Möglichkeit, proprietäre, oft geschlossene Systeme zu umgehen und mit offenen Modellen zu innovieren, die flexibel an individuelle Anforderungen angepasst werden können.
Die Zukunft der Embedding-Technologie scheint daher in einer Symbiose aus generativen und embeddingsorientierten Trainingsstrategien zu liegen, wodurch ein einzelnes Modell mehrere Aufgaben effizienter und leistungsfähiger bewältigen kann. Für Forscher und Anwender eröffnen sich damit neue Horizonte, die zeigen, dass technologische Grenzen aus traditionellen Kategorien überwunden werden können – ein Meilenstein für die AI-Community und die praktische Nutzung großer Sprachmodelle.





![Framer: Spring Event 2025 [video]](/images/F7BBD676-8609-457C-BDA3-4AC147F94416)