In einer Ära, in der das Internet zunehmend von einer Handvoll großer Cloud-Anbieter dominiert wird, sind Ausfälle bei diesen Diensten für viele Unternehmen potentiell katastrophal. Kürzlich erlebten Google und Cloudflare gleichzeitige, mehrstündige Ausfälle, die weltweit zahlreiche Online-Dienste, darunter reCAPTCHA und Turnstile, beeinträchtigten. Während viele Anbieter mit massiven Ausfällen kämpften, blieb hCaptcha unbeeinträchtigt online. Diese bemerkenswerte Betriebskontinuität bei gleichzeitigem Ausfall zweier technologischer Giganten wirft die Frage auf: Wie gelang es hCaptcha, diese Herausforderung zu meistern? Ein Blick hinter die Kulissen offenbart eine durchdachte Architektur, eigene Kontrollmechanismen und jahrelange Erfahrung in der Gestaltung hochverfügbarer Websysteme.Die Dynamik moderner Cloud-Infrastrukturen und die daraus resultierende Abhängigkeit sind komplexer als je zuvor.
Cloudflare gab offen zu, dass die Verfügbarkeit ihres Kerndatenspeichers stark von Googles Diensten abhängig sei. Ein Ausfall bei Google führte daher unmittelbar zu einem globalen Ausfall bei Cloudflare, was die Mehrzahl ihrer Dienste unerreichbar machte. Diese Kettenreaktion ist ein anschauliches Beispiel für die geringe Resilienz durch Konzentration und Single Points of Failure in der heutigen Internetinfrastruktur. Ursprünglich als dezentralisiertes Netzwerk konzipiert, hat sich das Internet zu einem Ökosystem entwickelt, das von wenigen dominanten Cloud-Dienstleistern abhängig ist. Für Unternehmen, die tagtäglich auf diese Dienste angewiesen sind, bedeutet dies erhöhte Risiken für Verfügbarkeitsprobleme.
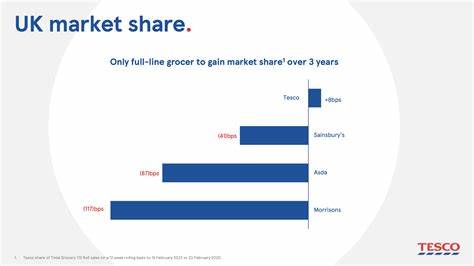
hCaptcha hingegen hat von Anfang an auf eine Architektur gesetzt, die unabhängig von einzelnen Cloud-Giganten funktioniert und gehört mit einer Verfügbarkeit von über 99,99 % zu den zuverlässigsten Anbietern in der Branche.Eine der fundamentalen Strategien hinter hCaptchas Stabilität ist die Nutzung mehrerer redundanter Systeme. Statt sich auf einen einzigen Cloud-Anbieter oder eine einzige Technologie zu verlassen, bewahrt hCaptcha die Unabhängigkeit durch Verteilung essenzieller Dienste. Dabei wird besonders Wert auf eine detaillierte Analyse und Automatisierung möglicher Ausfallszenarien gelegt. Es ist wichtig zu verstehen, dass bereits die Auswahl von Cloud-Diensten und -Features eines Anbieters eine differenzierte Prüfung verlangt.
Zwar nutzt hCaptcha Cloudflare als Content Delivery Network (CDN), bewertet jedoch differenziert, welche Cloudflare-Produkte tatsächlich in der Produktion zum Einsatz kommen. Insbesondere wurde die Zuverlässigkeit von Cloudflares Workers KV, einem verteilten Key-Value-Store, kritisch hinterfragt und daraufhin nicht implementiert. Diese selektive Nutzung gibt hCaptcha die Flexibilität, bei Problemen schnell und automatisiert zu reagieren, ohne die gesamte Infrastruktur umzubauen oder den Cloud-Anbieter komplett zu meiden.Von besonderer Bedeutung für die hohe Ausfallsicherheit ist die kontinuierliche Überwachung der Cloud-Dienste aus innen- und außenperspektiven. Oft werden Störungen, sogenannte Brownouts oder regionale Ausfälle, nicht zeitnah auf den offiziellen Statusseiten der Anbieter veröffentlicht oder sogar ganz verschwiegen.
hCaptcha betreibt eigene umfangreiche Beobachtungssysteme, welche sowohl öffentliche Statusinformationen als auch eigene verteilte Tests miteinander verbinden, um ein aktuelles und präzises Bild der Dienstqualität zu erhalten. Dieses eigene Monitoring erlaubt eine realistische Einschätzung der Verlässlichkeit einzelner Cloud-Features und ermöglicht es, bei etwaigen Problemen frühzeitig die entsprechenden Notfallmaßnahmen einzuleiten.Das Notfallmanagement bei hCaptcha sieht vor, dass alle Systemkomponenten in der Lage sind, entweder automatisch oder zumindest per erprobtem Runbook zwischen verschiedenen Anbietern und Features zu wechseln. Im Falle eines Ausfalls wird idealerweise automatisch auf eine alternative Infrastruktur oder einen anderen Cloud-Anbieter umgeschaltet, ohne dass dabei Nutzer Einschränkungen spüren. Im Gegensatz zu vielen anderen großen Cloud-Anbietern neigt Google dazu, ganze Dienste oder Regionen allumfassend auszuschalten, während andere Anbieter differenzierter agieren.
Deshalb setzt hCaptcha auf eine Failover-Strategie, die zuerst innerhalb desselben Providers alternative Pfade nutzt, bevor sie bei Bedarf komplett auf andere Anbieter ausweicht. Dabei werden auch zahlreiche Szenarien berücksichtigt, in denen der plötzliche Umstieg im großen Maßstab zu Problemen führen könnte. Durch das abgestufte und kontrollierte Vorgehen bei der Umschaltung schützt hCaptcha die Stabilität ihrer Services auch bei plötzlichen Störfällen.Eine moderne Infrastruktur lebt zudem von aktiven Multi-Cloud Strategien, bei denen unterschiedliche Cloud-Anbieter gleichzeitig im produktiven Einsatz sind. Dieses sogenannte active-active Setting stellt sicher, dass bei plötzlichen Lastverlagerungen oder Ausfällen einzelne Systeme sofort die gesamte Last ohne Qualitätseinbußen übernehmen können.
Durch laufende Tests und Lastverschiebungen unter realen Bedingungen baut hCaptcha Vertrauen in die Leistungsfähigkeit und Stabilität aller beteiligten Komponenten auf. So wird sichergestellt, dass ein Failover nicht nur theoretisch möglich ist, sondern praxisnah funktioniert.Ein häufig unterschätztes Risiko besteht in versteckten Abhängigkeiten innerhalb der Infrastruktur. So erwischte der Google-Ausfall auch Unternehmen, die eigentlich keine Google Cloud-Dienste nutzten, allein weil sie etwa das Google Container Registry für das Laden von Container-Images ohne eigene Caches einsetzten. Diese Art von indirekten kritischen Abhängigkeiten führte dazu, dass Anwendungen beim Hochfahren nicht reibungslos skalierten und sogar komplett nicht mehr erreichbar waren.
hCaptcha legt daher großen Wert darauf, alle externen Abhängigkeiten als solche zu erkennen, sie konsequent zu dokumentieren und nach Möglichkeit lokal zu cachen. Insbesondere werden Build-, Deploy- und Scale-Up-Pfade isoliert betrachtet und von externen Risiken weitgehend abgeschirmt.Die Herausforderung einer stabilen und verfügbaren Infrastruktur wird verschärft durch wirtschaftliche und technische Rahmenbedingungen. Die Konzentration im Cloud-Markt ist stark – ein Ergebnis eines Hybrids aus kommerziellen Vorteilen und netzwerkbedingter Kommensalität. Große Anbieter profitieren unter anderem von unentgeltlichen Netzwerkanbindungen untereinander und dadurch niedrigeren Kosten, während neue Marktteilnehmer mit unter Umständen deutlich höheren Kosten für Backbone-Transit zu kämpfen haben.
Unternehmensgrößen wie Cloudflare und Google haben zudem den Vorteil, dass ihre Dienste flächendeckend in zahlreichen Rechenzentren verfügbar sind und dort optimal miteinander verknüpft sind. Für kleinere oder neuere Anbieter sind derartige Infrastrukturinvestitionen kaum zu stemmen. Dieses Ungleichgewicht ist schwer aufzulösen und wird auch durch regulatorische Maßnahmen nur langsam adressiert. Daraus ergibt sich, dass Anbieter wie hCaptcha besonders sorgfältig planen und ihre Infrastruktur so gestalten müssen, dass sie weniger von den dominierenden Clouddiensten abhängt, gerade um im Krisenfall handlungsfähig zu bleiben.Zusammenfassend lässt sich sagen, dass hCaptchas Fähigkeit, inmitten von massiven Ausfällen bei zwei der größten Internetdienstleister der Welt stabil online zu bleiben, auf konsequenter Planung, differenzierter Technologieauswahl und umfangreichen Monitoring- sowie Failover-Mechanismen beruht.
Durch eine Kombination aus aktivem Multi-Cloud Einsatz, selektiver Cloud-Feature-Nutzung, eigenen Beobachtungssystemen und der Vermeidung versteckter Abhängigkeiten gelingt es hCaptcha, Verfügbarkeit auf höchstem Niveau zu gewährleisten. Dieses Architekturmodell ist ein überzeugendes Beispiel dafür, wie moderne Webinfrastrukturen trotz der wachsenden Zentralisierung in der Cloud-Industrie widerstandsfähig und zuverlässig bleiben können. Für Unternehmen, die von Clouddiensten abhängig sind, bietet hCaptcha so wertvolle Erkenntnisse darüber, wie man auch in instabilen Zeiten die Kontrolle über seine Systeme behält und die Nutzererfahrung nicht leidet. Wer einen tiefgehenden Einblick in resilienten Aufbau und zuverlässige Servicegestaltung sucht, findet in hCaptchas Vorgehensweise zahlreiche Inspirationen. Die Herausforderung bleibt, diese Prinzipien auf das eigene Umfeld zu übertragen und kontinuierlich anzupassen, denn in einer digitalisierten Welt gilt Verfügbarkeit als eines der höchsten Güter.
Weiterhin zeigt das Beispiel, wie wichtig es ist, die eigenen Abhängigkeiten akribisch zu verstehen und sich gegen Verbundausfälle durch systematische Redundanz und Flexibilität zu schützen. Dies sichert die digitale Souveränität und erhöht die Stabilität von Diensten selbst in einem zunehmend konzentrationsgefährdeten Marktumfeld.