Die digitale Welt entwickelt sich rasant, und Künstliche Intelligenz (KI) sowie Sprachmodelle wie ChatGPT verändern bereits heute, wie wir mit Anwendungen interagieren und persönliche Daten nutzen. Während personalisierte Dienste an Bedeutung gewinnen, wachsen gleichzeitig die Bedenken hinsichtlich Datenschutz und Kontrolle über die eigenen Informationen. In diesem Kontext wird die Frage immer dringlicher, wie Erinnerungen und persönliche Daten, die durch die Interaktion mit KI-Anwendungen entstehen, sicher und nutzerfreundlich geteilt werden können. Ein vielversprechender Ansatz ist die Adaption von OAuth, einem inzwischen bewährten Standard für sichere Autorisierung, auf den Bereich der KI-Erinnerungen. Doch was bedeutet das konkret – und welche Herausforderungen und Chancen gibt es dabei? Traditionelle Personalisierung in Apps beruhte lange Zeit auf der Sammlung von Verhaltensdaten oder explizit vom Nutzer angegebenen Präferenzen.
Während dies grundsätzlich zu besseren Nutzererlebnissen führte, war der Prozess oft langsam und mit einem erheblichen Aufwand für die Nutzer verbunden. Die Sammlung von Daten geschah meist isoliert innerhalb einzelner Plattformen, und die Möglichkeit, diese Daten zwischen verschiedenen Diensten auszutauschen, bestand kaum. Mit dem Aufkommen von KI-gestützten Chatbots und deren Fähigkeit „Erinnerungen“ an Nutzerinteraktionen zu speichern, ergeben sich völlig neue Möglichkeiten, wie Personalisierung schneller, effizienter und umfassender funktionieren kann. Chatbots wie ChatGPT oder spezialisierte KI-Therapeuten lernen kontinuierlich aus Gesprächen und bauen ein Bild von den individuellen Vorlieben, Interessen und sogar Stimmungen ihrer Nutzer auf. Diese sogenannten „Erinnerungen“ können theoretisch von hohem Wert sein, wenn man sie etwa für andere Apps oder Dienste freigibt, die damit ohne erneute Eingabe oder Schulung sofort personalisierte Erfahrungen ermöglichen könnten.
Doch aktuell sind diese Erinnerungen in der Regel in den Silos der jeweiligen Anbieter gefangen. Nutzer haben kaum Kontrolle darüber und können ihre Daten nicht einfach extrahieren oder zwischen Anwendungen teilen. Hier setzt die Idee an, eine Art sicherer Zwischenschicht zu entwickeln, mit der Nutzer selbst bestimmen können, welche Erinnerungen sie in welchem Umfang mit welchen Anwendungen teilen möchten. Eine solche Lösung könnte die Vorteile von Personalisierung maximieren, ohne dass Nutzer komplett die Kontrolle über ihre Daten verlieren. Dabei spielen Konzepte aus bestehenden Webtechnologien eine zentrale Rolle – allen voran OAuth.
OAuth hat sich als Industriestandard für den sicheren und transparenten Zugriff auf Benutzerdaten etabliert. Ursprünglich entwickelt, um Plattformen zu ermöglichen, im Namen eines Nutzers auf bestimmte Daten zuzugreifen, ohne ihm sein Passwort preiszugeben, hat OAuth einen Paradigmenwechsel hin zu fein granularen Berechtigungen und jederzeitiger Widerrufbarkeit der Zugriffsrechte gebracht. Dies hat nicht nur die Sicherheit erhöht, sondern auch den Komfort für Nutzer enorm verbessert. Deutlich wird dies am Beispiel der Integration von Kalender-Apps oder Social Media Plattformen, die über OAuth ohne Passworteingabe miteinander verbunden werden können. Die Übertragung dieses Autorisierungsansatzes auf Erinnerungen von KI-Systemen ist naheliegend, aber zugleich komplex.
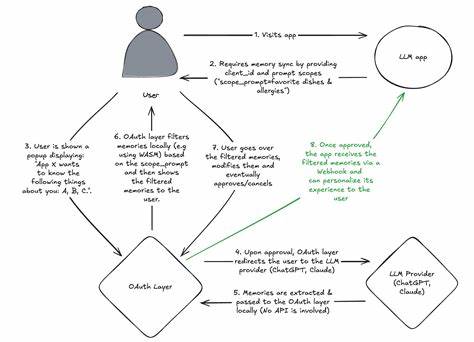
Erinnerungen sind im Gegensatz zu einer bloßen Berechtigung nicht einfach ein Tokensatz, der jederzeit widerrufen werden kann. Werden persönliche Erinnerungen einmal geteilt, gibt es keine Garantie, dass der Empfänger diese Information wieder vergisst oder sie nicht weiterverarbeitet. Deshalb ist der Schutz und die Kontrolle über diese Daten besonders wichtig und erfordert technische und organisatorische Innovationen, die über das heutige OAuth-Modell hinausgehen. Einen vielversprechenden Vorschlag für ein solches System präsentierte Dudu Lasry im Jahr 2025 in einem Projekt, das auf einer Kombination aus standardisierten Autorisierungsflüssen, lokal ausgeführter Datenverarbeitung und Nutzerkontrolle basiert. Im Kern sieht seine Idee vor, dass Nutzer bei einer neuen Anwendung, die Zugriff auf ihre KI-Erinnerungen anfragt, zunächst zu einem vertrauenswürdigen, dritten OAuth-Dienstleister weitergeleitet werden.
Dort können sie genau einsehen, welche Erinnerungen im jeweiligen Kontext benötigt werden und explizit zustimmen oder ablehnen. Die technische Umsetzung sieht vor, dass der Nutzer mit Hilfe eines sogenannten Bookmarklets – ein kleines JavaScript-Snippet, das im Browser ausgeführt wird – direkt in der Anwendung, die seine Erinnerungen speichert, die relevanten Daten selbst extrahiert. Diese Daten werden lokal verarbeitet, verschlüsselt und anhand vordefinierter Filterkriterien in überschaubaren, relevanten Ausschnitten aufgearbeitet. Dadurch wird verhindert, dass sämtliche Erinnerungen unkontrolliert übertragen werden und die Privatsphäre des Nutzers gewahrt. Die lokale Verarbeitung ist ein entscheidender Punkt: Indem sensible Informationen direkt im Browser des Nutzers analysiert und gefiltert werden, werden diese Daten nicht an Dritte gesendet.
Das minimiert das Risiko von Datenlecks oder ungewolltem Missbrauch erheblich. Zusätzlich kann der Nutzer vor der finalen Weitergabe eine detaillierte Überprüfung vornehmen, bei der einzelne Informationen bearbeitet oder entfernt werden können. Dieser Ansatz adressiert damit nicht nur das technische Problem der sicheren Datenfreigabe, sondern stärkt auch die Nutzerautonomie und damit das Vertrauen in KI-basierte Personalisierung. Die Erinnerung als wertvolle, jedoch sensible Ressource bleibt kontrollierbar, differenzierbar und transparent. Natürlich ist dieses Konzept nicht ohne Herausforderungen.
Zum einen stellt sich die Frage, ob die großen KI-Anbieter wie OpenAI, Anthropic oder Google selbst Interesse daran haben, ihren Nutzern das unkomplizierte und offene Teilen von Erinnerungen zu ermöglichen. Für viele Unternehmen sind Nutzerdaten ein zentrales Asset, das sie nicht gern ohne Kontrolle abgeben. Die notwendige Infrastruktur für ein solches OAuth-ähnliches System ist auf Seiten der Anbieter derzeit auch wenig ausgebaut. Zum anderen gibt es technische Limitierungen im Browserumfeld und bezüglich des Datenschutzes, die eine reibungslose Umsetzung erschweren. Content-Security-Policies der KI-Anwendungen können das Ausführen externer Skripte oder Bookmarklets behindern.
Auch die Größe und Komplexität der zu verarbeitenden Daten begrenzen die Möglichkeiten, insbesondere im Hinblick auf lokale Hardware-Ressourcen. Ebenso sind Sicherheitsaspekte wie Schutz gegen Cross-Site-Request-Forgery (CSRF) und korrekte Validierung von Redirect-URIs essentiell, um das System wirklich sicher im Alltag nutzbar zu machen. Weiterhin ist die Dynamik von Erinnerungen zu bedenken: Nutzeransichten und Stimmungen ändern sich, und so muss ein System zur Speicher- und Berechtigungsverwaltung auch die Aktualisierung und das Widerrufen bereits geteilter Informationen ermöglichen. Dies ist technisch und organisationsseitig sehr aufwendig umzusetzen, insbesondere wenn verschiedene Anwendungen regelmäßig auf den aktuellen Stand der individuellen Erinnerungen zugreifen wollen. Trotz aller Hürden ist klar, dass die Vision von OAuth für KI-Erinnerungen eine bedeutsame Zukunftsperspektive darstellt.
Wenn es gelingt, den Nutzer in den Mittelpunkt der Datenkontrolle zu stellen und dabei moderne technische Standards einzusetzen, könnten viele alltägliche digitale Erfahrungen leichter, sicherer und persönlicher werden. Beispielsweise könnten Apps für Jobvermittlung, Gesundheit, Dating oder Education ohne zeitraubende Registrierung oder erneute Eingaben sofort relevante Angebote zeigen, die auf den individuellen Kontext abgestimmt sind. Damit ein breiter Rollout gelingt, wären jedoch enge Kooperationen zwischen KI-Anbietern, Entwicklern und Datenschutzexperten notwendig. Standards müssten weiter definiert und von allen Beteiligten akzeptiert werden. Nutzer müssten sensibilisiert und umfassend über ihre Rechte und Möglichkeiten aufgeklärt werden, um das Vertrauen zu fördern.