Im Bereich der künstlichen Intelligenz und speziell bei generativen Modellen hat die Entwicklung von Diffusionsmodellen in den letzten Jahren stark an Bedeutung gewonnen. Diese Modelle, die darauf spezialisiert sind, Muster zwischen einer Quellverteilung und einer Zielverteilung zu transportieren, haben sich vor allem bei der Bildsynthese als sehr leistungsfähig erwiesen. Ein zentrales Problem in diesem Zusammenhang stellt jedoch die eindeutige Zuordnung von sogenannten Flows, also der Bewegung von Datenpunkten im Raum während des Trainingsprozesses, dar. Hier setzt die neu entwickelte Methode des Contrastive Flow Matching an und ermöglicht eine deutlich verbesserte Modellierung, speziell in bedingten Szenarien wie etwa bei klassenspezifischen oder textgesteuerten Bildgenerierungen. Traditionelle Flow-Matching-Verfahren funktionieren darauf, Flows zwischen einzelnen Datenpaaren eindeutig zu bestimmen und dadurch eine klare, unverwechselbare Bewegung von der Quell- zur Zielverteilung sicherzustellen.
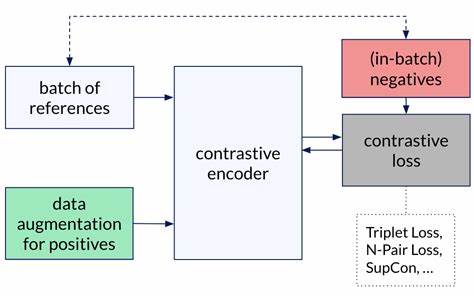
Während dies in unbedingten Settings gut funktioniert, ergibt sich bei bedingten Modellen ein fundamentaler Nachteil: Die Flows, die für unterschiedliche Bedingungen (beispielsweise verschiedene Klassen oder Textbeschreibungen) berechnet werden, können sich überlappen. Diese Überlappungen führen zu einer erhöhten Ambiguität in der Generierung, was wiederum die Qualität und Vielfalt der erzeugten Daten erheblich einschränkt. Contrastive Flow Matching erweitert das klassische Flow-Matching-Konzept, indem es eine zusätzlich kontrastive Komponente ins Training integriert. Diese sorgt explizit dafür, dass die Flows, die aus unterschiedlichen Bedingungen hervorgehen, möglichst disjunkt und unterscheidbar bleiben. Dadurch wird die Einzigartigkeit und Separierung der einzelnen Bedingungen verstärkt, was sich in klareren, präziseren und vielfältigeren generativen Ergebnissen niederschlägt.
Die Integration eines kontrastiven Verlustterms maximiert gewissermaßen die Unterschiedlichkeit zwischen allen möglichen Paaren von Flows und sorgt somit für eine effektivere Trennung der Daten in latenten Räumen. Auf praktischer Ebene haben Untersuchungen gezeigt, dass die Verwendung von Contrastive Flow Matching eine Reihe von signifikanten Vorteilen bietet. Zu den bemerkenswertesten gehört die drastisch verbesserte Trainingsgeschwindigkeit, die in einigen Fällen um den Faktor neun gegenüber herkömmlichen Flow-Matching-Methoden ansteigt. Diese Effizienzsteigerung ist ein wichtiger Fortschritt, da die bisherigen Trainingsprozesse für Diffusionsmodelle oft sehr ressourcen- und zeitintensiv waren. Darüber hinaus führt die Methode zu einer erheblichen Reduktion der erforderlichen De-noising-Schritte, teilweise um das Fünffache.
Das bedeutet, dass Modelle schneller zu hochqualitativen Ergebnissen gelangen und damit auch besser skalierbar sind, beispielsweise für Anwendungen, in denen Echtzeit- oder Low-Latency-Generationen gefragt sind. Ein weiterer großer Pluspunkt ist die messbare Verbesserung der generierten Bildqualität, bewertet mit dem bekannten Fréchet Inception Distance (FID). Hier konnten Verbesserungen von bis zu 8,9 Punkten erreicht werden, was für die Forschung und Praxis im Bereich der computergenerierten Bilder ein großer Meilenstein ist. Contrastive Flow Matching wurde auf unterschiedlichen Datensätzen und Architekturen erfolgreich validiert. Klassisch genutzte Benchmarks wie ImageNet-1k für klassengesteuerte Bildgenerierung und der Common Crawl 3M (CC3M) Datensatz im text-zu-Bild-Bereich zeigen durchgängig, dass die Methode zu besseren Trennungsergebnissen zwischen Bedingungen und damit zu einer deutlich verbesserten Bildqualität führt.
Die Vielfalt der getesteten Modelle unterstreicht die Robustheit und breite Anwendbarkeit des Ansatzes, was ihn zu einer attraktiven Option für zukünftige Forschungsarbeiten und industrielle Anwendungen macht. Im Kontext der praktischen Implementierung ist besonders hervorzuheben, dass die erweiterte Trainingsfunktionalität mit kontrastivem Verlust gut in bestehende Workflows integriert werden kann. Entwickler und Forscher profitieren zudem von der veröffentlichten Codebasis, die den schnellen Einstieg und die Reproduktion der Ergebnisse erleichtert. Dies fördert eine breite Adaption und beschleunigt die Weiterentwicklung effektiverer generativer Modelle. Die theoretischen Grundlagen von Contrastive Flow Matching bauen auf den Prinzipien der Transporttheorie und der Kontrastiven Lernmethoden auf.
Während herkömmliche Flow-Matching-Algorithmen Flows als deterministische Bewegungen definieren, die eine Basis für den Wahrscheinlichkeitsfluss zwischen Verteilungen bilden, erweitert die kontrastive Komponente diese Idee, indem sie den Raum so gestaltet, dass Flows unterschiedlicher Bedingungen sich möglichst wenig überschneiden. Dies bringt nicht nur methodisch neue Perspektiven, sondern verbindet auch stark zwei wichtige Forschungsstränge in der modernen KI: Transportbasierte Modelle und kontrastives Lernen. Neben den offensichtlichen Vorteilen bei der Bildsynthese birgt Contrastive Flow Matching auch Potenzial für weitere Anwendungen. Beispielsweise könnten Text-to-Speech-Synthese, Videoerzeugung oder multimodale Systementwicklungen ebenfalls von der durch diese Methode verbesserten bedingten Flussbildung profitieren. Insbesondere in Szenarien mit komplexen und vielfältigen Bedingungen, bei denen die Trennung und differenzierte Handhabung von Datenströmen entscheidend ist, kann diese Technik entscheidende Verbesserungen ermöglichen.
Die bahnbrechenden Fortschritte durch Contrastive Flow Matching zeigen zudem, wie sich moderne KI-Modelle durch die intelligente Kombination verschiedener Lernansätze weiter optimieren lassen. Es demonstriert eindrucksvoll, dass die Integration von kontrastivem Lernen in bereits etablierte Algorithmen nicht nur theoretisch interessant, sondern vor allem praktisch äußerst wirkungsvoll ist. Für Forscher und Industrieexperten ergibt sich daraus eine klare Perspektive: Die Zukunft generativer Methoden liegt in der Kombination und Verknüpfung verschiedener Lernparadigmen. In der Zukunft ist davon auszugehen, dass Contrastive Flow Matching ein fester Bestandteil im Werkzeugkasten für die Entwicklung anspruchsvoller generativer Modelle wird. Die kontinuierliche Verbesserung von Trainingsmethoden und deren Effizienz ist essenziell, um die wachsenden Anforderungen an Qualität, Geschwindigkeit und Vielseitigkeit bei KI-gestützten Anwendungen zu erfüllen.
Parallel eröffnen sich durch diese Fortschritte neue Anwendungsfelder, die bislang nicht realisierbar schienen. Zusammenfassend stellt Contrastive Flow Matching eine bedeutende technologische Neuerung dar, die durch die gezielte Förderung von Einzigartigkeit in bedingten Flows die Leistung von Diffusionsmodellen erheblich steigert. Sie hilft, einige der bisherigen Grenzen zu überwinden, und ebnet den Weg für schnellere, präzisere und qualitativ hochwertigere generative KI-Anwendungen. Mit seinem vielfältigen Einsatzgebiet und der beeindruckenden Leistungssteigerung wird dieses Verfahren die Landschaft der computergenerierten Inhalte nachhaltig prägen und weiterentwickeln.