In der heutigen digitalen Welt wächst der Bedarf an präziser und strukturierter Datenverarbeitung stetig. Künstliche Intelligenz und insbesondere große Sprachmodelle (LLMs) spielen dabei eine zentrale Rolle. Die Herausforderung besteht darin, unstrukturierte Textantworten dieser Modelle in verlässliche, klar definierte Daten zu verwandeln. Der Ansatz der strukturierten Ausgabe durch Beispiele gewinnt zunehmend an Bedeutung. Mit Tools wie Instructor und Pydantic lässt sich die Generierung strukturierter Daten aus LLMs effektiv umsetzen, was die Automatisierung und Datenanalyse erheblich vereinfacht.
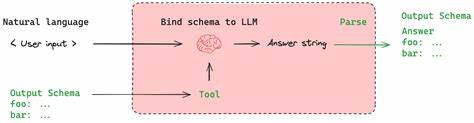
Strukturierte Ausgabe bedeutet, dass ein Sprachmodell nicht nur Freitextantworten liefert, sondern die Ausgabe in einem festgelegten, maschinenlesbaren Format erfolgt. Dies kann beispielsweise ein JSON-Dokument oder eine verschachtelte Datenstruktur sein, die klar definierte Felder enthält. So kann eine Anwendung die Informationen direkt weiterverarbeiten, ohne umfangreiche Nachbearbeitung oder fehleranfällige Parsing-Methoden. Der Schlüssel liegt darin, das Modell durch Beispiele und gezielte Anweisungen zu trainieren, damit es die gewünschte Struktur versteht und einhält. Instructor ist ein vielseitiges Framework, das speziell für die Arbeit mit LLMs entwickelt wurde und es ermöglicht, strukturierte Ausgaben systematisch zu erzeugen.
Es bietet die Möglichkeit, anhand von Beispielen direkt vorzuschreiben, wie die Antworten formatiert sein sollen. Dadurch wird die Zuverlässigkeit der Datenextraktion erheblich erhöht und die Integration in bestehende Systeme wird vereinfacht. In Kombination mit Pydantic, einer auf Python basierenden Bibliothek für Datentypvalidierung und -management, entsteht ein leistungsfähiges Werkzeug, das strukturierte Output-Modelle definiert und validiert. Die Arbeit mit Instructor und Pydantic erfordert eine moderne Python-Umgebung (Version 3.9 oder höher) sowie die aktuelle Version beider Pakete.
Der Einstieg gestaltet sich einfach durch die Definition von Modellen, die den erwarteten Datenstrukturen entsprechen. So können einfache Objekte, Listen oder komplexe verschachtelte Strukturen abgebildet werden. Ein großer Vorteil ist die integrierte Validierung, die sicherstellt, dass die gelieferten Daten den festgelegten Anforderungen entsprechen und etwaige Fehler frühzeitig erkannt werden. Für Entwickler ist die Zusammenarbeit mit verschiedenen LLM-Anbietern über Instructor ein großer Gewinn. Das Framework unterstützt unter anderem OpenAI, Anthropic, Gemini, Cohere und Mistral sowie diverse andere Anbieter.
So lässt sich die strukturierte Datenextraktion flexibel an die jeweilige Plattform anpassen und unterschiedliche Modelle für spezifische Anwendungsfälle nutzen. Diese Integration erleichtert die Nutzung hochmoderner Sprachmodelle und hilft dabei, deren Output gezielt für strukturierte Datensätze zu verwenden. Typische Anwendungsfälle reichen von der einfachen Extraktion einzelner Objekte bis hin zu umfangreichen verschachtelten Datenbanken. Sogar optionale Felder lassen sich problemlos definieren, sodass die Datenstruktur äußerst flexibel gestaltet werden kann. Neben rein textbasierten Eingaben beherrscht Instructor auch multimodale Inputs, wodurch sich das Framework für Bild-, Audio- und Dokumentenanalyse erweitert.
So können beispielsweise Tabellen aus PDFs extrahiert oder Informationen aus Bildern und Audiodateien gewonnen werden. Die Nutzung von strukturiertem Output erstreckt sich auch auf Klassifikationsaufgaben. Ob einfache Kategorisierungen oder komplexere Mehrfachzuordnungen, das strukturierte Modell ermöglicht eine genaue und nachvollziehbare Ergebnisdarstellung. In Verbindung mit Streaming-Funktionen lassen sich selbst große und komplexe Datenströme effizient verarbeiten, was insbesondere bei Anwendungen mit Echtzeitanalyse von Vorteil ist. Für anspruchsvolle Projekte, die tief verschachtelte oder rekursive Strukturen erfordern, bietet Instructor erweiterte Möglichkeiten.
Das Erstellen von Wissensgraphen, Abhängigkeitsbäumen oder komplexen Aufgabenplänen ist ebenso realisierbar wie die Modellierung der Dokumentenstruktur. Dabei ist die Validierung und Qualitätssicherung der Daten ein zentraler Baustein und wird durch Pydantic und individuelle Validierungsmechanismen unterstützt. Die Optimierung der Performance spielt eine wichtige Rolle, wenn strukturierte Daten im produktiven Umfeld schnell und zuverlässig generiert werden müssen. Möglichkeiten zur Zwischenspeicherung, parallelen Verarbeitung oder Batch-Extraktion erhöhen die Effizienz und reduzieren die Kosten. Zusätzlich lassen sich Hooks und Callbacks einsetzen, um das Verhalten bei der Datenausgabe gezielt anzupassen und verschiedene Anpassungen auf Typenebene vorzunehmen.
Abschließend ist zu betonen, dass die Kombination von Instructor und Pydantic einen starken technischen Fundamentstein für moderne Anwendungen darstellt, die auf strukturierte Daten angewiesen sind. Entwickler und Unternehmen profitieren von größerer Zuverlässigkeit, besserer Wartbarkeit und erhöhter Automatisierung ihres Datenflusses. Die vielseitigen Integrationsmöglichkeiten und die einfache Nutzbarkeit machen diese Tools zu einer attraktiven Wahl für alle, die das volle Potenzial von großen Sprachmodellen für strukturierte Daten nutzen möchten. Daher lohnt es sich, sich mit den Grundlagen von strukturierten Ausgaben sowie deren praktischer Umsetzung mit Instructor und Pydantic vertraut zu machen. Zahlreiche Beispiele und Anleitungen erleichtern den Einstieg und zeigen den Weg zu einer effizienten und hochwertigen Datenextraktion aus LLMs.
Die Zukunft gehört den Anwendungen, die nicht nur intelligente Texte liefern, sondern diese Inhalte auch in klar formulierter, strukturierter Form bereitstellen – für einen reibungslosen Informationsfluss und smarte Automatisierung in allen Bereichen.