Die stetig wachsenden Anforderungen an datenintensive Applikationen und Machine-Learning-Workloads stellen Unternehmen vor komplexe infrastrukturelle Herausforderungen. Bei Uber, einem globalen Anbieter im Mobilitätssektor, werden täglich immense Mengen an Daten generiert, die in Echtzeit verarbeitet und analysiert werden müssen. Um dies zu ermöglichen, wurde die Data Science Workbench (DSW) entwickelt – eine interaktive Notebook-Plattform, die Datenwissenschaftlern und ML-Ingenieuren eine vielschichtige Umgebung für Analyse, Modelltraining und Visualisierung bietet. Die Plattform stellt individualisierte, isolierte Container bereit, in denen unter anderem Jupyter- und RStudio-Notebooks betrieben werden. Diese erfordern vielseitige Ressourcen wie GPU, Speicher und Rechenleistung, was die Infrastruktur besonders anspruchsvoll macht.
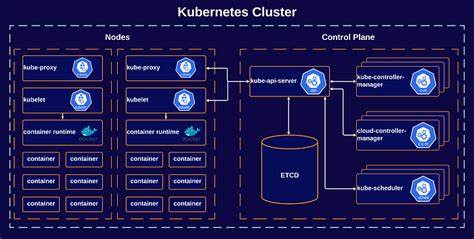
Die ursprüngliche Container-Orchestrierung fand mit Peloton statt, einem auf Apache Mesos basierenden System. Im Zuge der Modernisierung wurde die Migration zu Kubernetes geplant und durchgeführt – mit dem Ziel, den Betrieb ohne Unterbrechungen sicherzustellen und gleichzeitig die Verwaltung zu vereinfachen. Die Herausforderung, mehrere tausend interaktive Sitzungen mit unterschiedlichsten Anforderungen auf eine neue Orchestrierungsplattform zu übertragen, ohne die Nutzererfahrung zu beeinträchtigen, ist enorm. Kubernetes ist traditionell für kurzlebige Batch-Jobs konzipiert, nicht aber für langlaufende interaktive Workloads. Die Anpassung des Betriebsmodells war deshalb essenziell.
Uber entschied sich, jede DSW-Sitzung als Kubernetes Job mit modifizierten Parametern abzubilden. Dabei wurde die Parallelität auf einen einzelnen Pod begrenzt und eine sehr hohe Anzahl an „Completions“ gewählt, um eine permanente Laufzeit zu simulieren. Durch eine ausgefeilte Restart-Politik konnten Pods bei Fehlfunktionen automatisch neu gestartet werden, ohne dabei den Nutzer nachhaltig zu stören. Ein zentrales Problem betraf den Umgang mit NFS-Mounts, die für die Persistenz von Sitzungen über mehrere Starts hinweg notwendig sind. Während Kubernetes mittlerweile NFS durch Container Storage Interface (CSI)-Treiber gut unterstützt, war dies bei Ubbers frühem Kubernetes-Einsatz noch nicht möglich.
Die Lösung bestand darin, die NFS-Mounts weiterhin bei dedizierten Host-Gruppen bereitzustellen, jedoch mit einer Vermischung und Vereinheitlichung über den kompletten Kubernetes-Fleet hinweg. Dies garantierte eine nahtlose Datenverfügbarkeit unabhängig vom ausgeführten Cluster oder der Zone. Die Persistenz der vom Nutzer installierten Python- oder R-Pakete stellte eine weitere technische Hürde dar. Die in Memory oder lokalen Dateisystemen abgelegten Umgebungen gingen bei Containerneustarts verloren, was zu Produktivitätseinbußen führte. Uber entwickelte daher ein intelligentes Monitoring der Verzeichnisänderungen mittels „inotify“-Events, die durch ausgeklügeltes Debouncing gefiltert wurden.
So konnten Installationen und Deinstallationen der Pakete zuverlässig erkannt und in einem zentralen NFS-gespeicherten Index abgelegt werden. Beim Neustart einer Sitzung erfolgte dann eine automatisierte Wiederherstellung der fehlenden Pakete, wodurch die Nutzerumgebung nahezu unverändert erhalten blieb und Unterbrechungen minimiert wurden. Zur Steigerung der Verfügbarkeit und Effizienz kam die Kubernetes-Föderation, genannt Federator, zum Einsatz. Diese Abstraktionsschicht vermittelt zwischen den verschiedenen regional verteilten Kubernetes-Clustern und wählt stets optimal verfügbare Ressourcen nach aktuellen Bedarfen aus. Dies vermeidet Lastungleichgewichte, wie sie zuvor mit dedizierten Peloton-Cluster-Zuordnungen auftraten.
Ferner erhöht der Einsatz von Federator die Ausfallsicherheit, da ein Cluster- oder Zonen-Ausfall die DSW-Workloads nicht komplett beeinträchtigt. Neue Cluster können zudem ohne tiefgreifende Eingriffe in die DSW-Plattform hinzugefügt oder entfernt werden, was den Betrieb vereinfacht und Flexibilität erhöht. Ein weiterer Aspekt der Migration war die Wahrung der Nutzererwartungen hinsichtlich Monitoring und Bedienung. Peloton verfügte über eine ausgefeilte UI mit erweiterten Funktionen wie historischen Job-Daten und Ressourcenpool-Übersichten basierend auf Apache Cassandra als Datenbackend. Die native Kubernetes-Oberfläche ist im Vergleich limitiert, insbesondere bezüglich langfristiger Datenspeicherung.
Uber entwickelte deshalb ein System zur nahezu Echtzeit-Replikation von Kubernetes-Metadaten von etcd nach Cassandra. Diese Architektur ermöglichte es, die bewährte Peloton-UI zu verwenden – nun unter dem Namen Compute UI –, um auch Kubernetes-Workloads mit umfassender Beobachtbarkeit und Benutzerfreundlichkeit abzubilden. Die Migration brachte auch Veränderungen bei Log- und Sandbox-Browsing-Funktionen mit sich. Kubernetes verwaltet Container-Logs ephemer, sodass historische Daten nur eingeschränkt verfügbar sind. Uber implementierte eine Browse Sandbox-Funktion, mit der Nutzer Dateisysteminhalte live betrachten können.
Logs aktiver Pods werden über die Kubernetes-API gestreamt, während abgeschlossene Sitzungen archiviert und langfristig gespeichert werden. Diese Strategie sichert die Verfügbarkeit relevanter Informationen auch nach dem Container-Tod und verbessert die Diagnosemöglichkeiten der Nutzer. Ursprünglich hatte Uber die gesamte Nutzerumgebung inklusive installierter Pakete auf NFS synchronisieren wollen. Dies erwies sich jedoch als ineffizient, da die hohe Zahl an Klein-Dateien zu starken Input/Output-Operationen (IOPS) führte, die das System überlasteten. Die Entscheidung, nur eine Liste der zusätzlich installierten Pakete zu speichern und bei Neustart gezielt neu zu installieren, reduzierte die Last drastisch und bewahrte dennoch den Nutzerkomfort.
Zur Steuerung der Migration wurde eine neue Restart-API implementiert, die beim Umschalten von Peloton auf Kubernetes den Nutzer informiert, laufende Sitzungen sichert und eine transparente Umschaltung ermöglicht. So konnten über 3.500 interaktive Sessions von mehr als 2.000 Nutzern umgestellt werden, ohne dass es zu bedeutenden Ausfällen oder Beschwerden kam. Der Erfolg dieser Migration bei Uber zeigt, wie komplexe und interaktive Datenplattformen von der Umstellung auf Kubernetes profitieren können.
Die Implementierung von spezifischen Workarounds und innovativen Konzepten war maßgeblich, um disruptive Effekte zu vermeiden und gleichzeitig die Vorteile von Kubernetes wie Skalierbarkeit, Verfügbarkeit und Cloud-Portabilität zu nutzen. Langfristig plant Uber, native Kubernetes-Funktionen wie CSI-NFS-Treiber zu integrieren, um die Umgebungen noch portabler und wartungsfreundlicher zu gestalten. Das Projekt unterstreicht zudem, wie fundamentale Prinzipien moderner Infrastrukturmigration aussehen: Erweiterbarkeit, Standardisierung und Automatisierung stehen im Vordergrund, ergänzt durch eine konsequente Nutzerorientierung. Durch die enge Zusammenarbeit von Infrastruktur- und Datenplattform-Teams bei Uber konnten technische Hürden überwunden und eine moderne Compute-Plattform etabliert werden, die den Anforderungen heutiger datengetriebener Anwendungen gerecht wird. Zusammenfassend lässt sich sagen, dass die Migration großer interaktiver Compute-Workloads von einem proprietären Container-Orchestrator zu Kubernetes kein triviales Unterfangen ist.
Es erfordert tiefgreifendes Verständnis der Workloads, flexible Anpassungen an neue Paradigmen, intelligente Persistenzstrategien und eine umfassende Berücksichtigung der Nutzererfahrung. Ubers Data Science Workbench hat diese Herausforderung erfolgreich gemeistert und bietet wertvolle Erkenntnisse für Unternehmen, die ähnliche Transformationsprozesse durchführen wollen. Die Zukunft gehört offenen, hybriden Orchestrierungsplattformen, die sowohl Effizienz als auch Benutzerfreundlichkeit sicherstellen und den Weg in die Cloud und darüber hinaus ebnen.