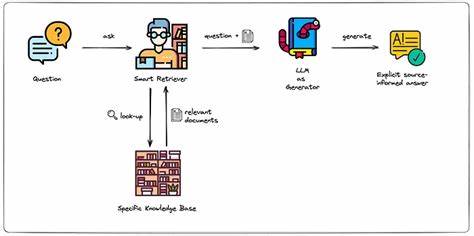
Retrieval Augmented Generation (RAG) Systeme haben in den letzten Jahren durch ihre Fähigkeit, große Informationsbestände effizient zu durchsuchen und relevante Antworten zu generieren, viel Aufmerksamkeit erlangt. Sie kombinieren dabei klassische Informationsabruftechniken mit modernen KI-Methoden, um qualitativ hochwertige Ergebnisse zu liefern. Doch trotz ihrer Leistungsfähigkeit stellen RAG Systeme Entwickler und Unternehmen vor spezifische Herausforderungen – eine der größten besteht in der richtigen Segmentierung der zugrunde liegenden Daten. Die effektive Organisation und Isolation von Informationen ist essenziell, um sowohl die Genauigkeit der Abfragen sicherzustellen als auch Datenschutz- und Sicherheitsanforderungen gerecht zu werden. In diesem Kontext spielt die Datensegmentierung eine zentrale Rolle, insbesondere wenn mehrere Nutzer oder Kunden mit unterschiedlichen Datenbeständen gleichzeitig arbeiten.
Wer sich mit der Implementierung oder Optimierung von RAG Systemen auseinandersetzt, sollte verstehen, warum die bloße Ansammlung großer Datenmengen nicht ausreichend ist und wie eine gezielte Segmentierung nachhaltige Vorteile für den Betrieb und die Nutzung von KI-Systemen bieten kann. Im Alltag vieler Unternehmen laufen oft verschiedene Bereiche wie Recht, Personalwesen und Kundensupport nebeneinander mit jeweils eigenen Wissensdatenbanken. Wenn in einem RAG System alle Dokumente unstrukturiert in einen einzigen Pool geladen werden, entstehen dabei diverse Probleme. Beispielweise könnten vertrauliche Informationen versehentlich zwischen Abteilungen ausgetauscht werden oder Suchergebnisse vermischen sich so stark, dass sie irrelevant oder sogar irreführend werden. Insbesondere in Multi-Tenant-Anwendungen, bei denen unterschiedliche Kunden eigene, meist private Datenbestände haben, können solche Vermischungen zu gravierenden Datenschutzverletzungen führen.
Somit wird schnell deutlich, dass Daten nicht nur gesammelt, sondern klar voneinander abgegrenzt werden müssen. Die Datensegmentierung schafft eine logische Trennung der Dokumente in sogenannte Partitionen oder Bereiche, die jeweils eine bestimmte Informationsquelle oder einen Anwendungsbereich abbilden. Diese Isolation erlaubt es dem System, gezielt in einem eng gefassten Datenpool zu suchen und dadurch Suchtreffer präziser und kontextuell relevanter zu machen. Für die Sicherheit ist es gleichermaßen wichtig, da durch klare Grenzen verhindert wird, dass Benutzer Daten aus fremden Partitionen einsehen oder abrufen können. Zudem fördert eine solche Struktur den Überblicklichkeit und erleichtert die Verwaltung großer Datenbestände erheblich.
Aus der Perspektive der Suchalgorithmen verbessert die Datensegmentierung die Qualität der Ergebnisse erheblich. Hybrid-Suchmethoden, die sowohl Schlüsselwort-basierte Indizierung als auch semantische Suche kombinieren, profitieren maßgeblich von der klaren Datenabgrenzung. Ein großer Hebel liegt hier bei dem oft verwendeten TF-IDF-Verfahren (Term Frequency–Inverse Document Frequency), das die Wichtigkeit eines Suchbegriffs im Zusammenhang der gesamten Dokumentensammlung bewertet. Ohne Segmentierung könnten häufig vorkommende Fachbegriffe in einem bestimmten Bereich fälschlich als unwichtig eingestuft werden, wenn sie in der Gesamtheit der Daten zu oft auftreten. Beispielsweise verliert juristischer Fachjargon in einer großen deutschlandweiten Datenmenge schnell an Relevanz, wird aber innerhalb eines rechtsspezifischen Teilbereichs als hoch bedeutsam erkannt.
Durch das Aufteilen in Domänen oder Partitionen wird diese ausgleichende Bewertung deutlich präziser und somit werden die Suchergebnisse hochwertiger. Ein weiterer wichtiger Aspekt ist die Kombination von Partitionierung mit Metadatenfiltern. Metadaten wie Dokumententyp, Erstellungsdatum, Nutzer-ID oder kundenspezifische Schlüssel-Wert-Paare ermöglichen innerhalb der Segmente noch feinere Eingrenzungen beim Abruf von Informationen. So kann beispielsweise eine Suche im Personalbereich auf aktuelle Richtlinien eines bestimmten Jahres eingeschränkt oder nur Vertragsdokumente in der Rechtsabteilung ausgegeben werden. Diese multidimensionale Filterung erhöht nicht nur die Effizienz der Suche, sondern unterstützt auch unterschiedliche Zugriffsrechte und Kontrollebenen, was für Unternehmen mit strengen Compliance-Anforderungen unerlässlich ist.
Datensegmentierung trägt somit nicht nur zum Schutz vertraulicher Informationen bei, sondern wirkt sich auch direkt auf die Benutzererfahrung und die KI-Qualität aus. Ohne diese kontrollierte Aufteilung leidet die Präzision der Suchergebnisse und das Vertrauen der Nutzer in das System kann sinken. Wichtige Ergebnisse können übersehen werden oder irrelevante Treffer dominieren, was letztlich zu Frustration führt. Bei Multi-Tenant-Strukturen stellt die Segmentierung sogar eine Pflicht dar, um die Einhaltung von Datenschutzrichtlinien und branchenüblichen Standards zu gewährleisten. Darüber hinaus kann durch ein Segmentierungsmodell mit leicht implementierbaren Partitionen und Metadatenfiltern auch die Skalierbarkeit eines RAG Systems verbessert werden.
Große Wissensdatenbanken müssen nicht im Ganzen durchforstet werden, sondern lediglich relevante Ausschnitte. Dies reduziert nicht nur die Antwortzeiten bei Abfragen, sondern entlastet auch Serverkapazitäten und verbessert die allgemeine Performance des Systems. Entwickler profitieren durch die klare Strukturierung zudem von einer einfacheren Wartbarkeit und von verbesserten Möglichkeiten zur Fehlerbehebung. Während die Konzepte der Datenisolation häufig komplex erscheinen, gibt es bereits moderne Tools und Plattformen, die eine unkomplizierte Umsetzung unterstützen. Somit wird die Hürde zur Integration der Segmentierung verringert und zugleich ein nachhaltiges Qualitätsversprechen an Kunden und Stakeholder gegeben.
Beispielsweise ermöglicht die API eines spezialisierten RAG-Anbieters die einfache Anlage von Dokumenten in bestimmten Partitionen, die Zuweisung von frei definierbaren Metadaten sowie gezielte Abrufe basierend auf präzisen Filtern. Das Ergebnis sind hoch relevante Suchergebnisse, die sowohl Sicherheitsanforderungen als auch Nutzungsbedürfnissen in vollem Umfang gerecht werden. Die essentielle Erkenntnis für Unternehmen und Entwickler ist, dass Datensegmentierung kein optionales Extra, sondern eine grundlegende infrastrukturelle Maßnahme in modernen RAG Systemen darstellt. Sie kombiniert Sicherheitsaspekte mit messbarer Verbesserung der Retrieval-Qualität und ermöglicht so die volle Ausschöpfung der Potenziale von KI-gestützter Informationsbeschaffung. Darüber hinaus wird mit dieser Praxis der Grundstein für eine nachhaltige Skalierung und Verantwortlichkeit im Umgang mit großen, vielfältigen Datenbeständen gelegt.
Im digitalen Zeitalter, in dem Datenmengen exponentiell wachsen und Anforderungen an Datenschutz und User Experience steigen, wird die Bedeutung der Datensegmentierung nur noch zunehmen. Unternehmen und Entwickler, die frühzeitig darauf setzen, können so nicht nur ihre Systeme zukunftssicher gestalten, sondern auch maßgeblich zur Vertrauensbildung bei Anwendern beitragen. Letztendlich entscheidet die Qualität der Datenorganisation maßgeblich darüber, wie erfolgreich und zuverlässig ein RAG System im operativen Alltag funktioniert – von der ersten Abfrage bis zur täglichen Nutzung.








![Statistics for Hackers (2016) [video]](/images/AAA7150A-1072-4B52-92DB-1AD98DA6D9E8)