In einer Ära, in der Daten als wertvollstes Gut eines Unternehmens gelten, gewinnt die semantische Modellierung von Daten zunehmend an Bedeutung. Unternehmen stehen vor der Herausforderung, komplexe Datenlandschaften zu verstehen, zu organisieren und sie in aussagekräftige Geschäftskennzahlen zu übersetzen. Hier setzt Publisher an – der Malloy Semantic Model Server, ein Open-Source-Tool, das es ermöglicht, semantische Modelle einmal zu definieren und überall konsistent zu verwenden. Publisher ist eng mit der Datenmodellierungssprache Malloy verbunden, die eigens für die Erstellung von semantic Data Models entwickelt wurde. Malloy erlaubt es, Geschäftslogik präzise abzubilden, indem Begriffe wie Umsatz, aktive Nutzer oder Kundenabwanderung nicht nur als einfache Datenpunkte, sondern als verständliche, versionierte und leicht nachvollziehbare Modelle definiert werden.
Diese Modelle bilden das Rückgrat von Publisher und sorgen dafür, dass Analysen, Berichte und KI-basierte Anwendungen immer auf einer vertrauenswürdigen und einheitlichen Datenbasis aufbauen. Die Besonderheit von Malloy besteht darin, dass es weit über herkömmliche SQL-Queries hinausgeht. Während SQL häufig in der Welt der Datenanalyse als Standard fungiert, stellt es meist rohe Daten dar, die fachlich interpretiert und aufbereitet werden müssen. Malloy hingegen definiert Business-Metriken und Beziehungen im Modell selbst. Dieser semantische Layer schützt Unternehmen davor, unterschiedliche Interpretationen derselben Daten zu bekommen, was gerade in komplexen Organisationen mit vielen Stakeholdern essenziell ist.
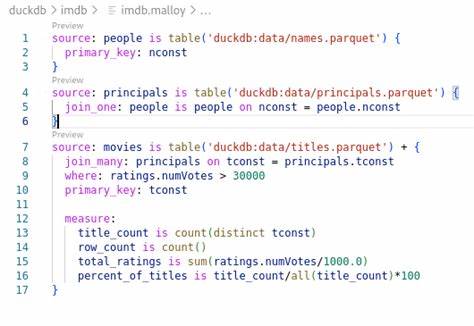
Publisher stellt die Brücke dar, mit der diese semantischen Modelle in real nutzbare Daten-APIs verwandelt werden. Die Plattform bietet eine Reihe von Schnittstellen, mit denen Anwendungen, Dashboards, AI-Agenten und Analyse-Tools auf ein und dasselbe Modell zugreifen können. Damit entstehen vertrauenswürdige, wiederverwendbare und leicht erweiterbare Datenressourcen, die Fehlerquellen durch Inkonsistenzen minimieren. Eine der großen Stärken von Publisher ist seine modulare Architektur, die sich in drei wesentliche Komponenten gliedert: den Publisher Server, das Publisher SDK und die Publisher App. Der Server ist das Herzstück und lädt die Malloy Packages – also gebündelte Sammlungen von Modellen, Notebooks und Transformationen.
Damit wird eine einheitliche Datenbasis geschaffen, die von verschiedensten Tools abgefragt werden kann. Die SDK-Bibliothek stellt Entwicklern wiederverwendbare React-Komponenten zur Verfügung, sodass eigene Datenanwendungen schnell und effizient auf Basis von Publisher gebaut werden können. Die Publisher App wiederum ist eine Referenzimplementierung, die eine benutzerfreundliche Oberfläche für die Erkundung, Abfrage und Visualisierung der Modelle bietet. Ein zentraler Bestandteil des Systems ist der Explorer, eine visuelle Abfrageplattform, die es auch nicht-technischen Nutzerinnen und Nutzern erlaubt, Modelle zu verstehen, Abfragen zu erstellen und Datenanalysen durchzuführen – ohne eine einzige Zeile SQL-Code schreiben zu müssen. Dies fördert die Selbstbedienungskompetenz in Unternehmen und beschleunigt datengetriebene Entscheidungen.
Für technisch versierte Nutzer oder Entwickler wiederum gibt es die Möglichkeit, Malloy Notebooks zu verwenden. Diese Code-first Dashboards ermöglichen eine reproduzierbare, transparente und flexible Analyseumgebung. Mit Text, Diagrammen, eingebetteten Abfragen und stets live am Modell orientiert bieten sie einen perfekten virtuellen Arbeitsraum für Data Scientists oder BI-Teams. Ein weiterer wichtiger Aspekt von Publisher ist die Integration mit fortschrittlichen KI-Systemen über das Model Context Protocol (MCP). Diese offene Schnittstelle ermöglicht es KI-Agenten, die in Aptituden zur Verarbeitung natürlicher Sprache und automatisierten Datenanalyse besitzen, semantische Modelle zu entdecken, gezielt Abfragen zu formulieren und erklärbare Antworten zu liefern.
So lassen sich kommerzielle oder kundenspezifische AI-Lösungen sinnvoll in bestehende Datenlandschaften einbinden und von der einheitlichen Bedeutung der Daten profitieren. Auch die zukünftigen Erweiterungen von Publisher sind vielversprechend. So ist die Einführung einer SQL-kompatiblen Schnittstelle geplant, die es ermöglicht, etablierte Business-Intelligence-Tools wie Tableau, Power BI oder Metabase direkt auf den Malloy-Modellen arbeiten zu lassen. Das verspricht eine erhebliche Effizienzsteigerung, da es nicht mehr notwendig ist, doppelte Logik in vielfältigen Systemen zu pflegen. Die Skalierbarkeit und Governance sind weitere zentrale Themen, die Publisher souverän adressiert.
Durch die Nutzung von Standard-Softwareentwicklungspraktiken wie Paketverwaltung, Versionierung, CI/CD-Pipelines und Containerisierung wird sichergestellt, dass Datenmodelle nicht nur im kleinen Team funktionieren, sondern auch in großen Organisationen gut beherrschbar bleiben. Dieses Paradigma gestattet es Unternehmen, Daten als strategisches Asset systematisch zu verwalten und dabei Compliance, Konsistenz und Nachvollziehbarkeit sicherzustellen. Der Entwicklerprozess selbst wird durch den Einsatz von Git-Submodulen für Malloy-Samples, automatisierte Builds mittels der JavaScript Runtime bun und klare Konfigurationsstrukturen optimiert. Die Trennung zwischen serverweiter Projektübersicht und environment-spezifischen Verbindungseinstellungen erlaubt nahtloses Deployment über Entwicklungs-, Test- und Produktionsumgebungen hinweg – ein entscheidender Vorteil für agile und sichere Dateninfrastrukturen. Publisher ist somit nicht nur ein Werkzeug für Data Engineers und Entwickler, sondern auch ein strategischer Baustein für Unternehmen, die ihre datengetriebenen Entscheidungsprozesse auf ein neues Level heben wollen.
Von der klaren semantischen Definition bis zur flexiblen Nutzung durch verschiedene Anwenderschichten unterstützt Publisher alle Aspekte moderner Datenanalyse, von der Zahl bis zur Geschichte hinter den Zahlen. Darüber hinaus fördert die Open-Source-Natur von Publisher eine lebendige Community aus Datenexpertinnen und -experten, die sich austauschen, neue Ideen einbringen und gemeinsam an der Zukunft der semantischen Modellierung arbeiten. Die transparente Entwicklung und die Möglichkeit, Publisher individuell zu erweitern, bieten Unternehmen Ruhe und Sicherheit, sich langfristig auf diese Infrastruktur zu verlassen. Abschließend lässt sich feststellen, dass Publisher mit dem Malloy Semantic Model Server ein revolutionäres Konzept verfolgt, das die Brücke zwischen technischem Datenmanagement und geschäftlichem Anwendungsnutzen schlägt. In einer Zeit, in der Datenflut Unternehmen häufig überfordert, schafft Publisher Ordnung, Vertrauen und neuen Mehrwert.
Wer seine Datenstrategie zukunftssicher gestalten möchte, sollte Publisher als zentrale Plattform für die semantische Datenmodellierung und -bereitstellung in Betracht ziehen – eine Lösung, die Transparenz, Flexibilität und Governance in Einklang bringt.