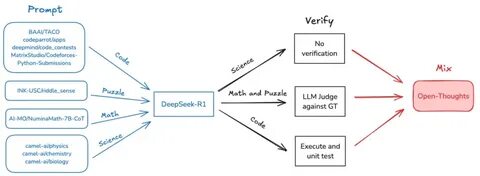
Die rasante Entwicklung von künstlicher Intelligenz hat besonders im Bereich der Reasoning-Modelle bemerkenswerte Fortschritte erzielt. Reasoning, oder auf Deutsch das schlussfolgernde Denken, ist eine der anspruchsvollsten Eigenschaften menschlicher Intelligenz und wird zunehmend in Maschinen nachgebildet. Doch trotz beeindruckender Ergebnisse bestehen weiterhin Herausforderungen bei der Datenbasis und den Trainingsverfahren dieser Modelle. In diesem Kontext tritt das OpenThoughts-Projekt hervor, das mit seinen innovativen Datenrezepte für Reasoning-Modelle eine wichtige Lücke schließt. OpenThoughts verfolgt das Ziel, offene und zugängliche Datensätze bereitzustellen, die speziell für das Training von Modellen mit starken logischen, mathematischen und Programmierfähigkeiten entwickelt wurden.
Dies steht im Gegensatz zu vielen gegenwärtigen Methoden, die auf proprietären, oftmals geheimen Daten beruhen, deren Zusammensetzung und Qualität kaum überprüfbar ist. Die Verfügbarkeit solcher offenen Daten bietet Forschern und Entwicklern weltweit die Möglichkeit, Reasoning-Modelle transparent, reproduzierbar und effizient zu trainieren. Der Weg von OpenThoughts begann mit der Erstellung des Datensatzes OpenThoughts2-1M, der bereits bedeutende Erkenntnisse im Bereich der Modellierung von Reasoning-Fähigkeiten ermöglichte. Aufbauend darauf wurde das Modell OpenThinker2-32B trainiert, das als erstes auf öffentlich zugänglichen Daten basierendes System mit einem proprietären Branch namens DeepSeek-R1-Distill-32B in etablierten Benchmark-Tests wie AIME und LiveCodeBench gleichziehen konnte. Diese Leistung markiert einen Meilenstein, der zeigt, dass offene Daten keineswegs den Fortschritt einschränken müssen.
Die anschließende Weiterentwicklung beruhte auf einem systematischen und umfassend kontrollierten Optimierungsprozess. Über 1.000 kontrollierte Experimente wurden durchgeführt, um die einzelnen Schritte der Datenpipeline zu verfeinern. Daraus entstand OpenThoughts3, eine noch reichhaltigere und besser kuratierte Sammlung von Trainingsdaten, die auf 1,2 Millionen Beispiele skaliert wurde. Für die Modellierung kam zudem QwQ-32B als Lehrer-Modell zum Einsatz, das zusätzliche Lernimpulse lieferte und die Leistungsfähigkeit weiter steigerte.
Das resultierende Modell, OpenThoughts3-7B, beeindruckte mit herausragenden Leistungen auf renommierten Herausforderungen. Mit 53 Prozent auf dem AIME 2025, 51 Prozent auf LiveCodeBench und 54 Prozent auf dem GPQA Diamond übertraf es vergleichbare Modelle wie DeepSeek-R1-Distill-Qwen-7B um einen weiten Abstand von 15 bis 20 Prozentpunkten. Diese Resultate zeigen nicht nur den Erfolg der Daten- und Pipeline-Optimierung, sondern auch die herausragende Bedeutung offener und systematisch entwickelter Datensätze für das Training moderner Reasoning-Modelle. Neben den Benchmark-Ergebnissen repräsentiert OpenThoughts einen Paradigmenwechsel für die KI-Forschung: Die Kombination aus öffentlicher Zugänglichkeit, transparenten Trainingsprozessen und systematischer Optimierung schafft eine solide Basis, um Reasoning-Modelle weiterzuentwickeln und für eine breite Palette praktischer Anwendungen zugänglich zu machen. Insbesondere in Bereichen wie naturwissenschaftlicher Forschung, komplexer Programmierung und mathematischer Problemlösung können solche Modelle künftig eine zentrale Rolle spielen.
Ein entscheidendes Merkmal von OpenThoughts ist die Methodik des „Data Recipes“, also der systematischen Zusammensetzung und Optimierung von Trainingsdatensätzen. Dies beinhaltet die kuratierte Auswahl und Generierung von Aufgaben unterschiedlicher Schwierigkeit und Komplexität, die ein Modell für ein robustes Verständnis und fundierte Schlussfolgerungen benötigt. Indem die Datenpipeline iterativ getestet und verbessert wird, entsteht eine verfeinerte Datenbasis, die das Modell befähigt, komplexe Denkprozesse nachzuvollziehen und anzuwenden. Die Einführung von Teacher-Modellen wie QwQ-32B innerhalb des Trainingsprozesses ist ein weiterer wichtiger Schritt. Diese Lehrer-Modelle dienen als qualitativ hochwertige Vorbilder und helfen dabei, die Lernqualität zu erhöhen.
Sie geben dem zu trainierenden Modell wertvolle Hinweise und ermöglichen eine effizientere Anpassung der Gewichte innerhalb des neuronalen Netzwerks. Dies führt zu einer höheren Genauigkeit und besseren Generalisierungsfähigkeit in verschiedenen logischen und mathematischen Aufgaben. Der offene Zugang zu allen Datensätzen und Modellen des OpenThoughts-Projekts stellt einen wichtigen Vorteil dar. Neben akademischer Forschung profitieren auch Entwickler in der Industrie, Open-Source-Communities und Bildungseinrichtungen von dieser Transparenz. Es ermöglicht eine Zusammenarbeit, bei der Erkenntnisse geteilt, erweitert und gemeinsam auf Herausforderungen reagiert werden kann, was den Fortschritt für alle Beteiligten beschleunigt.
Zudem tragen optimierte Reasoning-Modelle maßgeblich dazu bei, die Fähigkeit von KI-Systemen zu verbessern, nicht nur Antworten zu liefern, sondern diese auch nachvollziehbar und logisch begründet zu präsentieren. Gerade in kritischen Anwendungen, wie automatischer Codegenerierung, wissenschaftlicher Forschung oder Entscheidungsunterstützung, ist diese Eigenschaft unerlässlich. OpenThoughts leistet hier durch seine ausgereiften Modelle einen wertvollen Beitrag. Die Anwendungsmöglichkeiten der durch OpenThoughts geschaffenen Frameworks und Modelle sind enorm. In der wissenschaftlichen Analyse können komplexe Hypothesen geprüft, in der Programmierung fehleranfällige Logik automatisch erkannt und korrigiert werden, und im Bildungsbereich können Schüler durch maßgeschneiderte Übungsaufgaben mit moderner KI-Unterstützung gefördert werden.
Dieses breite Spektrum zeigt die Vielseitigkeit und den praktischen Nutzen von offenen Reasoning-Daten und -Modellen. Ein weiterer zukunftsweisender Aspekt ist die mögliche Kombination von OpenThoughts-Daten mit anderen Ausbildungsstrategien, wie beispielsweise multimodalen Daten oder durch Interaktion lernenden Systemen. Diese Erweiterungen könnten die Fähigkeit von Modellen zur Vernetzung von Wissen und zur kreativen Problemlösung weiter verstärken. So eröffnen sich Perspektiven, KI-Systeme zu entwickeln, die in immer vielfältigeren und realistischeren Kontexten erfolgreich agieren. Zudem trägt die dokumentierte iterative Verfeinerung des Datensatzes dazu bei, eine kulturübergreifende und diverse Wissensbasis zu schaffen, die Bias minimiert und einen faireren Zugang zu technologischem Fortschritt ermöglicht.
Dies ist ein bedeutender Schritt hin zu ethisch verantwortungsvoller KI, die von einer weltweiten Gemeinschaft genutzt und gestaltet wird. Die Entwicklung von OpenThoughts unterstreicht zudem die Bedeutung von Kooperationen zwischen akademischer Forschung, Industrie und Förderinstitutionen wie der Simons Foundation, die das Projekt unterstützt haben. Solche Partnerschaften ermöglichen Ressourcenbündelung und stellen sicher, dass die Forschung nicht isoliert bleibt, sondern praxisnah und innovativ gestaltet wird. Aus heutiger Sicht zeigt OpenThoughts deutlich, dass die Zukunft der Reasoning-Modelle in der Kombination von offenen Daten, sorgfältig orchestrierten Trainingsprozessen und leistungsfähigen Lehrer-Modellen liegt. Die Leistungssteigerung und beeindruckenden Benchmarkergebnisse setzen neue Standards und bieten eine verlässliche Grundlage für die nächste Generation intelligenter Systeme.
Insgesamt stellt OpenThoughts einen Meilenstein in der KI-Entwicklung dar, der Transparenz, Innovation und Leistungsfähigkeit geschickt vereint. Durch die Freigabe von Datensätzen und Modellen wird die Basis gelegt, um Reasoning-Modelle weiter zu verbessern, alltägliche Anwendungen intelligenter und wissenschaftliche Fragestellungen präziser zu machen. Die Reise, die mit OpenThoughts begonnen wurde, steht erst am Anfang – mit der klaren Aussicht, dass KI bald noch tiefer und umfassender denken wird als je zuvor.