CUDA (Compute Unified Device Architecture) von NVIDIA hat die Welt der parallelen Programmierung revolutioniert, indem es Softwareentwicklern direkten Zugriff auf die immense Rechenleistung moderner Grafikprozessoren ermöglicht. Für Entwickler, die mit GPU-basiertem Computing arbeiten möchten, spielen praktische Beispiele und gut dokumentierte Ressourcen eine zentrale Rolle beim Einstieg und bei der Vertiefung ihres Wissens. Ein herausragendes Ressourcenset dazu ist das Repository "cuda_examples" von drkennetz auf GitHub, das eine Vielzahl von CUDA Code-Beispielen inklusive ausführlicher READMEs bereitstellt. Dieses Projekt ist besonders wertvoll, da es nicht nur reine Code-Snippets bietet, sondern die Zusammenhänge, Denkweisen und bewährten Vorgehensweisen beim CUDA-Programmieren vermittelt. Das Repository ist so strukturiert, dass Nutzer gezielt unterschiedliche Aspekte der GPU-Programmierung erlernen können.
Es ist in mehrere Hauptkategorien unterteilt, die jeweils spezifische Themenbereiche abdecken. Zum Beispiel behandelt der Bereich "SetupAndInitExamples" die essenziellen Schritte zu Beginn eines CUDA-Programms – wie das Initialisieren von Geräten und Kontexten –, was grundlegend für ein korrektes Funktionieren der Software ist. Entwickler erhalten hier wertvolle Einsichten, wie man die CUDA-Umgebung richtig vorbereitet und auf gängige Stolperfallen achten kann. Ein anderes bedeutendes Segment ist "MemoryAndStructureExamples", das sich mit Speicheroperationen und der Strukturierung von CUDA-Code beschäftigt. Die effektive Nutzung von GPU-Speicher ist entscheidend für Performance, denn falsch oder ineffizient verwalteter Speicher kann zu Flaschenhälsen und damit zu spürbar schlechterer Ausführungsgeschwindigkeit führen.
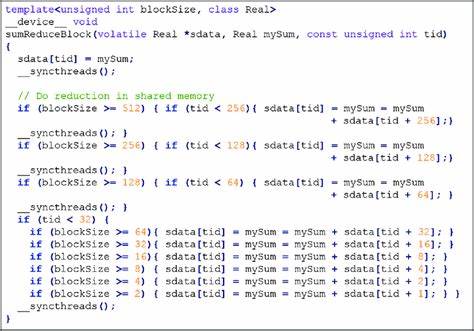
In diesem Bereich finden Entwickler Beispielcode, der zeigt, wie Speicher richtig alloziert, kopiert und synchronisiert wird, und wie der Einsatz von Speicherarten wie Shared Memory oder Managed Memory optimal gestaltet werden kann. Parallel dazu beinhaltet "KernelAndLibExamples" eine Auswahl von CUDA Kerneln und den Einsatz von Kernbibliotheken wie Thrust. Diese Beispiele fokussieren darauf, wie man Berechnungen auf der GPU ausführt, parallelisiert und prototypisch implementiert. Die Beispiele sind praxisnah und bieten eine solide Basis für eigene Projekte, etwa bei Matrixoperationen, Sortieralgorithmen oder anderen rechenintensiven Aufgaben. Darüber hinaus bietet das Repository mit "ProfilingExamples" Werkzeuge und Techniken, um den CUDA-Code zu profilieren und gezielt Performance-Probleme zu identifizieren.
Profiling ist für die GPU-Programmierung unverzichtbar, da es Einblick gibt, wie effizient die Ressourcen genutzt werden und wo Optimierungspotential besteht. Diese Beispiele helfen Entwicklern ihre Programme messbar zu verbessern und das volle Potenzial der Hardware auszuschöpfen. Die Sektion "PerformanceChecklist" rundet das Angebot mit bewährten Methoden ab, um typische Performance-Hürden zu umgehen und CUDA-Programme gezielt zu optimieren. In Kombination mit dem Fokus auf Performance zeigt diese Ressourcensammlung auch den Einsatz moderner C++20-Features. Alle Beispiele sind darauf ausgelegt, mit diesem Standard kompatibel zu sein, was moderne Programmierpraktiken fördert und gleichzeitig eine übersichtliche und klare Programmstruktur unterstützt.
Besonders interessant ist der Ordner "TensorParallelFromScratch", der eine tiefgehende Einführung in Tensor-Parallelismus auf CUDA bietet. Hier folgt man einer Blogserie, die schrittweise zeigt, wie komplexe parallele Algorithmen zum maschinellen Lernen implementiert werden können. Diese Beispiele eröffnen neue Horizonte und zeigen, wie Fachwissen zur parallelen Verarbeitung in der Praxis umgesetzt wird. Ein wichtiger Aspekt des Projekts ist die konsequente Einhaltung von Programmierkonventionen. Jeder Code wird so gestaltet, dass er verständlich und wartbar ist, mit einheitlichen Fehlerbehandlungen, Namenskonventionen und der Nutzung von Hilfsfunktionen wie "cudaCheckError" für eine saubere Fehlerdiagnose.
Dadurch wird nicht nur die Qualität der Beispiele nachhaltig gesichert, sondern auch der Lernprozess der Anwender unterstützt, indem Fehler schnell erkannt und behoben werden können. Die Anleitung zum Bauen und Ausführen der Beispiele ist klar und praxisorientiert formuliert. Entwickler können die Beispielprogramme mit CMake und Makefile-Tools auf verschiedenen CUDA-Architekturen kompilieren, was Flexibilität für unterschiedliche Hardware bietet. Diese ausführlichen Beschreibungen helfen dabei, typische Hürden bei plattformbedingten Anpassungen zu überwinden. Die Offenheit des Projekts für Beiträge macht es darüber hinaus lebendig und zukunftssicher.
Die klar definierten Anforderungen an neue Einreichungen wie Neuartigkeit, Dokumentation und Korrektheit laden Entwickler ein, eigene innovative Beispiele zu teilen, während unnötige Redundanzen vermieden werden. Durch diese kollaborative Arbeitsweise wächst das Angebot stetig und bleibt relevant für die Community. Zusammenfassend ist das "cuda_examples" Repository von drkennetz eine herausragende Ressource für Entwickler, die in die CUDA-Programmierung einsteigen oder ihr Wissen vertiefen wollen. Durch die Vielzahl an gut strukturierten, dokumentierten und praxisnahen Beispielen können Anwender schrittweise wichtige Konzepte und Techniken erlernen. Dieses Angebot unterstützt dabei, die komplexe Welt der GPU-basierten Parallelprogrammierung besser zu verstehen und effektiv anzuwenden.
Ob Anfänger, der erste Programme schreiben möchte, oder erfahrener Entwickler auf der Suche nach neuen Inspirationen und Best Practices – dieses Projekt bietet wertvolle Hilfestellungen, um CUDA-Projekte erfolgreich umzusetzen und dabei Leistungsfähigkeit und Skalierbarkeit maximal auszuschöpfen.