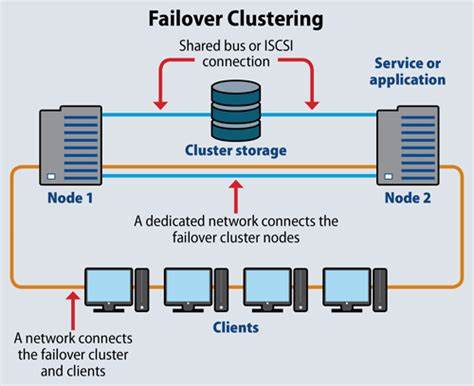
Single-Leader-Datenbanken sind ein zentrales Element moderner Datenbankarchitekturen und werden in zahlreichen Anwendungen eingesetzt, bei denen es auf konsistente und zuverlässige Schreiboperationen ankommt. Das Konzept eines Single-Leader-Systems basiert darauf, dass ein einzelner Knoten, der sogenannte Leader, alle Schreibanfragen verarbeitet, während andere Knoten – die Follower – die Daten replizieren und hauptsächlich Leseanfragen bedienen. Diese Architektur hilft dabei, die Last zwischen den Knoten zu verteilen und gleichzeitig eine konsistente Datenbasis aufrechtzuerhalten. Doch wie bei allen verteilten Systemen ist auch hier die Ausfallsicherheit essenziell. Ein zentrales Element der Ausfallsicherheit ist das sogenannte Failover, also der automatische Wechsel zu einem Backup-System, wenn der aktuelle Leader oder ein Follower ausfällt.
Nur durch ein robustes Failover-Management kann gewährleistet werden, dass Datenverluste minimiert und Systemunterbrechungen möglichst vermieden werden. Im Folgenden wird erläutert, wie Failover-Mechanismen in Single-Leader-Datenbanken organisiert und umgesetzt werden und welche Herausforderungen dabei besonders zu beachten sind. Das Herzstück eines Single-Leader-Systems bildet der Leader-Knoten, der sämtliche Schreiboperationen entgegennimmt und in einem lokalen Protokoll, auch Log genannt, abspeichert. Dieses Log enthält eine chronologisch geordnete Liste aller Schreibvorgänge und bildet die Grundlage für die Replikation. Follower-Knoten übernehmen diese Einträge und wenden sie in derselben Reihenfolge an, um ihre Datenbanken konsistent mit dem Leader zu halten.
Dieses Vorgehen stellt sicher, dass alle Knoten auf demselben Stand sind, was auch als eventual consistency bezeichnet wird. Falls der Leader ausfällt, steht zunächst kein weiterer Knoten bereit, um Schreibanfragen zu bedienen, was zum Stillstand des Systems führen kann. Daher ist es essenziell, dass ein automatischer und schneller Failover-Prozess implementiert wird. Im Fall eines Follower-Ausfalls ist die Situation vergleichsweise unkompliziert. Da Follower nur Leseanfragen bearbeiten und keine eigenen Schreibvorgänge durchführen, kann ihr Ausfall kurzfristig toleriert werden, ohne den Betrieb ernsthaft zu beeinträchtigen.
Das System erkennt meist durch regelmäßige Herzschläge oder Health-Checks, ob ein Follower noch verfügbar ist. Sobald eine Antwort ausbleibt, wird dieser Knoten entweder temporär oder dauerhaft aus der aktiven Liste entfernt und Anfragen werden an andere verfügbare Follower oder direkt an den Leader umgeleitet. Befindet sich ein ausgefallener Follower im Wiederanlauf, wird er typischerweise zunächst mit einem Snapshot des aktuellen Datenbestands des Leaders versorgt. Anschließend werden ihm alle Änderungen aus dem Log übermittelt, die seit dem Zeitpunkt des Snapshots erfolgt sind, damit er schnell wieder auf dem neuesten Stand ist und nahtlos am Replikationsprozess teilnehmen kann. Diese Wiederherstellung ist zwar zeitaufwendig, stellt aber sicher, dass Konsistenz zwischen Leader und Follower gewährleistet wird.
Die Herausforderung beim Follower-Failover liegt vor allem in einer möglichen temporären Reduzierung der Ausfallsicherheit. Solange ein Follower nicht vollständig synchronisiert ist, stehen weniger Replikate zur Verfügung, was die Belastung auf die verbleibenden Follower erhöht und die Datenredundanz verringert. Deshalb ist es wichtig, dass die Überwachung und Wiederherstellung von Followern möglichst schnell und automatisiert erfolgen, um das Risiko von Engpässen zu minimieren. Gravierender gestaltet sich die Situation jedoch bei einem Ausfall des Leaders. Da der Leader der einzige Knoten ist, der Schreibanfragen entgegennimmt, führt sein Ausfall unmittelbar zu einem Stillstand der Schreibvorgänge im System.
Das Ziel des Failovers ist es in diesem Fall, so schnell wie möglich einen neuen Leader zu bestimmen und diesen in der Rolle zu bestätigen, damit der Betrieb zügig fortgesetzt werden kann. Die Erkennung eines Leader-Ausfalls erfolgt ebenfalls durch die Überwachung mittels Herzschlägen oder anderen Health-Checks. Sobald diese zeigen, dass der Leader über einen definierten Zeitraum nicht erreichbar ist, wird sein Ausfall angenommen. Die Auswahl eines neuen Leaders ist ein kritischer Schritt, der sorgfältig durchgeführt werden muss, um Datenverlust zu vermeiden. In der Regel wird der Follower mit dem aktuellsten Log-Stand ausgewählt, also derjenige, der am wenigsten Daten gegenüber dem alten Leader verloren hat.
Dies minimiert die Gefahr, dass bestätigte Schreibvorgänge verloren gehen. Die Leader-Wahl wird häufig durch verteilte Konsensprotokolle wie Raft oder Paxos gesteuert, die sicherstellen, dass alle Knoten eine einheitliche Entscheidung treffen und verhindern, dass zwei Leader gleichzeitig aktiv sind, was zu Inkonsistenzen führen könnte. Der Übergang zu einem neuen Leader umfasst auch eine Neukonfiguration des Systems. Die Clients müssen über die neue Führungsrolle informiert werden, damit sie ihre Schreibanfragen korrekt weiterleiten. Ebenso müssen die verbleibenden Follower wissen, welchem Knoten sie zukünftig folgen, also von welchem Leader sie ihre Updates erhalten.
Diese Umstellung erfolgt meist automatisiert, erfordert jedoch eine gut koordinierte Kommunikation, um Unterbrechungen zu minimieren. Es gibt zwei grundlegende Arten von Leader-Failover: den geplanten (graceful) und den ungeplanten (emergency) Failover. Beim geplanten Failover wird die Führungsrolle gezielt an einen ausgewählten Follower übergeben, bevor der aktuelle Leader heruntergefahren wird. Dabei stellt der Leader sicher, dass alle ausstehenden Schreibvorgänge abgeschlossen und der ausgewählte Follower vollständig synchronisiert ist. Dies ermöglicht einen nahtlosen Wechsel ohne Datenverluste und ohne nennenswerte Ausfallzeiten.
Im Gegensatz dazu liegt beim ungeplanten Failover oft ein plötzlicher Ausfall aufgrund von Hardwarefehlern, Netzwerkausfällen oder Softwareabstürzen vor. In diesem Fall muss die Wahl des neuen Leaders automatisch und schnell erfolgen, um den Ausfall zu kompensieren. Da der alte Leader möglicherweise später zurückkehrt, wird er in der Regel als Follower re-integriert, um den Konflikt von zwei aktiven Leadern zu verhindern. Bei der Notfall-Wahl muss besonders darauf geachtet werden, dass die Datenkonsistenz gewahrt bleibt und keine Inseln (Split-Brain-Situationen) entstehen. Die geographische Verteilung der Knoten in modernen verteilten Systemen beeinflusst den Failover-Prozess zusätzlich.
Optimalerweise sollte der neue Leader möglichst nahe am Großteil der Clients oder im selben Rechenzentrum wie der vorherige Leader sein, um Latenzen gering zu halten und die Performance zu optimieren. Dennoch hat die Datenaktualität oberste Priorität bei der Leader-Wahl, was dazu führen kann, dass ein weiter entfernt liegender Knoten die Führungsposition übernimmt, wenn er als einziger vollständig synchron ist. Abschließend ist festzuhalten, dass Failover-Mechanismen in Single-Leader-Datenbanksystemen essenziell für die Gewährleistung von Hochverfügbarkeit und Datenkonsistenz sind. Ein robustes Monitoring, schnelle Erkennung von Ausfällen und effiziente Wiederherstellungsprozesse aller Knoten – sowohl Leader als auch Follower – sind dabei unverzichtbar. Die Kombination aus diesen Technologien und Prozessen stellt sicher, dass Systeme auch bei Ausfällen weiter funktionsfähig bleiben und Nutzer nahtlos auf Daten zugreifen können, ohne merkbare Unterbrechungen oder Datenverluste hinnehmen zu müssen.
Entwickler und Systemarchitekten müssen daher besonderes Augenmerk auf die Gestaltung und Implementierung dieser Failover-Strategien legen, um den hohen Anforderungen moderner Anwendungen gerecht zu werden.