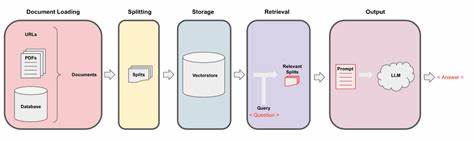
Die rasante Entwicklung im Bereich der Künstlichen Intelligenz (KI) sowie der Natural Language Processing (NLP)-Technologien hat in den letzten Jahren immer wieder neue Herausforderungen und Chancen mit sich gebracht. Besonders im Fokus stehen dabei Systeme, die menschliche Fragen verstehen und präzise beantworten können. Dazu zählen insbesondere Web-Browsing-Agenten, die Informationen eigenständig aus dem Internet suchen und extrahieren, sowie sogenannte Retrieval-Augmented Generation (RAG) Systeme, die externes Wissen aus Dokumentenbanken abrufen und kontextualisierte Antworten generieren. Um diese Systeme sinnvoll testen und weiterentwickeln zu können, benötigt man hochwertige und umfangreiche Datensätze. WikipeQA ist ein solcher Evaluationsdatensatz, der speziell darauf ausgelegt ist, sowohl Web-Browsing-Agenten als auch RAG-Systeme zu bewerten und ihre Effizienz in der Frage-Antwort-Verarbeitung zu steigern.
WikipeQA zeichnet sich durch eine Sammlung von Fragen und dazugehörigen, häufig komplexen Antworten aus, die aufgrund ihrer Vielfalt und Realitätsnähe eine ideale Testumgebung bieten. Die meisten enthaltenen Fragen beziehen sich auf allgemeines Wissen, ähnlich wie es bei Suchmaschinenanfragen oder virtuellen Assistenten der Fall ist. Sie wurden so gestaltet, dass sie sowohl einfache Faktenermittlungen als auch komplexere semantische Herausforderungen abbilden. Die Antworten stammen aus verlässlichen Quellen und sind oft längere Textabschnitte, was vor allem für RAG-Systeme relevant ist, da diese typischerweise umfangreiche Dokumente bei der Antwortgenerierung verarbeiten müssen. Der Aufbau des WikipeQA-Datensatzes ermöglicht es Forschern, verschiedene Algorithmen und Modelle präzise gegeneinander zu vergleichen.
Durch die Aufbereitung in leicht zugänglichen Formaten, unter anderem auch in Parquet-Dateien, lässt sich das Dataset effizient in unterschiedlichen Programmierumgebungen und mit verschiedenen Data-Science-Tools einsetzen. In vielen Fällen unterstützt WikipeQA zudem die Nutzung beliebter Softwarebibliotheken wie pandas oder speziell zugeschnittene NLP-Frameworks, was die Integration in bestehende Projektpipelines vereinfacht. Ein besonders wertvoller Aspekt von WikipeQA ist seine Eignung für die Evaluierung von Retrieval-Modulen in RAG-Systemen. Diese Hybrid-Systeme kombinieren das Abrufen relevanter Dokumente mittels Information Retrieval mit der Fähigkeit, kontextuell sinnvolle, flüssige und inhaltlich präzise Antworten zu generieren. Um hier optimale Resultate zu erzielen, sind Tests mit echten Frage-Antwort-Paaren, die natürlichen Suchverhalten entsprechen, ausschlaggebend.
WikipeQA bietet diese Grundlage und fördert damit die Entwicklung von Systemen, die in der Praxis weit über einfache Stichwortabgleiche hinausgehen können. Darüber hinaus unterstützt der Datensatz auch das Training und die Validierung moderner Web-Browsing-Agenten. Diese Agenten sind darauf ausgelegt, aktiv im Web zu surfen, Informationen quer über verschiedene Webseiten zu aggregieren und kontextbezogene Antworten zu formulieren. Im Gegensatz zu rein datenbankgestützten Modellen simulieren sie das menschliche Suchverhalten und müssen daher mit realistischen, dynamischen Fragestellungen umgehen können. WikipeQA greift genau dieses Szenario auf, was ihn im Bereich der KI-Entwicklung besonders beliebt macht.
Die Qualität eines Evaluationsdatensatzes ist maßgeblich dafür verantwortlich, wie gut die trainierten Modelle und Agenten im echten Einsatz funktionieren. Hier punktet WikipeQA mit einer breiten Fragestellung, einem hohen Anspruch an die Antwortqualität und einer sorgfältigen Aufbereitung der Daten. So sind etwa die durchschnittlichen Längen der Fragen und Antworten gut dokumentiert, was bei der Modellierung von Textlängen und der Optimierung von Antwortgenauigkeit behilflich ist. Die Vielfalt an Themen und Wortklassen gewährleistet außerdem, dass Systeme nicht nur auf eng umrissenen Fachgebieten trainiert werden, sondern auch bei allgemeinen und unerwarteten Anfragen bestehen können. Auch aus rechtlicher Sicht ist die Verwendung von WikipeQA unkompliziert, da der Datensatz unter einer MIT-Lizenz verfügbar ist.
Dies erleichtert die Nutzung in Forschungsprojekten, kommerziellen Anwendungen und Open-Source-Entwicklungen gleichermaßen. Eine starke Community um den Datensatz sorgt zudem für einen regen Austausch, Verbesserungsvorschläge und erweitert ständig die Einsatzmöglichkeiten. Durch seine Anbindung an moderne KI-Libraries und Data-Science-Umgebungen wie etwa Croissant oder pandas ermöglicht WikipeQA nicht nur die Evaluation bestehender Systeme, sondern auch die Entwicklung neuartiger Algorithmen, die auf fortschrittlichen Machine-Learning-Methoden basieren. Dabei können Wissenschaftler Angebote verschiedener Frameworks und Sprachen kombinieren, um die Stärken unterschiedlicher Technologien zu nutzen. In der direkten Anwendung hilft WikipeQA dabei, Schwachstellen bestehender Systeme zu identifizieren.
Etwa können damit Fragen konstruiert werden, bei denen der Informationshintergrund besonders komplex ist oder die notwendige Kontextualisierung der Antwort hohen Anforderungen unterliegt. So lässt sich gezielt daran arbeiten, sowohl inhaltliche als auch semantische Fehler in den Modellen zu vermeiden. Dies trägt insgesamt dazu bei, dass Endanwender etwa bei der Verwendung von Chatbots, Suchmaschinen oder digitalen Assistenten qualitative und verlässliche Informationen erhalten. Abschließend ist es wichtig zu betonen, dass WikipeQA nicht nur für einzelne Forschungszwecke interessant ist, sondern eine nachhaltige Grundlage darstellt, die die Entwicklung smarter Systeme im Bereich des automatischen Wissensabrufs und der textbasierten Kommunikation befördert. In Zeiten steigender Anforderungen an KI-Systeme in Alltag, Wirtschaft und Wissenschaft stellt ein solcher Datensatz einen wichtigen Eckpfeiler dar, um die innovativen Technologien von morgen schon heute praxisnah zu evaluieren und gezielt zu verbessern.
Die sorgfältige Kuratierung, die breite Abdeckung von Themen und die gute Schnittstellenfreundlichkeit machen WikipeQA zu einem unverzichtbaren Werkzeug für Entwickler, Forscher und Unternehmen, die effiziente und intelligente Antwortsysteme schaffen wollen.


![Eidophor: 1950's space age video projection technology. [video]](/images/355D98C7-1AE8-4227-A4D4-95C22C5923EB)