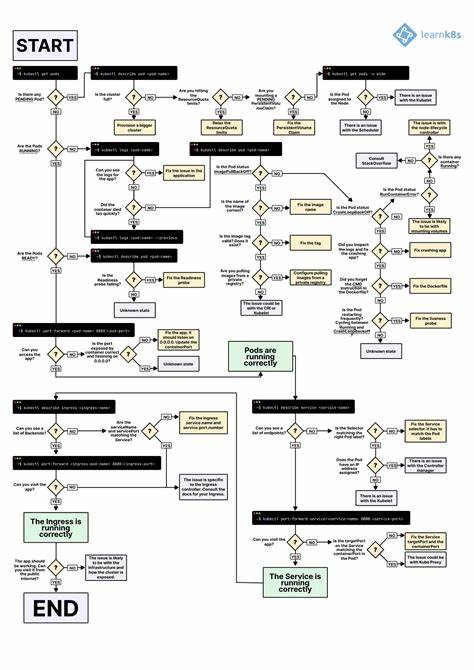
Kubernetes hat sich als das führende Container-Orchestrierungstool etabliert, das Unternehmen dabei unterstützt, Anwendungen in großem Maßstab effizient zu verwalten und zu skalieren. Trotz seiner Leistungsfähigkeit können komplexe Kubernetes-Cluster mit zahlreichen Komponenten und Abhängigkeiten anfällig für verschiedenste Fehler und Herausforderungen sein. Ein strukturiertes Troubleshooting ist daher essenziell, um die Stabilität, Sicherheit und Performance des Clusters zu gewährleisten. Viele Profis im DevOps-Bereich stoßen auf alltägliche und seltene Probleme, die sich durch gezielte Diagnose- und Lösungsstrategien beheben lassen. Ein umfangreicher, gut organisierter Troubleshooting-Guide trägt dazu bei, schneller Ursachen zu identifizieren und Wiederholungsfehler zu vermeiden.
Ein häufiger Stolperstein ist das Draining und Rejoining von Nodes. Beispielsweise kann ein Pod durch einen fehlerhaften oder hängen gebliebenen Finalizer das Abschalten eines Nodes blockieren. In einem solchen Fall bleibt der Node „in Drain“, da der Kubernetes-API-Server auf das Entfernen des Finalizers wartet, der aber aufgrund eines abgestürzten Controllers nicht ausgeführt wird. Die Lösung liegt oft im manuellen Entfernen der Finalizer mittels `kubectl patch` Befehl. Dieses Beispiel zeigt, wie wichtig es ist, die Logdateien und Controller-Status genau zu prüfen, um die Blockade zu beheben.
Kritisch ist auch die Stabilität der API Server, die durch Überlastung mit Custom Resource Definitions (CRDs) und entsprechenden Objekten in die Knie gehen können. Ein Controller, der unkontrolliert unzählige CRDs erzeugt etwa in einem Reconcile-Loop, führt nicht selten zu Belastungsspitzen, die sich in Timeout-Fehlern nieder schlagen. Die Überwachung der Anzahl der CRDs, das Einrichten von Alerts bei kritischen Werten, sowie das sorgfältige Testen von Controller-Logik in Testumgebungen sind Präventionsmaßnahmen, die Organisationen empfehlen sollten. Die Konsistenz und Verfügbarkeit von Knoten durch korrekte Kubelet-Konfiguration ist ein weiterer wesentlicher Aspekt. Ein bekanntes Problem besteht darin, dass nach einem Neustart oder Kernel-Update ein Node nicht wieder dem Cluster beitritt, weil sich die Hostnamen geändert haben oder sich die Identität des Kubelets nicht mit dem in der Clustermanagement-Datenbank gespeicherten Original abstimmt.
Die Folge sind Registrierungsschwierigkeiten und ein fehlender Node im Cluster. Hier hilft die Verwendung von konstante Hostnamen, korrekte Einstellungen im `--hostname-override` Flag und die Bereinigung veralteter Knoten-Einträge. Storage-Probleme können tiefgreifende Auswirkungen haben. Etcd, die Datenbank, die den Clusterzustand speichert, reagiert beispielsweise äußerst sensibel auf nahezu volle Festplatten. Eine ungenügende automatische Kompaktion und Snapshot-Pflege führt zum Loslaufen von Datensättigung, mit anschließendem Ausfall des API-Servers.
Neben der erhöhten Überwachungswichtigkeit von etcd-Speichern sollte die Planung von Backup- und Restaurationsstrategien nicht vernachlässigt werden. Unvollständige Backups, die etwa PVCs oder Secrets ausschließen, können nach einem Restore zu inkonsistentem Clusterzustand und Dienstunterbrechungen führen. Im Bereich Netzwerk ist die Konfiguration von Taints und Tolerations ein wiederkehrendes Problem. Unangebrachte oder falsch eingesetzte Node-Taints können dazu führen, dass wichtige Pods nicht geplant werden, da ihnen die passenden Tolerations fehlen. Ebenso verursacht ein Missmatch bei Netzwerkplugins, IP-Kollisionen oder MTU-Abweichungen häufig schwer diagnostizierbare Konnektivitätsprobleme.
Insbesondere die Wahl und Konfiguration der CNI-Plugins sollten wohlüberlegt sein, da Netzwerktraffik, Policies und DNS-Auflösung stark beeinträchtigt werden können. Die Nutzung von Network Policies ist ein mächtiges Mittel zur Absicherung, jedoch müssen sie präzise konfiguriert werden, um keine unerwarteten Kommunikationsblockaden zwischen Pods zu verursachen. Die Sicherheit in Kubernetes verdient besondere Aufmerksamkeit, da eine falsch konfigurierte RBAC-Policy, zu leichtfertig eingestellte Pod-Sicherheitskontexte oder exponierte Dashboard-Zugänge schnell zu gravierenden Vorfällen führen können. Ein bekanntes Szenario ist die versehentliche Offenlegung von Secrets in Logs oder Umgebungsvariablen, die von unbefugten Parteien abgerufen werden können. Prinzipien wie die geringste Privilegienvergabe, konsequentes Monitoring von Audit-Logs und die verabschiedete Verwendung von Pod Security Policies (bzw.
deren Nachfolger, Pod Security Admission) sind grundlegende Mittel, um diese Risiken zu minimieren. Darüber hinaus sollten jede Änderung, die die API-Server-Konfiguration oder Webhook-Authentifizierung betrifft, mit besonderer Sorgfalt gehandhabt werden, um Ausfälle oder Sicherheitslücken zu vermeiden. Automatisierte Skalierung mittels Horizontal Pod Autoscalern (HPA) und Cluster Autoscalern ist eine Kernfunktionalität von Kubernetes, die aber durch falsche Konfigurationen leicht aus dem Ruder laufen kann. Ursachen für fehlerhaftes Verhalten sind oft mangelhafte Metriken, unzureichend definierte Ressourcenanforderungen oder Konflikte zwischen Skalierungsstrategien wie HPA und Vertical Pod Autoscaler (VPA). Auch müssen Regeln für Probes und Policies so eingerichtet sein, dass sie das System nicht unnötig blockieren oder vorzeitig skalen lassen.
Beispielsweise kann eine zu aggressive Scale-Down-Policy zu Ressourcenschwankungen und Instabilität führen. Durch das gezielte Monitoring, das Verwenden passender Metriken (CPU, Memory, benutzerdefinierte Metriken) und die Parametrierung von Stabilitätsintervallen lässt sich das Skalierungsverhalten optimieren. Storage-bezogene Herausforderungen reichen von Problemen mit PersistentVolumeClaims (PVC) bis hin zu tiefergehenden Komplikationen mit CSI-Plugins. Nicht wenige Fehlerquellen sind in unzureichendem Verständnis der Speichermodi zu finden: So dürfen etwa ReadWriteOnce-Volumes nicht gleichzeitig von mehreren Nodes eingehängt werden. Auch das manuelle Löschen von Knoten ohne sauberes Volumen-Detach kann dazu führen, dass PVCs in einem hängenden Status verbleiben, was wiederum neue Pod-Schedule-Prozesse blockiert.
Ein weiteres typisches Verhalten ist die verzögerte oder fehlerhafte Volume-Filesystem-Erweiterung bei PVC-Resize-Operationen, die abhängig vom CSI-Plugin oftmals einen Pod-Neustart bedingen. Die Vielzahl der beschriebenen Szenarien macht klar, dass ein ganzheitlicher Blick beim Kubernetes-Troubleshooting nötig ist. Dabei helfen systematische Diagnosen mit Log-Analysen, Statusbefehlen, Monitoring-Tools und Fehler-Reproduktionsumgebungen. Die Implementierung von Awareness-Prozessen zur Vermeidung bekannter Fehler, die Investition in umfangreiche Alertsysteme und der Erfahrungsaustausch innerhalb der Community runden die Strategie ab. Ein Open-Source-ähnliches Troubleshooting-Repository, in dem praxisrelevante Szenarien mit Diagnose und Lösungen gesammelt sind, bietet eine wertvolle Grundlage.