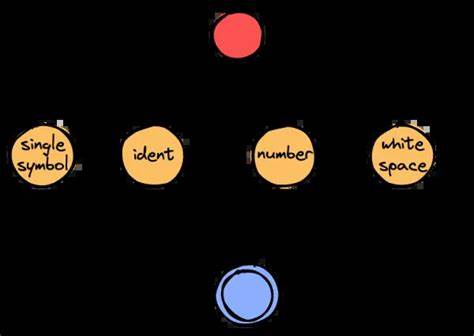
Die Verarbeitung von Quellcode im Compiler ist ein essenzieller Schritt, der maßgeblich die Geschwindigkeit und Effizienz der gesamten Sprachverarbeitung beeinflusst. In Rust gibt es mit dem Logos-Crate einen weit verbreiteten und hochentwickelten Lexer-Generator, der zwei Hauptziele verfolgt: Zum einen die einfache Erstellung von Lexern für Entwickler, zum anderen die Erzeugung besonders schneller Lexer, die mit handgeschriebenem Code konkurrieren können. Doch wie gut schlägt sich der bekannte Lexer-Generator wirklich im direkten Vergleich mit einer handgefertigten Implementierung? Eine genaue Analyse zeigt überraschende Erkenntnisse über lexikalische Analyse, CPU-Architekturen und Optimierungsansätze für die Zukunft. Logos setzt bei seiner Geschwindigkeit vor allem auf einen zustandsbasierten Automaten, der mittels Sprungtabellen arbeitet. Diese Jump-Table-Ansätze sind in vielen Lexer-Generatoren beliebt, da sie den Status des Automaten durch direkte Indizierung über Zeichen schnell verändern können.
Jedes Token ist dabei ein Zustand, der Übergänge für verschiedene Zeichen definiert. Für ASCII-Eingaben werden komplette Sprungtabellen für jeden möglichen Bytewert verwendet, wodurch jeder Übergang mit einer einfachen Lookup-Operation erfolgen kann. Für vollwertige UTF-8 Eingaben müssen oft kompliziertere, verzweigte Funktionen zum Unicode-Switch eingesetzt werden, um korrekt zu verarbeiten. Dies führt zu einer komplexeren Ablaufsteuerung und potenziell langsameren Verarbeitung. Für Entwickler, die einen eigenen Lexer schreiben, ergeben sich hier grundsätzliche Herausforderungen: Einerseits will man den Lexer möglichst generisch halten, damit er flexibel für verschiedene Sprachdefinitionen passt.
Andererseits bringt hohe Generalität häufig Leistungsnachteile mit sich, da Optimierungen durch den Lexer-Generator bei spezifischen Daten nicht immer greifen can. Dies führte dazu, dass manche handerstellte Lexervarianten trotz ihres vermeintlichen Handarbeitsnachteils in bestimmten Aspekten schneller agieren konnten. Ein wichtiger Aspekt für die Geschwindigkeit liegt in der Erkennung von Schlüsselwörtern. Das Vergleichen vieler möglicher Schlüsselwörter ist für Compiler oft ein Performance-Killer, deshalb werden hier häufig perfekte Hash-Funktionen verwendet, die speziell für eine fixe Menge an Wörtern optimiert sind. Diese Hashing-Methoden erzeugen eine perfekte Zuordnung, bei der jedes Schlüsselwort eindeutig und konfliktfrei identifiziert wird.
Das Ergebnis ist ein extrem schneller Zugang und Vergleich mit minimalen Rechenoperationen. Im beschriebenen Projekt konnte der Autor feststellen, dass sich alle Schlüsselwörter auf maximal acht Bytes begrenzen ließen, was bedeutet, dass sie problemlos in 64-Bit-Register passen. Dadurch sind Vergleiche äußerst effizient: Ein einzelner Vergleich im Prozessor genügt, um eine Übereinstimmung zu erkennen. Die naiv wirkende handgefertigte Variante, die perfekt optimierte Hash-Funktionen verwendet, gelang schon hier einen Geschwindigkeitsvorteil gegenüber Logos auf bestimmten Architekturtypen, insbesondere auf ARM-basierten Systemen wie dem Apple M1. Interessant war auch die Beobachtung, dass sich die Performance bei Verwendung von Inline-Erweiterungen verbessern ließ.
Das vollständige Inline-Anbringen von Funktionen verbesserte die Geschwindigkeit des eigenen Lexers um rund 30 Prozent. Dies lässt sich dadurch erklären, dass bessere Inlining-Möglichkeiten der CPU helfen, den Code effizienter vorzubereiten und vermeidet häufige Funktionsaufrufe mit ihren Kosten. Ein weiterer Pluspunkt gegenüber Logos war, dass durch Entfernung bestimmter Logik, wie beispielsweise Pufferungen mit "Peeked"-Token oder textuellen Verweisen in Tokenstrukturen, die Cache-Nutzung optimiert werden konnte. Der dadurch resultierende Rückstand auf Logos schrumpfte auf lediglich rund 25 Prozent, was bei einigen Anwendungen bereits eine sehr akzeptable Differenz darstellt. Neben solchen strukturellen Änderungen ergab sich ein weiterer Optimierungsspielraum aus der gezielten Nutzung von ASCII-Dispatch.
Quellcode besteht bekanntermaßen überwiegend aus ASCII-Zeichen, was für die Mehrzahl heutiger Programmiersprachen gilt. Auf Basis der Analyse zahlreicher Codebasen mit Millionen von Quellzeilen wurde festgestellt, dass die ASCII-Quote bei über 99,9 Prozent liegt. Dies erlaubt eine vorsichtige Annahme, die im Code ausgenutzt werden kann: Ist das Eingabesequenzzeichen nicht ASCII, kann auf eine langsame Erfassung ausgewichen werden, ansonsten wird ein stark optimierter Pfad für ASCII-Daten genutzt. Solches Branching ermöglicht effiziente Vektoroperationen ohne unnötige Abfragen. Noch weiter in die Leistungssteigerung geht die Nutzung moderner SIMD-Instruktionen, speziell auf ARM-Architekturen, wo NEON-Intrinsics zur Verfügung stehen.
Diese ermöglichen das parallele Verarbeiten von 16 Bytes in einem einzigen Register und damit eine massive Beschleunigung für schnelle Lookup-Tabellen. Neben simplen Buchstaben- und Digitenerkennung wurde eine neue Methode entworfen, bei der alphanumerische, numerische und Leerzeichen in verschiedene Kategorien zusammengeführt werden. Dadurch wird der Zustand eines Automaten deutlich vereinfacht, indem mehrere Einzelchecks durch Vergleiche gegen vordefinierte Werte ersetzt werden können, die dann in Schleifen leicht abzuarbeiten sind. Die sogenannte "Skip Loop" fungiert dabei als eine Art einfacher Zustandsautomat, bei dem bestimmte Folgezeichen als erlaubte Fortsetzung eines Tokens bewertet werden. Zugehörige Übergänge und Abbrüche lassen sich mit einfachen Vergleichen realisieren, was die Kontrollflusskosten reduziert und potentielle Datenabhängigkeiten durchschaubar macht.
Die Vorhersagbarkeit von Verzweigungen bei typischen Token wie Leerzeichen oder Bezeichnern ist hoch, wodurch Branch-Prediction-Optimierungen von CPUs gute Arbeit leisten können. Insgesamt führte diese moderat die Komplexität erhöhende Herangehensweise zu Leistungsvorteilen von rund 35 Prozent gegenüber Logos, gemessen in typischen Benchmark-Durchläufen auf einem Apple M1. Diese Einsparungen sind vor allem durch bessere Nutzung von CPU-Architektureigenschaften und die Vereinfachung der Zustandsübergänge zu erklären. Zusätzlich wurde die Performance von Keyword-Matching noch genauer untersucht. Statt komplexer arithmetischer Hash-Funktionen wurde die Anwendung einfacher Lookup-Tabellen mit voreingestellten Bitmasken ausprobiert, um unverwen-dete Bytes zu nullen.
Das überraschende Ergebnis: Die Lookup-Tabellen waren schneller als aufwändige Bit-Extraktionen, zumindest messbar im Bereich von 5 bis 10 Prozent Beschleunigung in der Keyword-Erkennung. Obwohl Keywords in realen Daten seltener sind, ist das ein interessantes Detail, das weitere Quellen für Optimierungen eröffnet. Das endgültige Benchmark mit realistischeren und komplexeren Daten, beispielsweise längeren Identifiern mit Unterstrichen und verschieden langen Leerzeichen, zeigt zwar eine Verlangsamung der relativen Vorteile gegenüber Logos, aber es bleibt eine konstante Beschleunigung von 20 bis 30 Prozent bestehen. Diese Resultate heben hervor, dass trotz wachsender Komplexität die Kernansätze der Optimierung Bestand haben. Im Fazit offenbaren sich mehrere wichtige Erkenntnisse für die Compilerentwicklung und insbesondere das Lexer-Design in Rust.
Ein maßgeschneiderter Lexer, der gezielt die Eigenschaften moderner CPU-Architekturen und das typische Datenverhalten bei Quellcode nutzt, kann einen prominenten und als schnell geltenden Lexer-Generator wie Logos schlagen. Dies gilt besonders auf ARM-basierten Systemen, die mit vorausschauender Ausführung und spezieller SIMD-Unterstützung beste Voraussetzungen für solche optimierten Algorithmen bieten. Zukünftige Untersuchungen könnten sich darauf konzentrieren, wie sich diese schnelleren Lexing-Methoden in Kombination mit par-sing-Code verhalten, bei dem Lexer-Aufrufe stark verflochten sind. Hier könnten Inline-Strategien und Vorhersagemechanismen noch mehr Vorteile bringen. Zudem lohnt es sich, die verwendeten perfekten Hash-Funktionen weiter zu verfeinern und eventuell plattformspezifische Instruktionen besser zu nutzen.
Die Ergebnisse zeigen, dass handgefertigte Lösungen trotz bestehender Generatoren mit voller Struktur und Flexibilität wichtige Vorteile erzielen können. Rust-Entwickler und Compilerforscher sind damit motiviert, bestehende Tools kritisch zu hinterfragen und durch innovative Algorithmen nachhaltige Verbesserungen zu erzielen. Die Zukunft der Quellcodeaufbereitung könnte so mit noch effizienteren und besser auf heutige Hardware abgestimmten Lexer-Komponenten gestaltet werden – was nicht nur die Compilerbeschleunigung vorantreibt, sondern auch die Entwicklung moderner Programmiersprachen nachhaltiger unterstützt.