Große Sprachmodelle (Large Language Models, LLMs) erfreuen sich seit Jahren wachsender Beliebtheit und finden vielfältige Anwendung in der automatischen Texterstellung, Übersetzung oder als Assistenzsysteme. Trotz ihrer beeindruckenden Fähigkeiten bringen sie jedoch Herausforderungen mit sich, insbesondere im Bereich der Effizienz bei der Textgenerierung. Eine zentrale Technik zur Optimierung dieses Prozesses ist der Einsatz des KV Caches – ein Mechanismus zur Zwischenspeicherung von Schlüssel- und Wertvektoren im Self-Attention-Mechanismus. Dieses System minimiert redundante Berechnungen während der Token-Generierung und führt zu einer signifikanten Beschleunigung. Im Folgenden wird dieses Konzept ausführlich erläutert, seine Funktionsweise verständlich gemacht und ein praxisnaher Programmieransatz vorgestellt, der auf den Grundlagen von PyTorch basiert und speziell für den Gebrauch in LLMs ausgelegt ist.
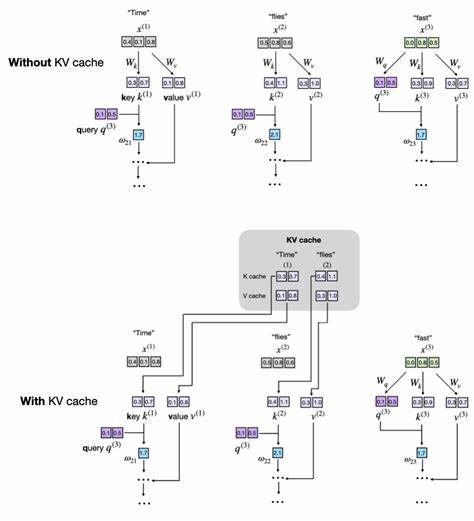
LLMs generieren Text in der Regel sequenziell, das heißt, sie produzieren Wort für Wort einen Satz oder eine Passage. Für jede neue Token-Generierung verarbeitet das Modell typischerweise die gesamte bisherige Token-Sequenz erneut durch alle Transformerschichten, einschließlich der Berechnung komplexer Attention-Mechanismen. Genau hier entsteht das Hauptproblem: Je länger die Sequenz, desto höher der Rechenaufwand. Im Detail bedeutet das, dass bei jedem Schritt für alle bisher generierten Tokens die sogenannten Schlüssel- und Wert-Vektoren im Attention-Mechanismus erneut berechnet werden. Dieser Vorgang ist redundant und ineffizient, da sich die Schlüssel- und Wertvektoren vorheriger Tokens nicht ändern, sondern immer gleich bleiben.
Der KV Cache ist eine clevere Lösung, die genau diese Wiederholungen vermeidet. Dabei werden die Schlüssel- und Wert-Vektoren, die während der Generierung eines Tokens entstehen, im Cache gespeichert und bei der nächsten Token-Generierung wiederverwendet. Das Resultat ist ein drastisch reduzierter Rechenaufwand für die Berechnung der Aufmerksamkeit, da nun nur noch die neu hinzukommenden Token berechnet werden müssen. Stark vereinfacht kann man sagen, dass bei der Generierung des n-ten Tokens nur noch für diesen neuen Token die Schlüssel- und Wert-Vektoren berechnet werden, während alle vorherigen entspannt aus dem Cache gelesen werden. Diese Technik zahlt sich besonders bei längeren Texten und großen Modellen aus, da die Rechenkomplexität der Attention von quadratisch auf linear im Bezug auf die Sequenzlänge reduziert wird.
Allerdings bringt das KV-Caching auch Nachteile mit sich, vor allem einen deutlich erhöhten Speicherverbrauch, da die Schlüssel- und Wert-Vektoren aller bisherigen Tokens gespeichert werden müssen. Bei extrem langen Textsequenzen kann dies zu Speicherproblemen führen. Daher erfordern praktische Implementierungen oft Mechanismen, um die Größe des Caches zu begrenzen oder zu verwalten, zum Beispiel mittels eines sogenannten Sliding Windows, bei dem nur die zuletzt verwendeten Tokens im Cache bleiben. Aus konzeptioneller Sicht gliedert sich der KV Cache in zwei wesentliche Funktionen: das Speichern neuer Schlüssel- und Wert-Vektoren im Cache und die darauf folgende effiziente Wiederverwendung dieser Daten während der Inferenz. Um diese Idee zu verstehen, lohnt sich der Blick auf den Self-Attention-Mechanismus, das Herzstück aller Transformer-basierten LLMs.
Dieser Prozess erzeugt für jede Eingabe-Token einen Query, einen Key und einen Value. Die Aufmerksamkeit wird berechnet, indem anhand der Query-Vektoren die relevanten Keys gefunden und dann die zugehörigen Values gewichtet und aggregiert werden. In einer typischen Implementierung ohne KV Cache werden bei jedem neuen Token alle Queries, Keys und Values erneut berechnet – eine aufwändige Operation. Der KV Cache setzt hier an, indem er Key- und Value-Matrizen aus vorherigen Schritten speichert und lediglich die Queries für das aktuelle Token berechnet, um diese mit dem bestehenden Cache abzugleichen. Das bedeutet, die bisherigen Keys und Values werden nicht neu berechnet, sondern aus dem Speicher abgerufen.
Die praktische Implementierung einer solchen KV-Cache-Lösung lässt sich am Beispiel einer offen zugänglichen und didaktisch gut nachvollziehbaren Python-Codierung mit PyTorch illustrieren. Zunächst werden in der MultiHeadAttention-Klasse Pufferspeicher (Buffer) für die Schlüssel- und Wert-Vektoren eingeführt. Diese Puffer sind nicht persistent, das heißt, sie werden nicht beim Speichern des Modells berücksichtigt, sondern existieren nur zur Laufzeit während der Inferenz. Mit dem Attribut self.register_buffer werden dabei zwei neue Variablen angelegt, die zunächst leer sind.
Im Forward-Durchlauf der Attention wird dann unterschieden, ob die Funktion zum ersten Mal ausgeführt wird oder ob bereits Daten im Cache vorhanden sind. Beim ersten Durchlauf werden die neuen Schlüssel- und Wert-Vektoren normal berechnet und direkt im Cache gespeichert. Bei allen folgenden Durchläufen werden statt der kompletten Neuberechnung die schon gespeicherten Vektoren aus dem Cache ausgelesen und nur die für den aktuellen Token neuen Vektoren angehängt. So wächst der Cache Schritt für Schritt mit jedem neu generierten Token und ermöglicht eine effiziente Wiederverwendung der Daten. Ein weiterer wichtiger Aspekt im Umgang mit dem KV Cache ist die Wiederverwendung und mögliche Rücksetzung des Cache-Speichers.
Für die Generierung mehrerer unabhängiger Textsequenzen muss der Cache nach jeder vollendeten Sequenz geleert werden, um kein Altmaterial in die nächste Erzeugung einzuschleppen. Hierfür wird eine spezielle Reset-Funktion implementiert, die beide Cache-Bühler leert und den Zähler der verarbeiteten Tokens auf Null zurücksetzt. Auf Modell- oder Transformer-Block-Ebene sind diese Methoden entscheidend, um korrekte und konsistente Ergebnisse bei mehreren Generationsaufrufen zu garantieren. Die Verwaltung des Positionszählers ist neben dem Speichern der Keys und Values ein weiterer Kernpunkt in der KV Cache-Implementierung. Während der Inferenz muss das Modell wissen, welche Position die neuen Tokens einnehmen, um deren Einbettungen korrekt zu adressieren.
Ein simulierter Zähler auf Modellebene verfolgt deshalb die Anzahl der bereits berechneten Tokens, sodass in jedem Inferenzschritt die neu erzeugten Token die richtige Offset-Position im Cache erhalten. Das verhindert Überschneidungen oder Fehler bei der Synchronisation der gespeicherten Vektoren und der tatsächlichen Eingabesequenzen. In der Anwendung des Modells bei der Textgenerierung zeigt sich der volle Nutzen des KV Cache. Während bei einer Implementierung ohne Cache in jedem Schritt die gesamte Eingabesequenz erneut durch das Netz geschickt wird, kann mit Cache in jedem Generationsschritt nur noch der eben erzeugte Token als Input übergeben werden. Dadurch verringert sich der Durchlauf im Netzwerk drastisch, was zu deutlich schnelleren Ergebnissen führt.
Ein Beispiel zeigt, dass bei einem 124-Millionen-Parameter-Modell und der Generierung von 200 neuen Tokens auf einem modernen Prozessor eine etwa fünffache Geschwindigkeitssteigerung durch die KV-Cache-Technik erreicht wurde. Trotz dieser Vorteile ist der Einsatz eines KV Caches nicht frei von Kompromissen. Die wichtigste Einschränkung ist die erhöhte Speicherauslastung. Da für jeden Token sowohl der Schlüssel- als auch der Wertvektor gespeichert werden, wächst die Speicherbelegung linear mit der Tokenanzahl. Vor allem in Kombination mit sehr großen Modellen und extrem langen Kontexten kann dies auf GPUs zu einem Engpass werden.
Deswegen ist eine wohlüberlegte Speicherverwaltung und gegebenenfalls eine Begrenzung der Cache-Größe entscheidend. Bei Open-Source- und Industrielösungen finden sich deshalb meist hybride Konzepte, die sowohl Speicherverbrauch als auch Geschwindigkeit optimieren. Ein weiterer praktischer Tipp für Anwender und Entwickler ist die sogenannte Memory-Preallocation. Anstatt kontinuierlich neue Tensoren anzufügen, was häufige Speicherallokationen und Fragmentierung nach sich zieht, wird eine ausreichend große Speicherzuordnung vorab vorgenommen. Neu berechnete Schlüssel- und Wert-Matrizen werden dann stets in vorher reservierte Bereiche geschrieben, was Speicherfragmentierung verhindert und das Tempo weiter erhöht.
Alternativ dazu kann eine Sliding-Window-Technik implementiert werden, bei der nur die letzten X Tokens im Cache gehalten werden, um den Speicherbedarf konstant zu halten und weiterhin von der Cache-Geschwindigkeit zu profitieren. Die vorgestellte KV Cache-Implementierung hat auch in internationalen Modellen wie Qwen3 und Llama 3 Einzug gehalten, wobei dort durch die riesigen Kontextgrößen von mehreren Zehntausend Tokens die Speicherbelastung noch viel bedeutsamer wird. Dort wird teils mit aufwändigeren Techniken gearbeitet, wie dem Auslagern des Caches aus dem eigentlichen Modell oder dem Einsatz von JIT-Compiler-Optimierungen, um ein Gleichgewicht zwischen Geschwindigkeit und Speicherverbrauch herzustellen. Auch wenn die technischen Details und Programmierbeispiele sehr spezifisch sind, lässt sich die zugrundeliegende Idee des KV Caches auf viele Systeme übertragen, die sequenzielle Inferenz mit Transformer-basierten Modellen realisieren wollen. Der Schlüssel zum Erfolg besteht darin, eine möglichst effiziente Balance zu finden zwischen Computergeschwindigkeit und Ressourcenverbrauch, ohne die Qualität der erzeugten Texte zu beeinträchtigen.
Abschließend lässt sich festhalten, dass der KV Cache ein essentieller Baustein moderner, schneller und effizienter Textgenerationssysteme ist. Die Implementierung ist vergleichsweise zugänglich und lehrreich, stellt aber auch die Basis für komplexere, produktionsfähige Lösungen dar. Praktische Optimierungen wie Speicher-Preallocation und Sliding Windows sorgen dafür, dass das System auch bei wachsender Sequenzlänge und Modellgröße performant bleibt. Für Forschende, Entwickler und KI-Enthusiasten ist das Verständnis und die praktische Anwendung des KV Caches daher eine wertvolle Fähigkeit bei der Arbeit mit großen Sprachmodellen.








