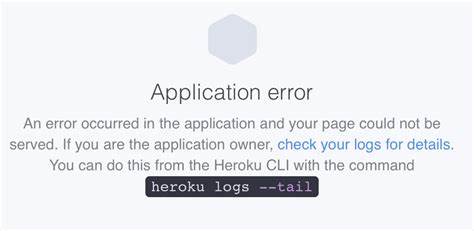
Die GitHub API ist für viele Entwickler und Unternehmen ein unverzichtbares Werkzeug zur Automatisierung von Prozessen und zur Verwaltung von Projekten. Wenn die API ausfällt, kann das erhebliche Störungen im Arbeitsablauf verursachen. Vor einigen Wochen kam es zu einem bemerkenswerten Ausfall der GitHub API, der die Nutzer weltweit vor Herausforderungen stellte. In diesem Beitrag wird untersucht, was während dieses Ausfalls geschah, welche Auswirkungen auf Entwickler und ihre Projekte entstanden sind, sowie welche Lösungen möglich sind, um derartige Situationen besser zu bewältigen. Die Bedeutung der GitHub API erklärt GitHub hat sich längst als die führende Plattform für Versionskontrolle und kollaborative Softwareentwicklung etabliert.
Die API von GitHub ermöglicht es, die Funktionen der Plattform programmgesteuert zu nutzen. Sie bildet die Schnittstelle zwischen externen Anwendungen, Automatisierungslösungen und GitHub selbst. Entwickler verwenden die API, um Issues, Pull Requests, Repository-Einstellungen und vieles mehr zu verwalten. Ausfallzeiten beeinträchtigen daher nicht nur manuelle Nutzeraktionen, sondern auch automatisierte Prozesse und Integrationen. Wie kam es zum Ausfall der GitHub API? Der API-Ausfall wurde zunächst durch vermehrte Fehlermeldungen beim Zugriff auf den GraphQL-Endpunkt festgestellt.
Die API, insbesondere die GraphQL-Schnittstelle unter https://github.com/_graphql, reagierte nicht mehr oder lieferte fehlerhafte Antworten. Parallel dazu war auch die Support-Ticket-Oberfläche unter https://support.github.com/ betroffen, die häufig 500er Serverfehler zurückgab.
Nutzer konnten Bug-Tickets nicht eröffnen oder bearbeiten. Darüber hinaus konnten keine Pull-Requests gemergt und keine GitHub Actions-Workflows ausgeführt werden. Die Auswirkungen auf den Entwickleralltag Für Entwicklerteams hatte der Ausfall weitreichende Konsequenzen. Zahlreiche Workflows innerhalb von Continuous Integration und Continuous Deployment (CI/CD) waren blockiert, was zu Verzögerungen bei der Bereitstellung von Softwareversionen und Updates führte. Das Merge-Verbot für Pull-Requests bedeutete für viele Teams, dass wichtige Änderungen nicht mehr in den Hauptzweig integriert werden konnten.
Die fehlende Möglichkeit, über die API Issues zu aktualisieren oder automatisierte Bots einzusetzen, führte zu einer erhöhten manuellen Arbeitsbelastung und Frustration im Team. Diese Unterbrechung traf Unternehmen verschiedener Größenordnungen, von Einzelentwicklern bis hin zu großen Konzernen. Da viele Organisationen auf GitHub als Herzstück ihrer Infrastruktur setzen, wurden viele Geschäftsprozesse unmittelbar beeinträchtigt. Analyse der Ursache und technische Hintergründe Die genaue Ursache des Ausfalls wurde von GitHub in den Folgewochen analysiert und veröffentlicht. Sie wiesen darauf hin, dass der komplexe GraphQL-Endpunkt besonders anfällig für Überlastungen ist, da er große Mengen an Verbindungsanfragen und Anfragen mit komplizierten Abfragen verarbeitet.
Zudem können Fehler innerhalb des Backends, wie Fehler in der Lastverteilung oder in der Verbindung zu Datenbanken, zu solchen Ausfällen führen. Die fehlerhaften 500er Antworten auf Support-System-Anfragen deuten auf Serverfehler hin, welche die Stabilität und Verfügbarkeit beeinflussten. GitHub hat betont, dass einige der betroffenen Dienste eng miteinander verzahnt sind, was den Ausfall mehrerer Komponenten gleichzeitig erklären kann. Ein solcher Dominoeffekt erschwert die schnelle Lokalisierung und Behebung des Problems. Warum ist die GitHub API so wichtig geworden? Immer mehr Entwickler automatisieren ihre Arbeitsabläufe und verlassen sich auf APIs, um repetitive Aufgaben zu erleichtern.
Die GitHub API ist zunehmend integraler Bestandteil von DevOps-Strategien, Continuous Integration und Continuous Deployment sowie von ChatOps-Workflows. Tools und Bots greifen kontinuierlich auf die API zu, um Statusberichte zu erstellen, Änderungen zu überwachen oder Workflows selbst zu steuern. Das zeigt sich auch daran, dass der Ausfall der GitHub API viele weitere Dienste und Integrationen tangiert. Wenn die API nicht verfügbar ist, leidet nicht nur die Plattform selbst, sondern auch viele Drittanbieter-Anwendungen, die darauf aufbauen. Wie reagieren Entwickler auf einen API-Ausfall? Das beste Mittel gegen Störungen ist eine gute Vorbereitung.
Entwickler können Systeme so gestalten, dass sie auch bei einem temporären Ausfall der GitHub API weiterhin funktionsfähig bleiben oder zumindest den Schaden minimieren. Dazu gehört die Implementierung von Fallback-Mechanismen, das Caching von notwendigen Daten oder auch das Verwenden von Webhooks als Alternative. Im Fall des Ausfalls wurde für viele Teams klar, wie wichtig eine transparente Statuskommunikation seitens GitHub ist. Die GitHub Status-Seite auf https://www.githubstatus.
com/ spielte eine zentrale Rolle bei der Information der Nutzer. Eine ständige Überwachung der Plattform-Statusseiten und das Einrichten eigener Warnmeldungen kann Entwicklern helfen, frühzeitig auf Probleme zu reagieren. Praktische Tipps für den Umgang mit API-Ausfällen Wer auf die GitHub API angewiesen ist, sollte Maßnahmen treffen, die Ausfallzeiten möglichst abzufedern. Dazu zählt, regelmäßig die Dokumentation und Updates von GitHub zu verfolgen, um über geplante Wartungen oder Änderungen informiert zu sein. Zudem können Entwickler die Nutzung der API durch Rate Limiting und effiziente Abfragen optimieren, um eine Überlastung der Endpunkte zu vermeiden.
Backup-Strategien spielen ebenfalls eine wichtige Rolle. Während ein kompletter Backup des gesamten Repository-Datenbestands aufwendig sein kann, können wichtige Issue-Daten oder Projektinformationen lokal gesichert werden. Auch die Nutzung von Alternativ-Repositories oder das Verwalten von kritischen Projektdaten außerhalb von GitHub kann als Notfallplan dienen. Die Rolle von GitHub Copilot und anderen erweiterten Features Im Zusammenhang mit den Ausfällen wurde ebenfalls die Rolle von GitHub Copilot diskutiert. Einige Dienste, inklusiver der automatisierten Workflows, hängen stark von verknüpften Features ab.
Die starke Integration von APIs, KI-basierten Tools und Automatisierungen erhöht einerseits die Effektivität, birgt andererseits jedoch auch das Risiko, dass Fehler in einem Teil der Infrastruktur große Teile des Ökosystems beeinflussen. Eine sorgfältige Evaluierung neuer Features und deren Einfluss auf bestehende Infrastrukturkomponenten ist daher ratsam, besonders für Unternehmen, die sich hochgradig auf diese Technologien stützen. Langfristige Konsequenzen für die Entwickler-Community Solche Ausfälle führen zu einer verstärkten Diskussion um Produktionssicherheit und Plattformunabhängigkeit. Viele Entwickler äußern Wünsche nach mehr Redundanz, lokalen Alternativen und offenen Standards, die die Abhängigkeit von einem Anbieter reduzieren könnten. Gleichzeitig wächst das Bewusstsein für die Risiken, die mit Cloud-basierten und stark vernetzten Lösungen einhergehen.
GitHub arbeitet kontinuierlich an der Verbesserung der Stabilität und der Skalierbarkeit seiner Dienste. Der jüngste Ausfall hat wichtige Erkenntnisse geliefert, die in zukünftige Architekturverbesserungen einfließen werden. Fazit Der Ausfall der GitHub API zeigte deutlich, wie zentral diese Infrastrukturkomponente für die globale Entwickler-Community geworden ist. Die Störung führte zu erheblichen Einschränkungen in der täglichen Arbeit von Entwicklern und hob die Bedeutung von Ausfallsicherheit, transparenter Kommunikation und Notfallstrategien hervor. Entwickler und Unternehmen sollten daraus Lehren ziehen, um künftige Störungen besser zu bewältigen und ihre Arbeitsabläufe resilienter zu gestalten.
Gleichzeitig belegt dieses Ereignis, dass auch die größten Plattformen mit Herausforderungen konfrontiert sind, was den Umgang mit Fehlern und Ausfällen umso wichtiger macht.