Die Fortschritte der Computer Vision und künstlichen Intelligenz verändern die Art und Weise, wie Maschinen ihre Umgebung wahrnehmen und darauf reagieren. Ein besonders vielversprechender Bereich ist die dreidimensionale (3D) Objekterkennung und Lokalisierung in realen Szenarien. Mit der zunehmenden Verfügbarkeit moderner Sensorik wie RGB-D Kameras werden dreidimensionale Punktwolken als Datenbasis immer wichtiger. Hier setzt Locate 3D an, eine innovative Methode zur Objekterkennung und Lokalisierung, die auf selbstüberwachtem Lernen basiert und neue Maßstäbe in puncto Genauigkeit und Anwendbarkeit setzt. Die Technologie eröffnet zahlreiche Möglichkeiten von der Robotik über Augmented Reality bis hin zur fortschrittlichen Mensch-Maschine-Interaktion.
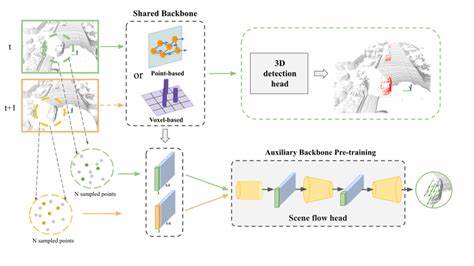
Locate 3D ist ein Modell, das gezielt dafür entwickelt wurde, Objekte in komplexen 3D-Szenen anhand natürlicher Sprachreferenzen wie „der kleine Couchtisch zwischen dem Sofa und der Lampe“ präzise zu lokalisieren. Im Gegensatz zu vielen bisherigen Ansätzen arbeitet Locate 3D direkt auf den sensorgenerierten Datenströmen, konkreter auf RGB-D Bildsequenzen mit exakter Positionsinformation. Diese direkte Verarbeitung von Sensordaten erlaubt einen besonders realitätsnahen Einsatz, etwa auf robotischen Plattformen oder in AR-Geräten, die in Echtzeit mit ihrer Umgebung interagieren müssen. Ein zentrales Element des Ansatzes ist ein neuartiger Algorithmus namens 3D-JEPA, welcher auf selbstüberwachtem Lernen beruht. 3D-JEPA nutzt Punktwolken aus Sensoren, die durch 2D-Foundation-Modelle wie CLIP und DINO vorgängig angereichert und featurisiert werden.
Durch die Anwendung einer maskierten Vorhersageaufgabe im latenten Raum wird das Modell darauf trainiert, kontextualisierte und reichhaltige Darstellungen der 3D-Szene zu erlernen, ohne dass große Mengen an manuell gelabelten Daten benötigt werden. Die selbstüberwachte Vortrainingsphase ist damit besonders effizient und allgemein. Im Anschluss an das selbstüberwachte Training wird der 3D-JEPA Encoder zusammen mit einem sprachbedingt konditionierten Decoder feinjustiert. Hierbei lernt das Modell, sowohl präzise dreidimensionale Masken als auch Bounding-Boxen für die angefragten Objekte in der Szene zu generieren. Die Kombination von selbsterschlossenen, kontextuellen Features mit Sprachbefehlen erlaubt eine robuste, flexible und genaue Objektsuche, die auf verschiedenste Szenarien anwendbar ist.
Zusätzlich zur technischen Innovation stellt Locate 3D mit dem Locate 3D Dataset eine umfangreiche Datenbasis zur Verfügung, die mit über 130.000 Annotationen eine breite Vielfalt an 3D-Referenzierungsfällen abdeckt. Das Dataset umfasst mehrere Erfassungs-Setups und ermöglicht somit nicht nur die Validierung und Optimierung von Modellen, sondern auch ein tiefgreifendes Verständnis der Generalisierungsfähigkeit im Bereich der 3D-Objektlokalisierung. Die große Anzahl der gelabelten Szenen schafft eine wertvolle Grundlage für weiterführende Forschung und Anwendungsentwicklung. Die Bedeutung der selbstüberwachten Lernstrategie im Kontext von Locate 3D kann nicht hoch genug eingeschätzt werden.
Traditionelle, überwachte Lernmethoden sind stark abhängig von großen Mengen an annotierten Trainingsdaten, deren Erstellung sehr kosten- und zeitaufwendig ist. Durch den Fokus auf Masked Latent Prediction, die voraussetzt, dass das Modell fehlende Teile der Punktwolke anhand vorliegender kontextueller Informationen voraussagt, kann Locate 3D auf selbstlernende Weise wertvolle Features entwickeln. Diese Features fangen die Struktur, Beziehungen und Eigenschaften von Objekten in der 3D-Umgebung besonders gut ein und bilden die Grundlage für die nachfolgende Sprach-gestützte Lokalisierung. Im praktischen Einsatz ergeben sich aus Locate 3D vielseitige Anwendungsmöglichkeiten. Insbesondere in der Robotik kann das Modell Roboterarm-Systemen oder mobilen Robotern helfen, Objekte sicher zu erkennen und präzise zu manipulieren.
Auch in der Augmented Reality profitieren Geräte davon, dass reale Objekte in der Szene zuverlässig erkannt, eingegrenzt und mit digitalen Informationen verknüpft werden können. Eine genaue Lokalisierung anhand von natürlichsprachlichen Anfragen ermöglicht intuitive Interaktionen zwischen Mensch und Maschine, welche insbesondere in Service-Robotern oder assistiven Technologien eine wichtige Rolle spielen. Der Bezug zu sogenannten Foundation-Modellen wie CLIP und DINO, die ursprünglich aus der Verarbeitung von 2D-Bilddaten stammen, ist ein weiterer spannender Aspekt von Locate 3D. Durch die Integration dieser etablierten, leistungsfähigen visuellen Modelle in den 3D-Kontext erhält Locate 3D eine starke Vorverarbeitungsebene, die visuelle Semantik aus der 2D-Welt in die 3D-Welt überträgt und damit die semantische Erkennung erheblich verbessert. Diese Verbindung zwischen 2D-Basiswissen und 3D-Wahrnehmung ist ein innovatives Konzept, welches die Grenzen konventioneller rein 3D-basierter Modelle durchbricht.
In wissenschaftlicher Hinsicht zeigt Locate 3D auf mehreren Benchmarks neue Bestleistungen, was die Genauigkeit und Robustheit der Objektlokalisierung betrifft. Gleichwohl demonstriert es eine sehr gute Übertragbarkeit auf neue, unbekannte Szenen und Umgebungen, was in der Forschung oft eine große Herausforderung darstellt. Somit hat Locate 3D nicht nur das Potenzial, als State-of-the-Art Lösung in einem schnell wachsenden Bereich zu gelten, sondern auch als Grundlage für weitere Innovationen dienen. Neben den offensichtlichen technischen Vorteilen leistet Locate 3D auch einen wichtigen Beitrag zur Verbesserung des gesamten Forschungsökosystems im Bereich der 3D Visualisierung und Sprachverarbeitung. Meta AI stellt die Modelle, das Dataset sowie Forschungsarbeiten umfassend offen zugänglich zur Verfügung, was eine breite Community dazu motiviert, auf diesem Fortschritt aufzubauen und neue Anwendungen zu erschaffen.