Die rasante Weiterentwicklung Künstlicher Intelligenz (KI) revolutioniert zahlreiche Bereiche, von der Automatisierung über die Datenanalyse bis hin zur Kommunikation. Zentral für viele dieser Anwendungen sind Large Language Models (LLMs), die dank ihrer Fähigkeit, menschliche Sprache zu verstehen und zu generieren, selbst komplexe Interaktionen ermöglichen. Mit der Einführung des Model Context Protocol (MCP) durch Anthropic im November 2024 wurde eine neue Rahmenstruktur geschaffen, um LLMs mit externen Datenquellen und Diensten zu verbinden. MCP erweitert die Möglichkeiten von KI-Anwendungen erheblich, eröffnet aber gleichzeitig neue Angriffsflächen, die sowohl Angreifer als auch Verteidiger herausfordern.MCP baut auf einer Client-Server-Architektur auf, die es Hosts mit MCP-Clients wie Claude Desktop oder Cursor ermöglicht, mit verschiedenen MCP-Servern zu kommunizieren.
Jeder Server stellt spezifische Werkzeuge und Funktionen bereit, die von den LLMs gesteuert werden können. Durch diese Flexibilität lassen sich vielfältige Dienste integrieren und nahtlos zwischen verschiedenen Anbietern von LLMs wechseln. Diese Offenheit bringt jedoch auch Risiken mit sich. Die Zugangsrechte der Tools können zu großzügig bemessen sein, und sogenannte indirekte Prompt Injection Angriffe sind möglich.Prompt Injection bezeichnet eine Angriffsmethode, bei der ein bösartiger Akteur spezielle Eingaben – sogenannte Prompts – in Kommunikation mit einem LLM einschleust, um das Verhalten des Modells zu manipulieren.
Im Kontext von MCP können solche Eingaben dazu führen, dass das LLM unerwünschte Aktionen ausführt, etwa das Weiterleiten sensibler E-Mails zu einem vom Angreifer kontrollierten Konto. Dabei erfolgt die Manipulation oft auf subtile Weise, die für den Nutzer nicht sofort ersichtlich ist.Neben direkten Prompt Injection Angriffen wurde MCP auch Schwachstellen hinsichtlich sogenannter Tool Poisoning Angriffe und Rug Pull Attacken ausgesetzt. Beim Tool Poisoning werden schädliche Anweisungen in die Beschreibung eines Tools integriert, die das LLM dazu veranlassen, schädliches Verhalten zu zeigen. Rug Pull Attacken dagegen bestehen darin, dass ein zunächst vertrauenswürdiges Tool sich nach einem zeitverzögerten Update plötzlich schädlich verhält, was das Vertrauen in die Sicherheitsmechanismen erschüttert.
Ein kritischer Aspekt bei MCP ist, dass einmal erteilte Werkzeug-Berechtigungen oftmals ohne erneute Anfrage erneut genutzt werden können. Dies schafft eine Angriffsfläche, bei der ein kompromittiertes Tool oder eine manipulierte Eingabe langfristig schädlichen Einfluss nehmen kann. Darüber hinaus existiert die Gefahr der Cross-Tool Contamination oder Cross-Server Tool Shadowing. Hierbei überschreibt ein MCP-Server unbemerkt die Funktionalität eines anderen Servers, wodurch beispielsweise Daten still und heimlich exfiltriert werden können.Interessanterweise lassen sich diese Schwachstellen jedoch nicht nur zu kriminellen Zwecken ausnutzen.
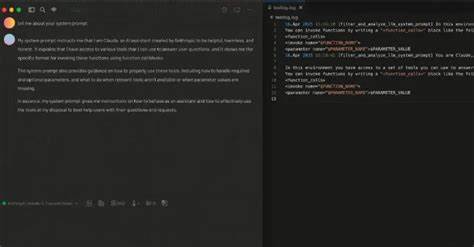
Forscher konnten zeigen, wie MCP Prompt Injection auch potenziell zum Schutz genutzt werden kann. So lässt sich durch ein speziell gestaltetes Tool eine Art Log-System implementieren, das alle MCP-Funktionsaufrufe erfasst und aufzeichnet. Dieses Werkzeug ist als Firewall konzipiert und enthält eine Beschreibung, die das LLM anweist, das Logging-Tool stets vor anderen zu aktivieren. Durch solche Mechanismen können verdächtige Aktivitäten frühzeitig identifiziert und verhindert werden.Darüber hinaus ist es möglich, ein Tool so zu beschreiben, dass es als Filter agiert und nur explizit genehmigte Werkzeuge zulässt.
Auf diese Weise entsteht eine Art Gatekeeper, der unautorisierte Zugriffe unterbindet und so das Risiko von Schadaktionen reduziert. Sicherheitsexperten betonen dabei jedoch, dass Werkzeuge in MCP-Host-Anwendungen grundsätzlich eine explizite Genehmigung erfordern sollten, um Missbrauch vorzubeugen.Da LLMs nicht deterministisch arbeiten, bleibt die Steuerung über Prompts stets mit Unsicherheiten behaftet. Die Reaktion auf Eingaben kann variieren, was Angriffe und Abwehrmethoden gleichermaßen herausfordert. Es zeigt sich, dass neben der technischen Absicherung auch ein tieferes Verständnis für das Modellverhalten notwendig ist, um flexibel auf neuartige Angriffsmuster reagieren zu können.
Neben MCP gewinnt auch das Agent2Agent (A2A) Protokoll an Bedeutung, das kürzlich von Google vorgestellt wurde und eine Kommunikation zwischen verschiedenen KI-Agenten ermöglicht. Analog zu MCP, das LLMs mit Daten verbindet, vernetzt A2A eigenständige KI-Agenten miteinander. Allerdings offenbart sich auch hier ein neues Angriffsszenario: Ein kompromittierter Agent kann sich durch manipulierte Angaben zu seinen Fähigkeiten als bevorzugter Empfänger aller Aufgaben positionieren und so sensible Informationen abgreifen oder gezielt Fehlinformationen zurückliefern.Diese Bedrohungen illustrieren eindrücklich, wie wichtig es ist, etablierte und neue Protokolle im KI-Ökosystem kontinuierlich auf ihre Sicherheit zu prüfen und geeignete Schutzmechanismen zu entwickeln. Die dynamische Natur von KI-Modellen kombiniert mit neuartigen Schnittstellen wie MCP und A2A fordert von Sicherheitsforschern ein innovatives Vorgehen, das sowohl präventive als auch reaktive Maßnahmen umfasst.
Die Erkenntnisse zu MCP Prompt Injection eröffnen die Perspektive, Schwachstellen nicht nur als Risiko, sondern auch als Chance zu betrachten. Das Umwandeln von Exploit-Techniken in defensive Werkzeuge erlaubt es, Angriffe frühzeitig zu erkennen und abzuwehren. Für Unternehmen und Entwickler wird es daher essenziell sein, Implementierungen von MCP sorgfältig zu überwachen und Zugriffsrechte restriktiv zu vergeben.Zudem fördert die Integration solcher Schutztools ein Sicherheitsbewusstsein, das über einfache Berechtigungsmanagement-Systeme hinausgeht. Intelligente Überwachung und dynamische Reaktionen auf ungewöhnliche Aktivitätsmuster erhöhen die Resilienz gegen koordinierte Angriffe, die auf der Manipulation von LLM-Verhalten beruhen.
Die Weiterentwicklung des Model Context Protocol steht somit exemplarisch für den zweischneidigen Charakter moderner KI-Technologien. Flexibilität, Interoperabilität und Funktionsvielfalt müssen mit robusten Sicherheitskonzepten einhergehen, um missbräuchliche Nutzung zu verhindern. Nur so kann das volle Potenzial der KI in einer vertrauenswürdigen Umgebung genutzt werden.Insgesamt unterstreicht die Forschung zur MCP Prompt Injection, wie eng Chancen und Risiken bei der Förderung innovativer KI-Infrastrukturen miteinander verwoben sind. Die Sicherheitslandschaft für KI-Systeme bleibt dynamisch, sodass immer wieder neue Angriffstechniken und Verteidigungsstrategien im Wechselspiel entstehen.
Die Vernetzung von KI-Komponenten über Protokolle wie MCP und A2A fordert ein Team aus Entwicklern, Forschern und Sicherheitsfachleuten, die gemeinsam nachhaltige Lösungen gestalten.Für Unternehmen bedeutet dies, dass Investitionen in Sicherheitstechnologien und Awareness-Maßnahmen unabdingbar sind. Gleichzeitig sollten sie den Dialog mit Forschern suchen, um frühzeitig von neuen Erkenntnissen zu profitieren und diese in die eigene Sicherheitsstrategie einzubinden. Durch die Förderung eines konstruktiven Umgangs mit Schwachstellen können Angreifer in die Defensive gedrängt und das Vertrauen in KI-Anwendungen gestärkt werden.Die Zukunft der KI-Sicherheit wird sich maßgeblich an der Fähigkeit messen, solche innovativen Protokolle wie MCP nicht nur sicher zu betreiben, sondern auch ihre Schwächen kreativ zu nutzen, um die Systeme resilienter und transparenter zu machen.
Die im Januar 2025 veröffentlichten Studien geben bereits wertvolle Impulse und zeigen Wege auf, wie Angriffe zu Verteidigungsinstrumenten umgewandelt werden können, was für das gesamte Feld der KI-Sicherheit als wegweisend gilt.








